家用电器用户行为分析与事件识别代码详解+修改后运行无误的代码
运行环境:
ubuntu16.04 64位
pycharm python3.5.2
相关软件列表:
cycler (0.10.0)
graphviz (0.7.1)
h5py (2.7.0)
Keras (2.0.4)
matplotlib (2.0.2)
numpy (1.12.1)
pandas (0.20.1)
pip (8.1.1)
protobuf (3.3.0)
pydot (1.2.3)
pyparsing (2.2.0)
python-dateutil (2.6.0)
pytz (2017.2)
PyYAML (3.12)
scipy (0.19.0)
setuptools (20.10.1)
six (1.10.0)
tensorflow (1.1.0)
Theano (0.9.0)
Werkzeug (0.12.2)
wheel (0.29.0)
xlrd (1.0.0)
xlwt (1.2.0)
-------------------------------------------------------------------下面是10-1-----------------------------------------------------------------------------------
#-*- coding: utf-8 -*-
#用水事件划分
import pandas as pd
threshold = pd.Timedelta('4 min') #阈值为分钟
inputfile = '../data/water_heater.xls' #输入数据路径,需要使用Excel格式
outputfile = '../tmp/dividsequence.xls' #输出数据路径,需要使用Excel格式
data = pd.read_excel(inputfile)
data[u'发生时间'] = pd.to_datetime(data[u'发生时间'], format = '%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] #只要流量大于0的记录
d = data[u'发生时间'].diff() > threshold #相邻时间作差分,比较是否大于阈值
data[u'事件编号'] = d.cumsum() + 1 #通过累积求和的方式为事件编号
data.to_excel(outputfile)这个代码什么意思呢?
也就是说,根据水流量和时间间隔的频率来判断用户第几次用水,举个通俗的例子,就说洗菜把。
洗一颗青菜,洗一个叶子时需要用水对吧,但是呢,我把青菜的瓣儿一个个扳下来的这会儿功夫是不需要用水的对吧?
在扳的时候我停掉水龙头,拌青菜完了之后开始洗了,就需要用水,然后洗下一个青菜,再停水。
那么整个洗菜的过程中我有停水,也有用水,整个过程视为一次用水事件。
P205中表格的数据解释:
可以看到
20141019172323
与
20141019172325
这两个发生事件只相隔了2秒,水流量反而减少了,这个可以理解为水龙头开大开小导致。
-------------------------------------------------------------------下面是10-2-----------------------------------------------------------------------------------
#-*- coding: utf-8 -*-
#阈值寻优
import numpy as np
import pandas as pd
inputfile = '../data/water_heater.xls' #输入数据路径,需要使用Excel格式
n = 4 #使用以后四个点的平均斜率
threshold = pd.Timedelta(minutes = 5) #专家阈值,这句话就是把数据格式变化了下,没有对数据进行处理
print("threshold=",threshold)
data = pd.read_excel(inputfile)
data[u'发生时间'] = pd.to_datetime(data[u'发生时间'], format = '%Y%m%d%H%M%S')
data = data[data[u'水流量'] > 0] #只要流量大于0的记录
def event_num(ts):#这里是函数定义,不是在执行,这里的ts是threshold
d = data[u'发生时间'].diff() > ts #相邻时间作差分,比较是否大于阈值
return d.sum() + 1 #这样直接返回事件数
################以上代码和12-1类似################
dt = [pd.Timedelta(minutes = i) for i in np.arange(1, 9, 0.25)]#这里用到的语法是列表推导,也叫作列表解析
#这里arange用于创建等差数组,这里的数据最终会变化成时间数据格式,也就是说,这里的0.25代表每分钟的四分之一,也就是15秒,按照15秒为步长,进行取数据
#上面一句话的意思其实就是某某函数在某定义域的值的序列☆☆☆☆☆☆
h = pd.DataFrame(dt, columns = [u'阈值']) #定义阈值列
h[u'事件数'] = h[u'阈值'].apply(event_num) #计算每个阈值对应的事件数,调用了上面的event_num函数
#上面这句话的意思是在实现图10-4,通过横轴的阈值,来计算数轴的事件数
h[u'斜率'] = h[u'事件数'].diff()/0.25 #计算每两个相邻点对应的斜率
print("h[u'斜率'].abs()=",h[u'斜率'].abs())
h[u'斜率指标'] = pd.rolling_mean(h[u'斜率'].abs(), n) #采用后n个的斜率绝对值平均作为斜率指标
print("h[u'斜率指标']=",h[u'斜率指标'])
#以上的计算: h[u'斜率']=>h[u'斜率指标']
print("--------------------------------------------------------------------------------")
ts = h[u'阈值'][h[u'斜率指标'].idxmin() - n]#
#这里ts得到的是4min,利用修正过后的索引对h[u'阈值']取值
#idxmin()返回数组中最小值的索引
#注:用idxmin返回最小值的Index,由于rolling_mean()自动计算的是前n个斜率的绝对值平均(根据下方列表可以通透地理解这个意思)
#所以结果要进行平移(-n)
#这里的平移其实是不太合适的,我认为平移n/2更加合理,因为一个点的斜率一般是取前后n/2个点进行平均计算后所得值是更为合理的。
if ts > threshold:#这里的意思是,如果上面计算得到的ts小鱼上面设定的专家阈值,就以ts为准,否则就降低为4.
ts = pd.Timedelta(minutes = 4)#决定的最终的阈值
print("-----------------------------")
print("ts=",ts)
#所以这个代码的终极目的就是为了获得斜率最低点的起始点,这样有利于把前一件用水事件和后一件用水事件进行合理的区分。
这个代码的意思就是为了寻找书本p211的图10-4的斜率为零的线段的起始点。
当线段下降很陡的时候,说明线段中的这几个点很可能属于同一个事件,所以化为一个事件。
同样的,当线段很平坦,阈值的递增对事件总数影响不大时,那么曲线上的多个点代表的事件总是说明分类比较合理,也就是说此时每个用水事件之间相隔时间间隔较大。
-------------------------------------------------------------------下面是10-3-----------------------------------------------------------------------------------
接下来这个代码就是数据的输入输出之间进行模型训练了,书上的代码没办法直接运行,我进行了修改,如下:
#-*- coding: utf-8 -*-
#建立、训练多层神经网络,并完成模型的检验
from __future__ import print_function
import pandas as pd
from keras.utils.vis_utils import plot_model
inputfile1='../data/train_neural_network_data.xls' #训练数据
inputfile2='../data/test_neural_network_data.xls' #测试数据
testoutputfile = '../tmp/test_output_data.xls' #测试数据模型输出文件
data_train = pd.read_excel(inputfile1) #读入训练数据(由日志标记事件是否为洗浴)
data_test = pd.read_excel(inputfile2) #读入测试数据(由日志标记事件是否为洗浴)
y_train = data_train.iloc[:,4].as_matrix() #训练样本标签列
x_train = data_train.iloc[:,5:17].as_matrix() #训练样本特征
y_test = data_test.iloc[:,4].as_matrix() #测试样本标签列
x_test = data_test.iloc[:,5:17].as_matrix() #测试样本特征
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers import Dense, Activation
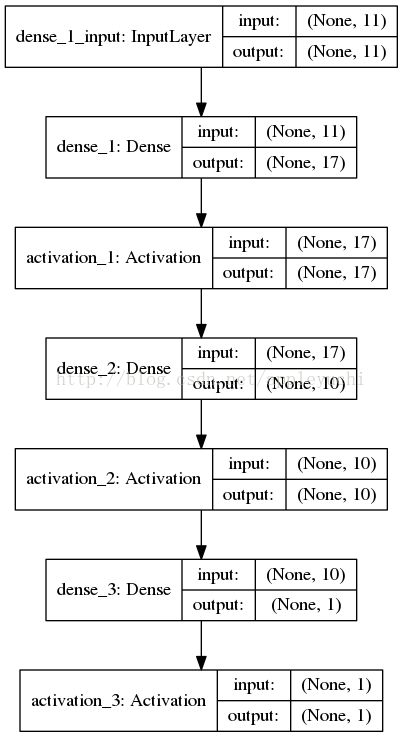
model = Sequential() #建立模型
model.add(Dense(output_dim=17,input_dim=11)) #添加输入层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(output_dim=10,input_dim=17)) #添加隐藏层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(input_dim=10,output_dim=1)) #添加隐藏层、输出层的连接
model.add(Activation('sigmoid')) #以sigmoid函数为激活函数
#编译模型,损失函数为binary_crossentropy,用adam法求解
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
model.fit(x_train, y_train, nb_epoch = 100, batch_size = 1) #训练模型
model.save_weights('../tmp/net.model') #保存模型参数
r = pd.DataFrame(model.predict_classes(x_test), columns = [u'预测结果'])
pd.concat([data_test.iloc[:,:5], r], axis = 1).to_excel(testoutputfile)
model.predict(x_test)
############自己添加的########################
plot_model(model, to_file='model.png', show_shapes=True)
代码运行结果为:
| 热水事件 | 起始数据编号 | 终止数据编号 | 开始时间(begin_time) | 根据日志判断是否为洗浴(1表示是,0表示否) | 预测结果 | |
| 0 | 1 | 73 | 336 | 2015-01-05 9:42:41' | 1 | 1 |
| 1 | 2 | 420 | 535 | '2015-01-05 18:05:28' | 1 | 1 |
| 2 | 3 | 538 | 706 | '2015-01-05 18:25:24' | 1 | 1 |
| 3 | 4 | 793 | 910 | '2015-01-05 20:00:42' | 1 | 1 |
| 4 | 5 | 935 | 1133 | '2015-01-05 20:15:13' | 1 | 1 |
| 5 | 6 | 1172 | 1274 | '2015-01-05 20:42:41' | 1 | 1 |
| 6 | 7 | 1641 | 1770 | '2015-01-06 08:08:26' | 0 | 0 |
| 7 | 8 | 2105 | 2280 | 2015-01-06 11:31:13' | 1 | 1 |
| 8 | 9 | 2290 | 2506 | '2015-01-06 17:08:35' | 1 | 1 |
| 9 | 10 | 2562 | 2708 | '2015-01-06 17:43:48' | 1 | 1 |
| 10 | 11 | 3141 | 3284 | '2015-01-07 10:01:57' | 0 | 1 |
| 11 | 12 | 3524 | 3655 | 2015-01-07 13:32:43' | 0 | 1 |
| 12 | 13 | 3659 | 3863 | '2015-01-07 17:48:22' | 1 | 1 |
| 13 | 14 | 3937 | 4125 | '2015-01-07 18:26:49' | 1 | 1 |
| 14 | 15 | 4145 | 4373 | '2015-01-07 18:46:07' | 1 | 1 |
| 15 | 16 | 4411 | 4538 | '2015-01-07 19:18:08' | 1 | 1 |
| 16 | 17 | 5700 | 5894 | 2015-01-08 7:08:43' | 0 | 1 |
| 17 | 18 | 5913 | 6178 | 2015-01-08 13:23:42' | 1 | 1 |
| 18 | 19 | 6238 | 6443 | 2015-01-08 18:06:47' | 1 | 1 |
| 19 | 20 | 6629 | 6696 | 2015-01-08 20:18:58' | 1 | 1 |
| 20 | 21 | 6713 | 6879 | 2015-01-08 20:32:16' | 1 | 1 |
注意每次预测结果都是不一样的,上面的预测结果准确度是80%,如果多训练几次会发现准确度在60%~80%之间,靠右两列数值不同时,则为判断错误,相同时,则为判断正确。
并且会出现随机报错,也就是说一次运行无报错,另外一次运行报错,属正常现象,因为每次训练都是局部最优解。
使用的神经网络模型为: