京东大数据平台进化之路

本文内容来自由msup主办的第七届TOP100summit大会。分享者王哲涵,时任京东离线平台研发团队负责人。2015年加入京东,于大数据平台研发部工作, 负责京东大数据平台的架构与研发工作。
导读
时下大数据技术趋于成熟与稳定的今天, hadoop相关服务也不再高高在上, 已是作为如同数据库般的作为基础软件设施提供计算与存储服务, 京东大数据平台从无到有, 从量到质, 从微创到革新经历五年的时间, 集群规模一步步由数百到数万规模的演化过程, 此次分享主要涵盖面对业务多元化发展, 京东大数据平台持续进化过程中遇到的问题与我们的解决方案。
如果按规模划分,京东大数据平台演进的几个重要节点分别是单集群规模达到1200台、3000台、5000台再到2018年的8000台。在这个过程,京东大数据团队优化了Yarn的调度性能,集群稳定性,计算资源分配并逐步完成存储和计算分离等工作。
在平台搭建上,中小企业在不具备专业研发团队的情况下,选择云提供商和开源社区的可能性更大,短期来看这会节省大量成本。但是,当集群增长到一定规模,使用云平台的成本就会相应升高。京东的离线大数据平台全部在本地实现,使用了不少开源组件也加入了新技术,但京东更加倾向于自我实现而非拿来主义。
所谓拿来主义,更多时候是指借用开源产品和社区的力量,但京东在代码修改上下了很大功夫,毕竟一些很小的改动可能为京东节省大量成本。对于组件选用,京东同样选择了Flink,Spark、Storm、Yarn、HDFS和HBase等常用组件,但是京东在代码层面进行了很多改动。以Yarn为例,Yarn在集群规模达到某个范围后,其性能是有问题的,京东对该问题进行了修复并持续弥补了其与K8S的差距。
虽然自研往往更容易达到想要的结果,但这一点并不适用于所有体量的公司。对于中小企业而言,一段代码优化带来的成本节省或许比消耗的人力成本更高,同时,中小企业也很难聚拢一批可修改源码级别的研发工程师,而这些在大公司眼中又不是问题了。毕竟,大公司聚集了中国绝大部分的优质研发人才,其一点小改动都可能带来巨大的性能提升或成本降低。
对于易用性、性能和成本之间的平衡,稳定性是首要考量目标,其次是性能。关于稳定性方面,京东到底做了些什么呢?
大纲
京东大数据平台的演化历程及方向
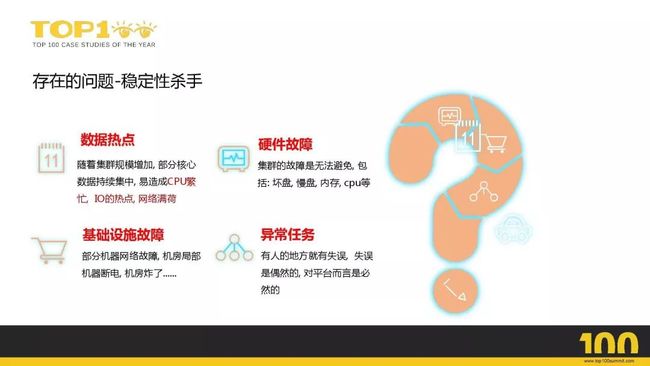
存在的问题
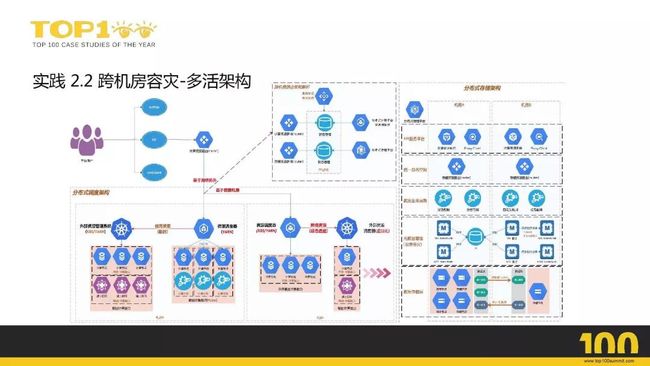
实践1.1-2.3
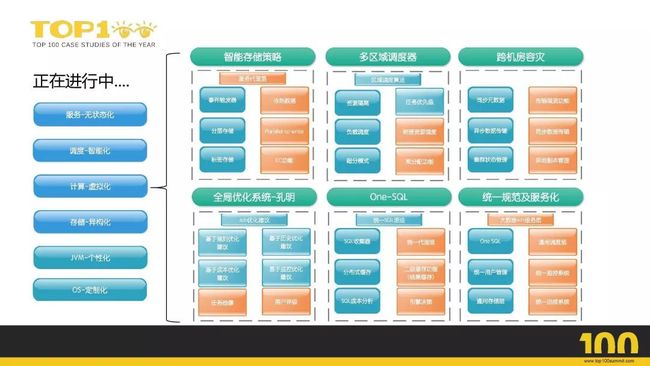
解决方法和实践小结
未来展望
部分PPT





完整版PPT请关注过往记忆大数据公众号,回复关键词「京东大数据」获得。
猜你喜欢
欢迎关注本公众号:iteblog_hadoop:
回复 spark_summit_201806 下载 Spark Summit North America 201806 全部PPT
回复 spark_summit_eu_2018 下载 Spark+AI Summit europe 2018 全部PPT
回复 HBase_book 下载 2018HBase技术总结 专刊
回复 all 获取本公众号所有资料
0、回复 电子书 获取 本站所有可下载的电子书
1、Elasticsearch如何做到亿级数据查询毫秒级返回?
2、京东HBase平台进化与演进
3、深入理解 Spark Delta Lake 的诞生及其工作原理
4、Apache Kafka 2.3 发布,新特性讲解
5、Hadoop 气数已尽?
6、一条 SQL 在 Apache Spark 之旅(下)
7、Kafka 是如何保证数据可靠性和一致性
8、Kylin 在小米大数据中的应用
9、Uber 大数据平台的演进(2014~2019)
10、图文了解 Kafka 的副本复制机制
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档: http://flink.iteblog.com 13、Carbondata 中文文档: http://carbondata.iteblog.com


