easyexcel的源码简单分析
文章目录
- 读的流程图
- 逻辑分析
- 1.EasyExcel
- 2.EasyExcelFactory
- ExcelReaderSheetBuilder
- ExcelReader
- ExcelAnalyserImpl
- XlsxSaxAnalyser
- DefaultAnalysisEventProcessor
- DemoDatalistener的invoke()方法被调用
- 返回到XlsxSaxAnalyser
- DefaultAnalysisEventProcessor的endSheet()
- DemoDataistener的doAfterAllAnalysed()
- 备注:官方给的详细参数介绍
- 关于常见类解析
- 读
- 注解
- 参数
- 通用参数
- ReadWorkbook(理解成excel对象)参数
- ReadSheet(就是excel的一个Sheet)参数
- 写
- 注解
- 参数
- 通用参数
- WriteWorkbook(理解成excel对象)参数
- WriteSheet(就是excel的一个Sheet)参数
- WriteTable(就把excel的一个Sheet,一块区域看一个table)参数
- 10M以上文件读取说明
- 如果对读取效率感觉还能接受,就用默认的,永久占用(单个excel读取整个过程)一般不会超过50M(大概率就30M),剩下临时的GC会很快回收
- 默认大文件处理
- 根据实际需求配置内存
- 如果最大文件条数也就十几二十万,然后excel也就是十几二十M,而且不会有很高的并发,并且内存也较大
- 对并发要求较高,而且都是经常有超级大文件
- 关于maxCacheActivateSize 也就是前面第二个参数的详细说明
- 如何判断 maxCacheActivateSize是否需要调整
最近公司用到easyexcel,跟了下源码,简单了解的部分流程。做一下笔记,方便以后查询。
本人主要根据官方给的最简单的read demo的调试下了:
读的流程图
流程图大体如下:

- 读的代码
ExcelReader excelReader = EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).build();
ReadSheet readSheet = EasyExcel.readSheet(0).build();
excelReader.read(readSheet);
// 这里千万别忘记关闭,读的时候会创建临时文件,到时磁盘会崩的
excelReader.finish();
逻辑分析
1.EasyExcel
easyexcel就是一个门面他是一个空的类,主要干活的是他的父类:
public class EasyExcel extends EasyExcelFactory {
}
2.EasyExcelFactory
作用: ExcelWriterBuilder 构建出一个 ReadWorkbook WriteWorkbook,可以理解成一个excel对象,一个excel只要构建.
继续看这行代码: EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).build();
进入read:
public static ExcelReaderBuilder read(String pathName, Class head, ReadListener readListener) {
ExcelReaderBuilder excelReaderBuilder = new ExcelReaderBuilder();
excelReaderBuilder.file(pathName);
if (head != null) {
excelReaderBuilder.head(head);
}
if (readListener != null) {
excelReaderBuilder.registerReadListener(readListener);
}
return excelReaderBuilder;
}
主要干了以下几件事:
- 1.初始化了
ExcelReaderBuilder这个对象: - 2将Demo.class对应的标题头信息放入
BasicParameter这个类相关子中。 - 3将Demo.controller对应的标题头信息放入
ReadBasicParameter这个类中。
ExcelReaderSheetBuilder
继续看这行代码:
ReadSheet readSheet = EasyExcel.readSheet(0).build();
干了这件事:
public static ExcelReaderSheetBuilder readSheet(Integer sheetNo) {
return readSheet(sheetNo, null);
}
ExcelWriterSheetBuilder 构建出一个 ReadSheet WriteSheet对象,可以理解成excel里面的一页,每一页都要构建一个.
ExcelReader
这个类是整个个读的入口类:
看这个代码
excelReader.read(readSheet);
源码调试:
public ExcelReader read(ReadSheet... readSheet) {
return read(Arrays.asList(readSheet));
}
继续点击read方法
public ExcelReader read(List<ReadSheet> readSheetList) {
excelAnalyser.analysis(readSheetList, Boolean.FALSE);
return this;
}
最主要的是这个类:excelAnalyser

XlsxSaxAnalyser负责解析excel的每个格子的数据。
DefaultAnalysisEventProcessor会获取解析到的数据,并各个readListener的子类比如我们自定义的demoDataListener的invoke方法,然后由各个listener对数据进行处理。
进入analysis:
ExcelAnalyserImpl

点击进入:
XlsxSaxAnalyser

看下解析每行数据的代码:
会进入

然后进入parseXmlSource方法:

DefaultAnalysisEventProcessor

dealData():
这个是调用自定义监听处理每行数据的invoke的入口:
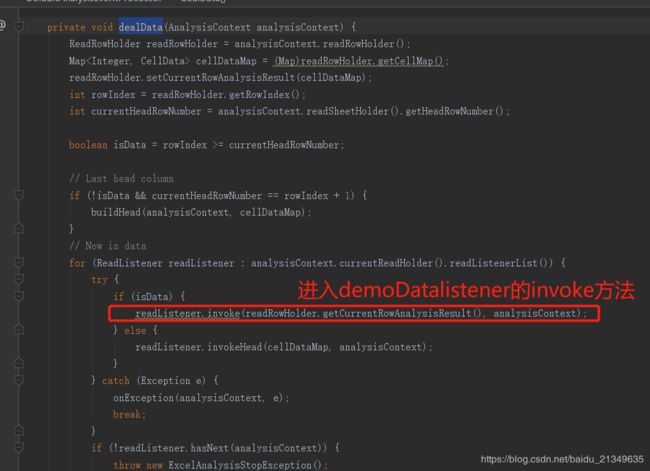
DemoDatalistener的invoke()方法被调用

返回到XlsxSaxAnalyser
处理完每行之后
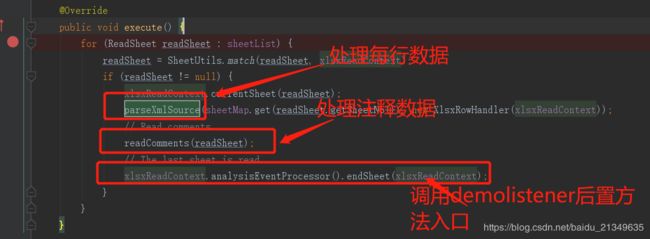
进入endSheet()方法:
DefaultAnalysisEventProcessor的endSheet()

for循环里面是调用自定义监听的lDemoDataistener的
DemoDataistener的doAfterAllAnalysed()

自此,走完了所有的流程。
备注:官方给的详细参数介绍
关于常见类解析
- EasyExcel 入口类,用于构建开始各种操作
- ExcelReaderBuilder ExcelWriterBuilder 构建出一个 ReadWorkbook WriteWorkbook,可以理解成一个excel对象,一个excel只要构建一个
- ExcelReaderSheetBuilder ExcelWriterSheetBuilder 构建出一个 ReadSheet WriteSheet对象,可以理解成excel里面的一页,每一页都要构建一个
- ReadListener 在每一行读取完毕后都会调用ReadListener来处理数据
- WriteHandler 在每一个操作包括创建单元格、创建表格等都会调用WriteHandler来处理数据
- 所有配置都是继承的,Workbook的配置会被Sheet继承,所以在用EasyExcel设置参数的时候,在EasyExcel…sheet()方法之前作用域是整个sheet,之后针对单个sheet
读
注解
ExcelProperty指定当前字段对应excel中的那一列。可以根据名字或者Index去匹配。当然也可以不写,默认第一个字段就是index=0,以此类推。千万注意,要么全部不写,要么全部用index,要么全部用名字去匹配。千万别三个混着用,除非你非常了解源代码中三个混着用怎么去排序的。ExcelIgnore默认所有字段都会和excel去匹配,加了这个注解会忽略该字段DateTimeFormat日期转换,用String去接收excel日期格式的数据会调用这个注解。里面的value参照java.text.SimpleDateFormatNumberFormat数字转换,用String去接收excel数字格式的数据会调用这个注解。里面的value参照java.text.DecimalFormatExcelIgnoreUnannotated默认不加ExcelProperty的注解的都会参与读写,加了不会参与
参数
通用参数
ReadWorkbook,ReadSheet 都会有的参数,如果为空,默认使用上级。
converter转换器,默认加载了很多转换器。也可以自定义。readListener监听器,在读取数据的过程中会不断的调用监听器。headRowNumber需要读的表格有几行头数据。默认有一行头,也就是认为第二行开始起为数据。head与clazz二选一。读取文件头对应的列表,会根据列表匹配数据,建议使用class。clazz与head二选一。读取文件的头对应的class,也可以使用注解。如果两个都不指定,则会读取全部数据。autoTrim字符串、表头等数据自动trimpassword读的时候是否需要使用密码
ReadWorkbook(理解成excel对象)参数
excelType当前excel的类型 默认会自动判断inputStream与file二选一。读取文件的流,如果接收到的是流就只用,不用流建议使用file参数。因为使用了inputStreameasyexcel会帮忙创建临时文件,最终还是filefile与inputStream二选一。读取文件的文件。autoCloseStream自动关闭流。readCache默认小于5M用 内存,超过5M会使用EhCache,这里不建议使用这个参数。
ReadSheet(就是excel的一个Sheet)参数
sheetNo需要读取Sheet的编码,建议使用这个来指定读取哪个SheetsheetName根据名字去匹配Sheet,excel 2003不支持根据名字去匹配
写
注解
ExcelPropertyindex 指定写到第几列,默认根据成员变量排序。value指定写入的名称,默认成员变量的名字,多个value可以参照快速开始中的复杂头ExcelIgnore默认所有字段都会写入excel,这个注解会忽略这个字段DateTimeFormat日期转换,将Date写到excel会调用这个注解。里面的value参照java.text.SimpleDateFormatNumberFormat数字转换,用Number写excel会调用这个注解。里面的value参照java.text.DecimalFormatExcelIgnoreUnannotated默认不加ExcelProperty的注解的都会参与读写,加了不会参与
参数
通用参数
WriteWorkbook,WriteSheet ,WriteTable都会有的参数,如果为空,默认使用上级。
converter转换器,默认加载了很多转换器。也可以自定义。writeHandler写的处理器。可以实现WorkbookWriteHandler,SheetWriteHandler,RowWriteHandler,CellWriteHandler,在写入excel的不同阶段会调用relativeHeadRowIndex距离多少行后开始。也就是开头空几行needHead是否导出头head与clazz二选一。写入文件的头列表,建议使用class。clazz与head二选一。写入文件的头对应的class,也可以使用注解。autoTrim字符串、表头等数据自动trim
WriteWorkbook(理解成excel对象)参数
excelType当前excel的类型 默认xlsxoutputStream与file二选一。写入文件的流file与outputStream二选一。写入的文件templateInputStream模板的文件流templateFile模板文件autoCloseStream自动关闭流。password写的时候是否需要使用密码useDefaultStyle写的时候是否是使用默认头
WriteSheet(就是excel的一个Sheet)参数
sheetNo需要写入的编码。默认0sheetName需要些的Sheet名称,默认同sheetNo
WriteTable(就把excel的一个Sheet,一块区域看一个table)参数
tableNo需要写入的编码。默认0
10M以上文件读取说明
03版没有办法处理,相对内存占用大很多。excel 07版本有个共享字符串共享字符串的概念,这个会非常占用内存,如果全部读取到内存的话,大概是excel文件的大小的3-10倍,所以easyexcel用存储文件的,然后再反序列化去读取的策略来节约内存。当然需要通过文件反序列化以后,效率会降低,大概降低30-50%(不一定,也看命中率,可能会超过100%)
如果对读取效率感觉还能接受,就用默认的,永久占用(单个excel读取整个过程)一般不会超过50M(大概率就30M),剩下临时的GC会很快回收
默认大文件处理
默认大文件处理会自动判断,共享字符串5M以下会使用内存存储,大概占用15-50M的内存,超过5M则使用文件存储,然后文件存储也要设置多内存M用来存放临时的共享字符串,默认20M。除了共享字符串占用内存外,其他占用较少,所以可以预估10M,所以默认大概30M就能读取一个超级大的文件。
根据实际需求配置内存
想自定义设置,首先要确定你大概愿意花多少内存来读取一个超级大的excel,比如希望读取excel最多占用100M内存(是读取过程中永久占用,新生代马上回收的不算),那就设置使用文件来存储共享字符串的大小判断为20M(小于20M存内存,大于存临时文件),然后设置文件存储时临时共享字符串占用内存大小90M差不多
如果最大文件条数也就十几二十万,然后excel也就是十几二十M,而且不会有很高的并发,并且内存也较大
// 强制使用内存存储,这样大概一个20M的excel使用150M(很多临时对象,所以100M会一直GC)的内存
// 这样效率会比上面的复杂的策略高很多
// 这里再说明下 就是加了个readCache(new MapCache()) 参数而已,其他的参照其他demo写 这里没有写全
EasyExcel.read().readCache(new MapCache());
对并发要求较高,而且都是经常有超级大文件
// 第一个参数的意思是 多少M共享字符串以后 采用文件存储 单位MB 默认5M
// 第二个参数 文件存储时,内存存放多少M缓存数据 默认20M
// 比如 你希望用100M内存(这里说的是解析过程中的永久占用,临时对象不算)来解析excel,前面算过了 大概是 20M+90M 所以设置参数为:20 和 90
// 这里再说明下 就是加了个readCacheSelector(new SimpleReadCacheSelector(5, 20))参数而已,其他的参照其他demo写 这里没有写全
EasyExcel.read().readCacheSelector(new SimpleReadCacheSelector(5, 20));
关于maxCacheActivateSize 也就是前面第二个参数的详细说明
easyexcel在使用文件存储的时候,会把共享字符串拆分成1000条一批,然后放到文件存储。然后excel来读取共享字符串大概率是按照顺序的,所以默认20M的1000条的数据放在内存,命中后直接返回,没命中去读文件。所以不能设置太小,太小了,很难命中,一直去读取文件,太大了的话会占用过多的内存。
如何判断 maxCacheActivateSize是否需要调整
开启debug日志会输出Already put :4000000 最后一次输出,大概可以得出值为400W,然后看Cache misses count:4001得到值为4K,400W/4K=1000 这代表已经maxCacheActivateSize 已经非常合理了。如果小于500 问题就非常大了,500到1000 应该都还行。
个人微信公众号:
搜索: 怒放de每一天
不定时推送相关文章,期待和大家一起成长!!

完