Matplotlib 在金融分析中的使用
记录学习过程,深化理解。
在 jupyter notebook 中 plt.show 无法显示图像,需要在代码最前面加上以下内容。
#matplotlib inline
Matplotlib.pyplot.hist 直方图
matplotlib.pyplot.hist(x, bins=None, range=None, density=None, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, normed=None, *, data=None, **kwargs)
直方图的含义是统计这批数据落在各个区间的数量。x 参数获取的就是数据;bins 参数如果是一个整数,表示我们将将这批数据分进多少个区间之中;range 参数要求是 tuple 类型,默认是取 x 中数据的两个端点最大值和最小值,我们也可以自己限定范围。
我们会得到三个返回值,n,bins 和 patches。n 是我们所划分的各个区间中的个体个数,bins 得到的是划分区间的点。
计算收益率
收益率的意义就是每天的价格相对于上一个交易日价格的变化率,可以通过对 Series 对象的 pct_change 方法计算得到。注意 pct_change 方法得到也是一个 Series,第一个为 NaN,所以在传给 hist 之前需要截取有意义的部分。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('sz50.xlsx',sheet_name = '600036.XSHG', index_col = 'datetime')
R1 = df.close.pct_change()[1:]
plt.figure(figsize = (15,7))
plt.hist(R1, bins = 20)
plt.xlabel('Return')
plt.ylabel('Numbers of day observed')
plt.title('Frequency Distribution of 000001 Return.')
plt.show()计算累计直方图
累计直方图就是划分好区间,然后每个区间中的值,表示的是该区间小于右端点的数据的个数(与普通的直方图相比,普通的直方图中区间的数值表示大于左端点小于右端点的数据的个数),所以呈现出来的必然是从左到右逐渐升高的直方图。本质上这也是一种统计的方式,我们通过设置 hist 函数的参数 cumulative 为 True 可以实现。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('sz50.xlsx',sheet_name = '600036.XSHG', index_col = 'datetime')
R1 = df.close.pct_change()[1:]
plt.figure(figsize = (15,7))
plt.hist(R1, bins = 20, cumulative = 0)
plt.xlabel('Return')
plt.ylabel('Numbers of day observed.')
plt.title('Cumulative Distribution of 600036.')
plt.show()如果设 cumulative 为 -1 则会呈现出相反的结果,即下方右图呈现出的效果。
 cumulative 为 True
cumulative 为 True
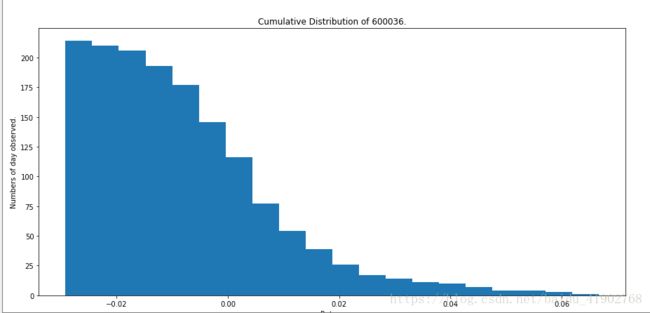 cumulative 为 -1
cumulative 为 -1
Matplotlib.pyplot.scatter 散点图
散点图通常用来观察两个序列之间的相关情况,例如我们观察两只股票收益率的相关性,代码如下:
import matplotlib.pyplot as plt
import pandas as pd
stock1 = pd.read_excel("sz50.xlsx", sheet_name = '601318.XSHG', index_col = 'datetime')
stock2 = pd.read_excel("sz50.xlsx", sheet_name = '600036.XSHG', index_col = 'datetime')
plt.figure(figsize = (15,7)
plt.scatter(stock1.close.pct_change()[1:], stock2.close.pct_change()[1:], s = 20,c = ['b'])
plt.xlabel('601318')
plt.ylabel('600036')
plt.show()
得到的图像如上。不过在根据官方文档的教程中,c 的参数是可以传递一个各种颜色列表,可以使散点按照列表中的颜色的顺序着色,不过有一个要求就是散点的数量需要与 c 参数对应的列表长度一致。我看的 github 上一个关于 matplotlib 的代码中用到了
plt.scatter(R1, R2,c=['c','r'],s=20)
然后我尝试着用相同的方式去描绘出两种颜色相间的点失败了,报错内容如下,所以我还是老老实实用一种颜色吧。
ValueError: 'c' argument has 2 elements, which is not acceptable for use with 'x' with size 214, 'y' with size 214.
Matplotlib.pyplot.plot 折线图与 subplots 复合图
import matplotlib.pyplot as plt
import pandas as pd
stock1 = pd.read_excel("sz50.xlsx", sheet_name = '601318.XSHG', index_col = 'datetime')
stock2 = pd.read_excel("sz50.xlsx", sheet_name = '600036.XSHG', index_col = 'datetime')
plt.plot(stock1.close)
plt.plot(stock2.close)
plt.legend(['601318','600036'])
plt.show() 
以上为简单的代码和所展示的图像。legend 方法是用来显示哪条折线代表的是什么内容,也可以在 plot 方法中填写 label 对象再经过一个空内容的 legend 方法输出。在调用 legend 时可以传递参数 loc 来定位,1 右上 2左上 3 左下 4 右下。
也可以调整成两个图像。偶然发现在旧的 matplotlib 版本中如果是用 sheet_name 参数是没反应的,必须是 sheetname,这种情况下会只读取第一个 sheet 所以绘制出的内容是相同的;而较新的版本中二者皆可不过会提示用 sheet_name 更佳。要给小图添加标题要用方法 set_title,同理想要添加 x 轴或者 y 轴的注释分别为 set_xlabel 和 set_ylabel。
linewidth 确定线的粗细。
import pandas as pd
import matplotlib.pyplot as plt
stock1 = pd.read_excel("sz50.xlsx", sheet_name = '601318.XSHG', index_col = 'datetime')
stock2 = pd.read_excel('sz50.xlsx', sheet_name = '600000.XSHG', index_col = 'datetime')
figure,(ax,ax1) = plt.subplots(nrows = 2,ncols = 1, figsize = (15,7), sharex = True)
ax.plot(stock1.close)
ax.set_title('601318')
ax1.plot(stock2.close)
ax1.set_title('600000')
plt.show()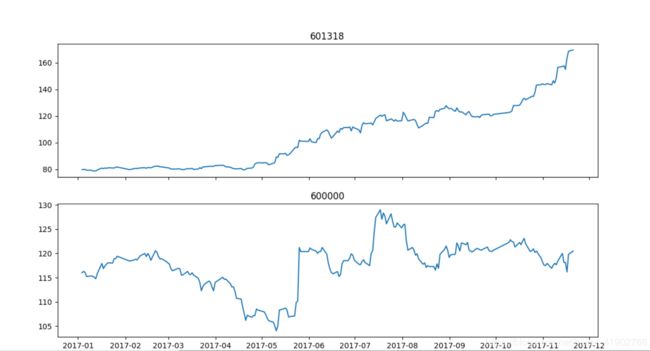
subplots 函数中常用的参数有 sharex 和 sharey 来控制小图共用一个条坐标轴;参数 squeeze 默认为 True,意为压缩,是把我们的多个小图的本质,对象类型为
#参数 squeeze 的默认值即为 True
figure, ax = plt.subplots(2, 1, sharex = True, squeeze = True)
ax[0].plot(stock1.close)
ax[1].plot(stock2.close)
#参数 squeeze 的默认值即为 False
figure, ax = plt.subplots(2, 1, sharex = True, squeeze = False)
ax[0][0].plot(stock1.close)
#也可以写成 ax[0, 0]
ax[1][0].plot(stock2.close)
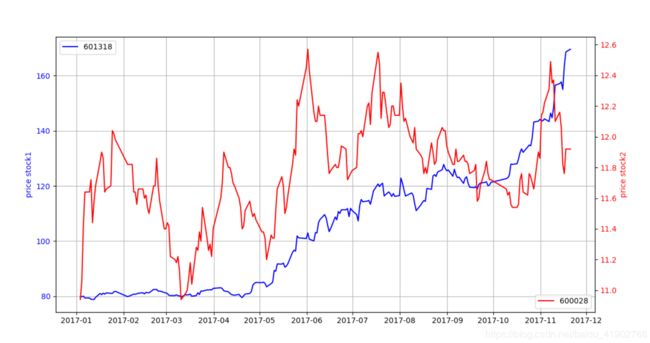
我们还可以绘制双纵坐标的图,常用来比较不同单位或者尺度但是相关的序列。以下代码中用 subplots 创建一个 ax,我们可以理解成建立一个坐标轴,而后有一句 ax1=ax.twinx() 也就是创建一个覆盖的坐标轴,只不过纵坐标的刻度在右侧。相应的如果我们希望不是共用横坐标而是要共用纵坐标,则使用 twiny()。
import pandas as pd
import matplotlib.pyplot as plt
stock1 = pd.read_excel("sz50.xlsx", sheetname = '601318.XSHG', index_col = 'datetime')
stock2 = pd.read_excel('sz50.xlsx', sheetname = '600028.XSHG', index_col = 'datetime')
figure,ax = plt.subplots(figsize = (15,7))
ax.plot(stock1.close, c = 'b')
ax.grid()
ax.legend(['601318'],loc = 2)
ax.set_ylabel('price stock1')
ax1 = ax.twinx()
ax1.plot(stock2.close, c = 'r')
ax1.legend(['600028'], loc = 4)
ax1.set_ylabel('price stock2')
plt.show()

不过看上面的图有个问题,我们难以区分两条折线各是对应哪侧的坐标轴,虽然我们通过 legend 方法给出了注释大概可以说蓝色的注释在左侧所以蓝色折线是看左侧纵坐标,但还是不太准确。我们可以改动以下代码,来控制坐标刻度和标签的颜色,是不是就像下图变得更加直观了呢~
ax.set_ylabel('price stock1', color = 'b')
ax.tick_params(axis = 'y', labelcolor = 'b')
......
ax1.set_ylabel('price stock2', color = 'r')
ax1.tick_params(axis = 'y', labelcolor = 'r')
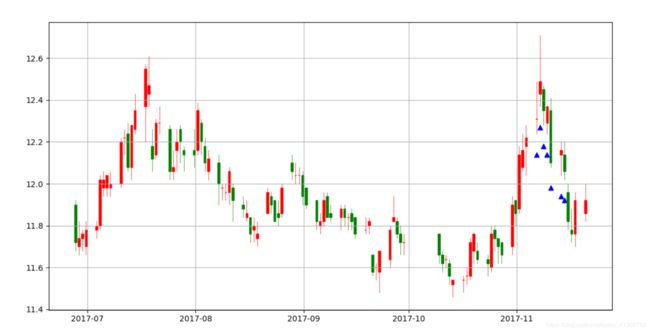
Matplotlib.finance(mpl_finance)
这个库已经被移除了,需要额外安装 mpl_finance 并调用其中的内容。
import pandas as pd
import matplotlib.pyplot as plt
import mpl_finance as mpf
import talib as tb
from matplotlib.pylab import date2num
stock1 = pd.read_excel('sz50.xlsx', sheetname = '600028.XSHG', index_col = 'datetime')[-100:]
MACD = tb.abstract.MACD(stock1).macd
axisX = MACD.loc[MACD>0.1].index
axisY = stock1.loc[axisX].low-0.1
stock1['time'] = list(map(date2num, stock1.index))
candle = stock1.reindex_axis(['time', 'open', 'high', 'low', 'close'], 1).values
figure,ax = plt.subplots(figsize=(15,7))
mpf.candlestick_ohlc(ax, candle, width = 0.6, colorup = 'r', colordown = 'g')
ax.xaxis_date()
ax.scatter(axisX, axisY, color = 'b', marker = '^')
plt.show()以上代码实现的功能是什么呢?有两个内容,第一个就是绘制 k 线图,第二个就是在图上添加一个 MACD 指标的标注。
首先我们来看 MACD 的部分(为什么先讲这部分稍后会提到),我们通过 talib.abstract 模块中的 MACD 方法来计算得到相关的数据,abstract 接收参数会更加的宽松,尤其是可以接受 pandas 的对象,使得计算方便许多。计算得到了一个 DataFrame,index 与原数据相同而 columns 有三列为 macd,macdsignal,macdhist,通常我们只需要第一个。获取第一列之后使用布尔索引的方法,得到满足筛选条件的部分,这部分的 index 就是满足我们设定的 MACD 的数值大于 0.1 的日子,后面我们利用这个 DatetimeIndex 来在图中绘制具有指示意义小三角形。
然后是蜡烛图,蜡烛图需要用到库 mpl_finance 中的 candlestick_ohlc,ohlc 也就是 open、high、low 和 close,正是蜡烛图中每条蜡烛的组成元素。其中需要指定一个 ax,即绘制在哪个图中;candle 接受一个 ndarray,其中的数据必须是按照第一列时间第二三四五 ohlc 这样子排列,这里数据是通过一定的构造得到的,从代码中就可以看出思路来,关键点在于使用 matplotlib.pylab 中的内置函数 date2num 把 datetime 对象转化成数值才能被 candlestick_ohlc 函数接受,后续再把坐标轴转化成日期即可(方法就是 ax.xaxis_date())。由于说我们会改动了 stock1 这个对象,所以在整体结构上我们才把 MACD 的工作放在前面,否则添加了新的 columns 之后的对象传递给 MACD 方法是无法得到正确有效的结果的。
为了视觉效果更清晰,把数据量控制小一些。得到的图像如下。之所以后续才有标记 MACD>0.1 的三角形出现,那是因为,MACD 指标的计算是需要前若干一段时间数据来计算,那么对于较前的日期便没有数据可以计算所以当日的值为 nan 也就不可能出现在图上。