用户兴趣模型分类以及推荐系统技术调研
用户兴趣模型分类
根据用户之前在相关网站的行为数据记录分析出用户的兴趣和偏好,然后根据不同用户兴趣和偏好不同为其推荐不同的内容,这种新的信息获取方式被称为个性化推荐技术。
个性化新闻推荐系统中常用的几种用户兴趣建模方法:
(1) 关键词列表表示法
用户的兴趣模型是由个或者多个用户感兴趣的关键词所构成的关键词序列来表示。例如某用户对篮球十分感兴趣,则用户的兴趣模型可能表示成如下形式{NBA,湖人,科比,三分,战术}。用户兴趣关键词的获取方式主要由用户主动提供和系统隐式自动获取两种。与文本分类中的特征选择问题类似,通过自动学习的方法得出反映用户兴趣的关键词序列在本质上也是通过训练样本集得到一个较小的特征集合。主要区别在于,前者是为了减小分类模型的计算量,提升分类的精度,而后者的目的在于找出样本中反映用户兴趣的关键词序列。
(2) 基于布尔模型的表示方法
布尔模型是最简单的一种模型。它是建立在布尔代数理论的基础上。其中,每个关键词在文档中只有两种可能,包含或不包含。因此关键词的权值只有两个可能值和。其中,表示文档包含该特征词,则表示文档不包含该关键词。布尔模型的构造简单,易于理解,但是它的缺点也很明显。布尔模型只能执行简单的布尔查询操作,没有把文档和用户兴趣的相关度排序的概念,也不能反映出每个关键词对文档的重要程度。
(3) 基于向量空间模型的表示方法
基于向量空间模型的表示方法是指用关键词和关键词的权重的向量来表示用户兴趣模型。向量空间模型(是由等人在世纪年代提出的,它是文档表示中最常见的方法。通常当我们获取了表示用户兴趣的浏览文档内容后,系统可以自动地从这些文档中提取关键词,以及与关键词相关联的权重,用来对文档进行向量化表示。这样每个文档可以表示为{(ti,w1)(t2,w2)…(ti,wi)}其中ti为文档中的第i项,它可以是字、词、短语或词组等。wi为ti项在该文档中的重要程度,及ti项的权重。t1…ti可以是文档中出现的所有项,也可以是一个经过筛选处理后的子集。对于的算法有多种可选,最常用到的有词频法和tf-idf法。
(4) 基于本体的用户模型表示方法
本体(给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义。由于本体本身的特点,它包含领域常用术语的同时并提供术语与术语之间的网状关系,基于领域的术语对于用户兴趣有着很好的描述能力,同时术语之间的关系为用户兴趣之间提供了联系的桥梁,除此之外还有简单的推理能力。从而使得用户模型从类似与人的思维方式理解用户的兴趣特征,是一个理论上十分理想的用户模型表示方法。但是本体的构建需不仅需要专业的领域知识还需要巨大的人工劳动,构建成本过大,基于本体的用户模型表示法并不常用。
用户兴趣特征的特点:兴趣并不是天生的,它有着从产生到持续再到消亡的一个过程。
目前主流的个性化推荐技术主要分为:基于规则的推荐、基于内容过滤的推荐、基于协同过滤的推荐、基于知识的推荐等.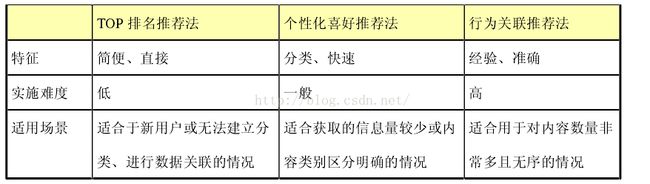
top排名推荐法不关心客户的兴趣和行为,只关心用户的兴趣或潜在兴趣,根据用户的兴趣分类,对相应分类 TOP 排名的内容进行推荐。这种方法操作简单,无需进行数据分析,实施难度低,适合用于新用户或无法获得用户信息的情况。
个性化喜好推荐法根据用户的喜好信息进行内容推荐,需要事先确定分类的标准,并对用户进行分类,对内容也进行相应的分类,并根据一定的规则将用户和内容进行匹配。这种方法事先确定好分类标准,能对内容预先进行处理,并对单个用户建立个性化的资料,快速实现用户和内容的匹配。
行为关联推荐法对大量数据进行分析挖掘,找出不同行为之间的关联关系,并根据用户已有的行为,与分析出的不同行为之间的关系进行比较,从而确定用户下一步的可能行为。行为关联推荐法需要大量数据支持,对数据分析挖掘的要求较高,在进行内容推荐时,实施难度较大,但这种方法通过对规律的发掘,往往成功率很高。
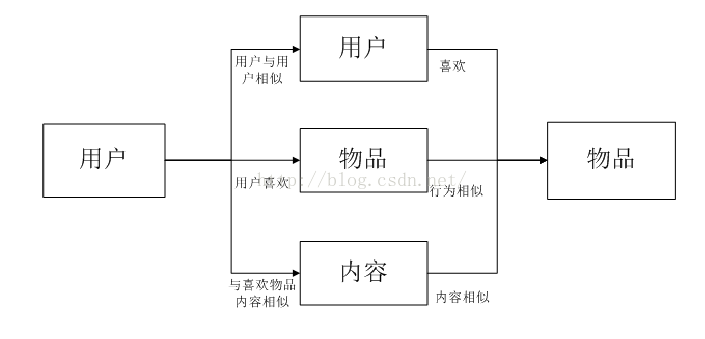
1基于物品的协同过滤算法
该推荐算法是计算两个物品的相似度,用户通过喜欢的物品与其他物品的相似度来找到它喜欢物品的最近“邻居”,进而得到自己喜欢的物品。
基于物品的协同过滤个性化推荐算法计算可以分成两步:
第一,计算物品间的相似性;
第二,根据物品间的相似性以及用户之前喜欢过的物品来产生一个推荐列表。
2基于用户的协同过滤算法
基于用户的协同过滤推荐算法是现今效率较高且应用比较广泛的一种推荐算法,该算法利用用户的兴趣爱好、习惯等信息建立用户与用户之间的相似性,根据用户之间的相似性,最后把相似用户喜欢的物品推荐给用户。
具体过程如下:
1 创建数据。系统可以根据历史的用户、物品以及用户对物品的偏好创建数据。一个推荐系统都包括用户和物品。为每个用户及他喜欢的物品构建向量模型。
2 产生“邻居”。该算法的核心是为目标用户寻找与他相似的k个用户,作为用户的一组邻居。
基于内容的推荐算法
基于内容的推荐算法是很早就已经被使用的一种推荐方法,它根据用户过去喜欢的物品,来给用户推荐与其过去喜欢的物品内容和特征相似的物品。比如,在商品推荐中,该算法要分析用户购买的商品的一些共性(类别、风格等),然后推荐与他们感兴趣的商品内容相似度高的未购买过的商品。
该推荐系统由三步组成:
1.个人资料集:根据用户历史的行为,学习用户的偏好,并建立用户的偏好特
征数据(profile);
2.物品特征分析:以每一个物品的特征为数据建立物品的特征数据集,来代表
每一个物品 item;
3.推荐:为用户推荐其历史行为物品相似内容的物品。