基本BP算法的实例----蚊子的分类
已知的两类蚊子的数据如表1:

表1
规定目标为: 当t(1)=0.9 时表示属于Apf类,t(2)=0.1表示属于Af类。
输入数据有15个,即 , p=1,…,15; j=1, 2; 对应15个输出。
即对应的(X,Y)对为:([1.78,1.14],0.9),([1.96,1.18],0.9)......([2.08,1.56],0.1)
由于此时的X有两个属性,故输入端为2个,建立神经网络如下:
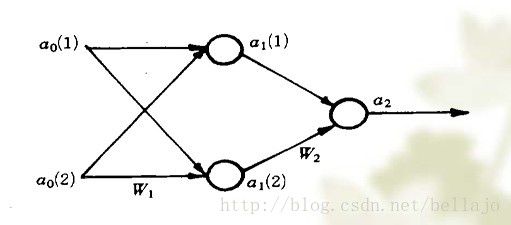
设两个权重系数矩阵为:

分析如下:
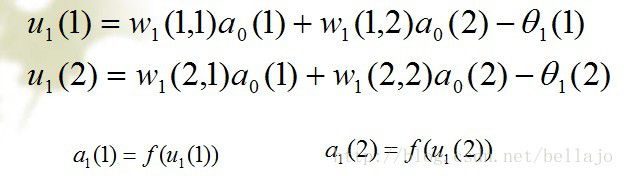
为第一层的输出,同时作为第二层的输入。

在这里,a0(3)可以认为为常数
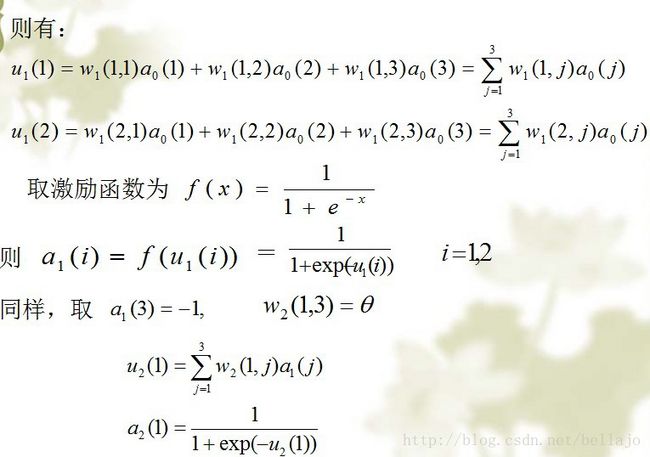
具体算法如下:
令p=0
(1)随机给出两个权矩阵的初值;例如用MATLAB软件时可以用以下语句:

(2) 根据输入数据利用公式算出网络的输出 


(6) p=p+1,转(2)
注:仅计算一圈(p=1,2,…,15)是不够的,直到当各权重变化很小时停止,本例中,共计算了147圈,迭代了2205次。
最后结果是:
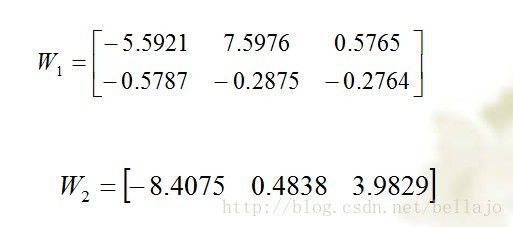
即网络模型的解为: 
神经网络的应用
1.样本数据
1.1 收集和整理分组
采用BP神经网络方法建模的首要和前提条件是有足够多典型性好和精度高的样本。而且,为监控训练(学习)过程使之不发生“过拟合”和评价建立的网络模型的性能和泛化能力,必须将收集到的数据随机分成训练样本、检验样本(10%以上)和测试样本(10%以上)3部分。此外,数据分组时还应尽可能考虑样本模式间的平衡。
1.2 输入/输出变量的确定及其数据的预处理
一般地,BP网络的输入变量即为待分析系统的内生变量(影响因子或自变量)数,一般根据专业知识确定。若输入变量较多,一般可通过主成份分析方法压减输入变量,也可根据剔除某一变量引起的系统误差与原系统误差的比值的大小来压减输入变量。输出变量即为系统待分析的外生变量(系统性能指标或因变量),可以是一个,也可以是多个。一般将一个具有多个输出的网络模型转化为多个具有一个输出的网络模型效果会更好,训练也更方便。
由于BP神经网络的隐层一般采用Sigmoid转换函数,为提高训练速度和灵敏性以及有效避开Sigmoid函数的饱和区,一般要求输入数据的值在0~1之间。因此,要对输入数据进行预处理。一般要求对不同变量分别进行预处理,也可以对类似性质的变量进行统一的预处理。如果输出层节点也采用Sigmoid转换函数,输出变量也必须作相应的预处理,否则,输出变量也可以不做预处理。
预处理的方法有多种多样,各文献采用的公式也不尽相同。但必须注意的是,预处理的数据训练完成后,网络输出的结果要进行反变换才能得到实际值。再者,为保证建立的模型具有一定的外推能力,最好使数据预处理后的值在0.2~0.8之间。
2.神经网络拓扑结构的确定
2.1 隐层数
一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。Hornik等早已证明:若输入层和输出层采用线性转换函数,隐层采用Sigmoid转换函数,则含一个隐层的MLP网络能够以任意精度逼近任何有理函数。显然,这是一个存在性结论。在设计BP网络时可参考这一点,应优先考虑3层BP网络(即有1个隐层)。一般地,靠增加隐层节点数来获得较低的误差,其训练效果要比增加隐层数更容易实现。对于没有隐层的神经网络模型,实际上就是一个线性或非线性(取决于输出层采用线性或非线性转换函数型式)回归模型。因此,一般认为,应将不含隐层的网络模型归入回归分析中,技术已很成熟,没有必要在神经网络理论中再讨论之。
2.2 隐层节点数
在BP 网络中,隐层节点数的选择非常重要,它不仅对建立的神经网络模型的性能影响很大,而且是训练时出现“过拟合”的直接原因,但是目前理论上还没有一种科学的和普遍的确定方法。
目前多数文献中提出的确定隐层节点数的计算公式都是针对训练样本任意多的情况,而且多数是针对最不利的情况,一般工程实践中很难满足,不宜采用。事实上,各种计算公式得到的隐层节点数有时相差几倍甚至上百倍。为尽可能避免训练时出现“过拟合”现象,保证足够高的网络性能和泛化能力,确定隐层节点数的最基本原则是:在满足精度要求的前提下取尽可能紧凑的结构,即取尽可能少的隐层节点数。研究表明,隐层节点数不仅与输入/输出层的节点数有关,更与需解决的问题的复杂程度和转换函数的型式以及样本数据的特性等因素有关。
在确定隐层节点数时必须满足下列条件:
(1)隐层节点数必须小于N-1(其中N为训练样本数),否则,网络模型的系统误差与训练样本的特性无关而趋于零,即建立的网络模型没有泛化能力,也没有任何实用价值。同理可推得:输入层的节点数(变量数)必须小于N-1。
(2) 训练样本数必须多于网络模型的连接权数,一般为2~10倍,否则,样本必须分成几部分并采用“轮流训练”的方法才可能得到可靠的神经网络模型。
总之,若隐层节点数太少,网络可能根本不能训练或网络性能很差;若隐层节点数太多,虽然可使网络的系统误差减小,但一方面使网络训练时间延长,另一方面,训练容易陷入局部极小点而得不到最优点,也是训练时出现“过拟合”的内在原因。因此,合理隐层节点数应在综合考虑网络结构复杂程度和误差大小的情况下用节点删除法和扩张法确定。
3.神经网络的训练
3.1 训练
BP网络的训练就是通过应用误差反传原理不断调整网络权值使网络模型输出值与已知的训练样本输出值之间的误差平方和达到最小或小于某一期望值。虽然理论上早已经证明:具有1个隐层(采用Sigmoid转换函数)的BP网络可实现对任意函数的任意逼近。但遗憾的是,迄今为止还没有构造性结论,即在给定有限个(训练)样本的情况下,如何设计一个合理的BP网络模型并通过向所给的有限个样本的学习(训练)来满意地逼近样本所蕴含的规律(函数关系,不仅仅是使训练样本的误差达到很小)的问题,目前在很大程度上还需要依靠经验知识和设计者的经验。因此,通过训练样本的学习(训练)建立合理的BP神经网络模型的过程,在国外被称为“艺术创造的过程”,是一个复杂而又十分烦琐和困难的过程。
由于BP网络采用误差反传算法,其实质是一个无约束的非线性最优化计算过程,在网络结构较大时不仅计算时间长,而且很容易限入局部极小点而得不到最优结果。目前虽已有改进BP法、遗传算法(GA)和模拟退火算法等多种优化方法用于BP网络的训练(这些方法从原理上讲可通过调整某些参数求得全局极小点),但在应用中,这些参数的调整往往因问题不同而异,较难求得全局极小点。这些方法中应用最广的是增加了冲量(动量)项的改进BP算法。
3.2 学习率和冲量系数
学习率影响系统学习过程的稳定性。大的学习率可能使网络权值每一次的修正量过大,甚至会导致权值在修正过程中超出某个误差的极小值呈不规则跳跃而不收敛;但过小的学习率导致学习时间过长,不过能保证收敛于某个极小值。所以,一般倾向选取较小的学习率以保证学习过程的收敛性(稳定性),通常在0.01~0.8之间。
增加冲量项的目的是为了避免网络训练陷于较浅的局部极小点。理论上其值大小应与权值修正量的大小有关,但实际应用中一般取常量。通常在0~1之间,而且一般比学习率要大。
4 网络的初始连接权值
BP算法决定了误差函数一般存在(很)多个局部极小点,不同的网络初始权值直接决定了BP算法收敛于哪个局部极小点或是全局极小点。因此,要求计算程序(建议采用标准通用软件,如Statsoft公司出品的Statistica Neural Networks软件和Matlab 软件)必须能够自由改变网络初始连接权值。由于Sigmoid转换函数的特性,一般要求初始权值分布在-0.5~0.5之间比较有效。