跨平台C语言开源库总结
一.Think库
提供跨平台的C语言库,各类C、C++程序都可以用到其中的东西,已支持AIX、HP-UX、Solaris、FreeBSD、Linux、Mac OS X和Windows操作系统
本人辛苦了四年,颠覆多次,终成这个发布版,现在作为unix-center的开源项目,任何非册用户进入此链接都可以下载有兴趣的先顶一下,便于后面的伙计看到此贴。
第二版主要增加了进程通讯的一些东西,包括线程,线程锁,进程锁,信号量,共享内存及由信号量与共享内存实现的消息队列
下载地址: http://unix-center.org/projects/think/
以下为网站公布的部分接口文档:
发表人: enigma1983 Unix-Center
日期: 2009-08-22 21:15
概要: Think库之NET接口(socket接口)
项目: Think
Think NET是socket通讯的基本操作的封装,提供connect、listen、accept、send、recv、close几个基本接口,另外对select进行了封装,对包含socket名柄信息的双向循环链表进行侦听,同样也对UNIX上的poll实现了同样的封装,喜欢用poll的只需更换函数名即可,其它操作完全一样
struct __think_net {
int sockfd;
char ip[16];
unsigned short port;
int flags;
};
typedef struct __think_net THINK_NET;
1:建立连接
THINK_NET *think_netconnect(const char *ip,unsigned short port);
参数故名思意
2:建立侦听
THINK_NET *think_netlisten(const char *ip,unsigned short port);
3:THINK_NET *think_netaccept(THINK_NET *net);
net为侦听名柄
4:接收数据
int think_netrecv(THINK_NET *net,void *buf,unsigned int siz,int flags);
buf为数据存放地址
siz为大小
flags为标志,可以接受的值为THINK_NET_WAIT,即一直等到siz个字节全部接收完毕或有错误时才返回
5:发送数据
int think_netsend(THINK_NET *net,const void *buf,unsigned int len,int flags);
flags意思与think_netrecv中的相同,此处为len个字节全部发送完毕
6:关闭连接
int think_netclose(THINK_NET *net);
7:加载动态库(Windows平台必须要调用的)
int think_netstart(void);
int think_netstop(void);
netstart为使用网络接之间要调用的,netstop为不使用网络时候调用,也可以由程序退出时自动执行,即think_netstart是必须要执行的。
struct __think_netlist {
THINK_NET *net;
int flags;
struct __think_netlist *prior;
struct __think_netlist *next;
};
typedef struct __think_netlist THINK_NETLIST;
8:向链表中增加一个连接
int think_netlist_add(THINK_NETLIST **netlist,THINK_NET *net);
netlist为链表的地址,如定义一个变量THINK_NETLIST *netlist=NULL,调用时传&netlist即可
9:从链表删除一个连接
int think_netlist_del(THINK_NETLIST **netlist,THINK_NET *net);
10:在链表中查找一个连接
THINK_NETLIST *think_netlist_find(THINK_NETLIST *netlist,THINK_NET *net);
11:清理链表
int think_netlist_clean(THINK_NETLIST **netlist);
调用think_netlist_del时,只是将标志位置为已删除,并未真正从链中删除,因此需要调用这个接口进行清理
12:释放链表
int think_netlist_free(THINK_NETLIST **netlist);
将删除所有连接,并释放内存
13:使用select进行侦听
int think_netselect(THINK_NETLIST **netlist,int timeout);
timeout为等待时间
>0为阻塞式等待一定时间,直到超时
=0为非阻塞式,立即返回
<0为永久阻塞式,直到有事件发生
THINK_NETLIST结构中有一个成员flags,要在调用think_netselect之前,将需要侦听的事件设置好,如将flags设为THINK_NET_READ或THINK_NET_WRITE或THINK_NET_READ|THINK_NET_WRITE,即侦听读、写、读写
think_netselect返回后,通过检查该标志是否被置位成THINK_NET_READ、THINK_NET_WRITE,以得知连接目前为可读或可写
14:使用poll进行侦听
int think_netpoll(THINK_NETLIST **netlist,int timeout);
用法与think_netselect完全一样
15:发送消息
int think_netsendmsg(THINK_NET *net,const void *buf,unsigned int len);
将先送四字节网络字节序的长度,然后再发送具体长度的信息
16:int think_netrecvmsg(THINK_NET *net,void *buf,unsigned int siz);
先接收四字节网络字节序的长度,然后再接收具体长度的信息
发表人: enigma1983 Unix-Center
日期: 2009-08-22 21:54
概要: Think库之NETCENTER接口(socket通讯框架)
项目: Think
Think NETCENTER是借鉴ACE的设计思路,即使用select对所有连接进行侦听,如有连接上有事件发生,则调用相应的回调函数进行处理,这里采用缓冲的方式先将数据接收到缓冲区,然后调用相应的回调函数进行处理,当然如果接口是可写的,那么将查看写缓冲区是否有数据,如果有则从缓冲区读取数据进行发送。
1:建立网络中心
THINK_NETCENTER *think_netcenter_new();
主要是得到一个名柄,网络中心操作名柄
2:进行一次网络处理
int think_netcenter_idle(THINK_NETCENTER *netcenter,int timeout);
这个接口为网络中心的总控接口,它先去调用select进行事件侦听,然后进行数据接收并调用回调函数进行处或从缓冲区发送数据,直到所有接口处理完毕后才返回,应用层需要不断调用此接口完成网络数据的持续处理
timeout与think_netselect中的意思完全一样,这个参数就是原封不动的传给think_netselect的。
3:释放网络中心
int think_netcenter_free(THINK_NETCENTER *netcenter);
这个接口将释放所有表及内存
4:向网络中心注册连接
THINK_NETCENTER_NETLIST *think_netcenter_netadd(THINK_NETCENTER *netcenter,THINK_NET *net,THINK_NETCENTER_NETHANDLE nethandle);
net为所要注册的连接
nethandle为该连接的回调函数地址
5:从网络中心注销连接
int think_netcenter_netdel(THINK_NETCENTER *netcenter,THINK_NET *net);
6:从网络中心查找连接
THINK_NETCENTER_NETLIST *think_netcenter_netfind(THINK_NETCENTER *netcenter,THINK_NET *net);
7:清理网络中心的链表
int think_netcenter_netclean(THINK_NETCENTER *netcenter);
与think_netclean的意思一样,删除时只是置了标志,因此需要进行清理
8:从连接缓冲中读取数据
int think_netcenter_recv(THINK_NETCENTER_NET *net,void *buf,unsigned int siz);
该函数是在回调中调用的,当有数据可读时,通过这个接口可获取数据
9:向连接缓冲区中写入数据
int think_netcenter_send(THINK_NETCENTER_NET *net,const void *buf,unsigned int len);
该函数是在业务处理时调用的,当需要发送数据时,通过这个接口将数据发送到该连接的缓冲区中,由网络中心在idle时进行发送
10:从缓冲区中窃取数据
int think_netcenter_peek(THINK_NETCENTER_NET *net,void *buf,unsigned int siz);
当不知道缓冲区里有什么数据时,可用此接口进行偷窥,即将数据取出来,但缓冲区的数据仍原封不动的保留在那里,这个接口在判断缓冲区是否有完整的数据包时很有用
以下为使用GL语言通讯时使用的接口
11:判断缓冲区是否有完整的数据包
int think_netcenter_ismsgok(THINK_NETCENTER_NET *net);
完整的数据包即四字节网络字节序的长度+对应的数据内容都在缓冲里了
12:从缓冲区接收一个数据包
int think_netcenter_recvmsg(THINK_NETCENTER_NET *net,void *buf,unsigned int siz);
13:向缓冲区发送一个数据包
int think_netcenter_sendmsg(THINK_NETCENTER_NET *net,const void *buf,unsigned int len);
以下为网络中心内部使用的接口
14:从网络上接收数据至缓冲区中
int think_netcenter_recvto(THINK_NETCENTER_NET *net);
15:从缓冲区中读取数据发送到网络上
int think_netcenter_sendfrom(THINK_NETCENTER_NET *net);
16:对网络中心的连接进行侦听
int think_netcenter_select(THINK_NETCENTER *netcenter,int timeout);
即对每个连接置相应的侦听标志,然后调用think_netselect进行侦听
二.一个跨平台内存分配器
昨天一个同事一大早在群里推荐了一个google project上的开源内存分配器(http://code.google.com/p/google-perftools/),据说google的很多产品都用到了这个内存分配库,而且经他测试,我们的游戏客户端集成了这个最新内存分配器后,FPS足足提高了将近10帧左右,这可是个了不起的提升,要知道3D组的兄弟忙了几周也没见这么大的性能提升。
如果我们自己本身用的crt提供的内存分配器,这个提升也算不得什么。问题是我们内部系统是有一个小内存管理器的,一般来说小内存分配的算法都大同小异,现成的实现也很多,比如linux内核的slab、SGI STL的分配器、ogre自带的内存分配器,我们自己的内存分配器也和前面列举的实现差不多。让我们来看看这个项目有什么特别的吧。
一、使用方法
打开主页,由于公司网络禁止SVN从外部更新,所以只能下载了打包的源代码。解压后,看到有个doc目录,进去,打开使用文档,发现使用方法极为简单:To use TCMalloc, just link TCMalloc into your application via the "-ltcmalloc" linker flag.再看算法,也没什么特别的,还是和slab以及SGI STL分配器类似的算法。
unix环境居然只要链接这个tcmalloc库就可以了!,太方便了,不过我手头没有linux环境,文档上也没提到windows环境怎么使用,
打开源代码包,有个vs2003解决方案,打开,随便挑选一个测试项目,查看项目属性,发现仅仅有2点不同:
1、链接器命令行里多了
"..\..\release\libtcmalloc_minimal.lib",就是链接的时候依赖了这个内存优化库。
2、链接器->输入->强制符号引用 多了 __tcmalloc。
这样就可以正确的使用tcmalloc库了,测试了下,测试项目运行OK!
二、如何替换CRT的malloc
从前面的描述可知,项目强制引用了__tcmalloc, 搜索了测试代码,没发现用到_tcmalloc相关的函数和变量,这个选项应该是为了防止dll被优化掉(因为代码里没有什么地方用到这个dll的符号)。初看起来,链接这个库后,不会影响任何现有代码:我们没有引用这个Lib库的头文件,也没有使用过这个dll的导出函数。那么这个dll是怎么优化应用程序性能的呢?
实际调试,果然发现问题了,看看如下代码
void* pData = malloc(100);
00401085 6A 64 push 64h
00401087 FF 15 A4 20 40 00 call dword ptr [__imp__malloc (4020A4h)]
跟踪 call malloc这句,step进去,发现是
78134D09 E9 D2 37 ED 97 jmp `anonymous namespace'::LibcInfoWithPatchFunctions<8>::Perftools_malloc (100084E0h)
果然,从这里开始,就跳转到libtcmalloc提供的Perftools_malloc了。
原来是通过API挂钩来实现无缝替换系统自带的malloc等crt函数的,而且还是通过大家公认的不推荐的改写函数入口指令来实现的,一般只有在游戏外挂和金山词霸之类的软件才会用到这样的挂钩技术,
而且金山词霸经常需要更新补丁解决不同系统兼容问题。
三、性能差别原因
如前面所述,tcmalloc确实用了很hacker的办法来实现无缝的替换系统自带的内存分配函数(本人在使用这类技术通常是用来干坏事的。。。),但是这也不足以解释为什么它的效率比我们自己的好那么多。回到tcmalloc 的手册,tcmalloc除了使用常规的小内存管理外,对多线程环境做了特殊处理,这和我原来见到的内存分配器大有不同,一般的内存分配器作者都会偷懒,把多线程问题扔给使用者,大多是加
个bool型的模板参数来表示是否是多线程环境,还美其名曰:可定制,末了还得吹嘘下模板的优越性。
tcmalloc是怎么做的呢? 答案是每线程一个ThreadCache,大部分操作系统都会支持thread local storage 就是传说中的TLS,这样就可以实现每线程一个分配器了,
这样,不同线程分配都是在各自的threadCache里分配的。我们的项目的分配器由于是多线程环境的,所以不管三七二十一,全都加锁了,性能自然就低了。
仅仅是如此,还是不足以将tcmalloc和ptmalloc2分个高下,后者也是每个线程都有threadCache的。
关于这个问题,doc里有一段说明,原文贴出来:
ptmalloc2 also reduces lock contention by using per-thread arenas but there is a big problem with ptmalloc2's use of per-thread arenas. In ptmalloc2 memory can never move from one arena to another. This can lead to huge amounts of wasted space.
大意是这样的:ptmalloc2 也是通过tls来降低线程锁,但是ptmalloc2各个线程的内存是独立的,也就是说,第一个线程申请的内存,释放的时候还是必须放到第一个线程池中(不可移动),这样可能导致大量内存浪费。
四、代码细节
1、无缝替换malloc等crt和系统分配函数。
前面提到tcmalloc会无缝的替换掉原有dll中的malloc,这就意味着使用tcmalloc的项目必须是 MD(多线程dll)或者MDd(多线程dll调试)。tcmalloc的dll定义了一个static TCMallocGuard module_enter_exit_hook;
的静态变量,这个变量会在dll加载的时候先于DllMain运行,在这个类的构造函数,会运行PatchWindowsFunctions来挂钩所有dll的 malloc、free、new等分配函数,这样就达到了替换功能,除此之外,
为了保证系统兼容性,挂钩API的时候还实现了智能分析指令,否则写入第一条Jmp指令的时候可能会破环后续指令的完整性。
2、LibcInfoWithPatchFunctions 和ThreadCache。
LibcInfoWithPatchFunctions模板类包含tcmalloc实现的优化后的malloc等一系列函数。LibcInfoWithPatchFunctions的模板参数在我看来没什么用处,tcmalloc默认可以挂钩最多10个带有malloc导出函数的库(我想肯定是够用了)。ThreadCache在每个线程都会有一个TLS对象:
__thread ThreadCache* ThreadCache::threadlocal_heap_。
3、可能的问题
设想下这样一个情景:假如有一个dll 在tcmalloc之前加载,并且在分配了内存(使用crt提供的malloc),那么在加载tcmalloc后,tcmalloc会替换所有的free函数,然后,在某个时刻,
在前面的那个dll代码中释放该内存,这岂不是很危险。实际测试发现没有任何问题,关键在这里:
span = Static::pageheap()->GetDescriptor(p);
if (!span) {
// span can be NULL because the pointer passed in is invalid
// (not something returned by malloc or friends), or because the
// pointer was allocated with some other allocator besides
// tcmalloc. The latter can happen if tcmalloc is linked in via
// a dynamic library, but is not listed last on the link line.
// In that case, libraries after it on the link line will
// allocate with libc malloc, but free with tcmalloc's free.
(*invalid_free_fn)(ptr); // Decide how to handle the bad free request
return;
}
tcmalloc会通过span识别这个内存是否自己分配的,如果不是,tcmalloc会调用该dll原始对应函数(这个很重要)释放。这样就解决了这个棘手的问题。
五、其他
其实tcmalloc使用的每个技术点我从前都用过,但是我从来没想过用API挂钩来实现这样一个有趣的内存优化库(即使想过,也是一闪而过就否定了)。从tcmalloc得到灵感,结合常用的外挂技术,可以很轻松的开发一个独立工具:这个工具可以挂载到指定进程进行内存优化,在我看来,这可能可以作为一个外挂辅助工具来优化那些
内存优化做的很差导致帧速很低的国产游戏。
小内存分配器主要作用是“减小内存碎片化趋势,减小薄记内存比例,提高小内存利用率”,从性能上说,系统内存分配器已针对小内存分配进行优化,单纯使用自定义的小内存分配器,对性能帮助不会很大。内置分配器意义还是体现在,实现无锁分配,避免API调用切换开销。
CRT自身new-delete会用到500个时钟周期,而一个CS会消耗50个时钟周期,一个mutex会用到2000个时钟周期,以上是无竞争的情况。所以,如果用mutex做互斥,那还不如用系统的分配器;如果用CS,也不见会好多少,因为CS会随锁竞争加剧大幅增加时间,甚至会超过mutex。
所以结论是,对于单线程,内置分配器有一定的价值;对于多线程,带锁内置分配器基本上可以无视了(至少对于winxp以后是这样,win2k好像要打补丁)呵呵,从你说的情况来看,很有可能你们原来的分配器用mutex帮倒忙了。
tcmalloc中的唯一亮点应该是,如何做到跨线程归还内存,又能保持高性能,猜想可能使用了某种二级分配策略,内存块可以属于任何线程的内存池,归还到那个线程内存池,就由这个内存池管理。由于各个线程的分配和释放多半不平衡,有线程池会撑满,有的会不足。估计撑满的就会归还到公共内存池。第一级分配无锁,如果内存池不足了,就进入第二级带锁批量分配,而且第二级分配会先从公共内存池获取,如果还不够,这才使用系统内存分配,这该算是第三级分配了。
最后,tcmalloc也是可以用于MT版本的哦,详见(要才能看见)http://groups.google.com/group/google-perftools/browse_thread/thread/41cd3710af85e57b
三、跨平台的USB设备访问C语言库,libusb
libusb的是一个C库,它提供通用的访问USB设备。它支持Linux,Mac OS X,Windows,Windows CE,Android,和OpenBSD/ NetBSD。

版本说明:此版本标志着将libusbx项目合并成libusb。
四、可直接商用的跨平台c,c++动态线程池,任务池stpool库
代码片段(10)[全屏查看所有代码]
1. [文件] libstpool-3.2.rar ~ 4MB 下载(87)
2. [文件] libstpool.2.6.6库+文档+demo.rar ~ 2MB 下载(126)
3. [代码]stpool 线程池,任务池
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
1. 创建一个线程池,服务线程最多不超过5, 预留服务线程为2
hp = stpool_create(5, 2, 0, 10);
2. 往任务池中添加执行任务.
struct
sttask_t *ptsk = stpool_new_task(
"mytask"
, mytask_run, mytask_complete, mytask_arg);
stpool_add_task(hp, ptsk);
或者直接可往线程池中添加一个回调或执行路径
stpool_add_routine(hp, callbak, callback_complete, callback_arg, NULL);
任务添加后,将会被尽快执行. 同时可使用
stpool_task_setschattr(ptsk, &attr);
设置优先级任务,优先级越高的任务越优先调度
3. 等待任务被完成.(stpool 提供对任务的控制,当任务成功加入线程池后,
可以使用stpool_task_wait来等待任务完成,当用户的task_complete被
调用完毕后, stpool_task_wait才返回)
stpool_task_wait(hp, ptask, ms);
4. 暂停线程池(线程池被暂停后,除正在被调度的任务外,线程池将不继续执行任务,
但仍然可以往线程池中添加任务,只是这些任务都处于排队状态)
stpool_suspend(hp, 0).
5. 恢复线程池的运行.
stpool_resume(hp);
6. 禁止用户继续向线程池投递任务(用户调用@tpool_add_task时会返回POOL_ERR_THROTTLE错误码)
tpool_throttle_enable(hp, 1)
7. 等待何时可以投递任务
stpool_throttle_wait(hp, ms);
8. 线程池服务线程数量控制
.) 重新设置线程池最大数量为2,预留线程为0
stpool_adjust_abs(hp, 2, 0);
.)在原来的基础上,将线程池最大服务线程数量+1, 最小数量-1
(这并不代表stpool马上会创建线程,而只是在任务繁重的时候内部精心调度开启)
stpool_adjust(hp, 1, -1)
9. 获取任务池的状态
.)获取stpool内服务线程数目,任务执行情况
struct
stpool_stat_t stat;
stpool_getstat(hp, &stat);
.)获取任务的状态
long
stat = stpool_gettskstat(hp, &mytask);
.) 访问线程池中的所有任务状态
stpool_mark_task(hp, mark_walk, arg)
10.移除所有在等待的任务
stpool_remove_pending_task(hp, NULL);
11.提供引用计数,线程可被其它模块使用,确保线程池对象的生命周期.
第三方模块使用线程池.
stpool_addref(hp)
//保证线程池对象不会被销毁
stpool_adjust(hp, 2, 0);
//添加本模块的需求(增大最大服务线程数+2)
//投递本模块的任务
stpool_release(hp)
//释放线程池
12. 销毁线程池.(当引用计数为0时候,线程池对象会被自动释放,
@stpool_create成功后其用户引用计数为1)
stpool_release(hp)
|
4. [文件] demo-c++.cpp ~ 3KB 下载(12)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
/* COPYRIGHT (C) 2014 - 2020, piggy_xrh */
#include
using
namespace
std;
#include "CTaskPool.h"
#ifdef _WIN
#ifdef _DEBUG
#ifdef _WIN64
#pragma comment(lib, "../../../lib/Debug/x86_64_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Debug/x86_64_win/libstpool.lib")
#pragma comment(lib, "../../../lib/Debug/x86_64_win/libstpoolc++.lib")
#else
#pragma comment(lib, "../../../lib/Debug/x86_32_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Debug/x86_32_win/libstpool.lib")
#pragma comment(lib, "../../../lib/Debug/x86_32_win/libstpoolc++.lib")
#endif
#else
#ifdef _WIN64
#pragma comment(lib, "../../../lib/Release/x86_64_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Release/x86_64_win/libstpool.lib")
#pragma comment(lib, "../../../lib/Release/x86_64_win/libstpoolc++.lib")
#else
#pragma comment(lib, "../../../lib/Release/x86_32_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Release/x86_32_win/libstpool.lib")
#pragma comment(lib, "../../../lib/Release/x86_32_win/libstpoolc++.lib")
#endif
#endif
#endif
/* (log library) depends (task pool library) depends (task pool library for c++)
* libmsglog.lib <-------------libstpool.lib <--------------------libstpoolc++.lib
*/
class
myTask:
public
CTask
{
public
:
/* We can allocate a block manually for the proxy object.
* and we can retreive its address by @getProxy()
*/
myTask(): CTask(
/*new char[getProxySize()]*/
NULL,
"mytask"
) {}
~myTask()
{
/* NOTE: We are responsible for releasing the proxy object if
* the parameter @cproxy passed to CTask is NULL */
if
(isProxyCreatedBySystem())
freeProxy(getProxy());
else
delete
[]
reinterpret_cast
<
char
*>(getProxy());
}
private
:
virtual
int
onTask()
{
cout << taskName() <<
": onTask.\n"
;
return
0;
}
virtual
void
onTaskComplete(
long
sm,
int
errCode)
{
if
(CTask::sm_DONE & sm)
cout << taskName() <<
" has been done with code:"
<< dec << errCode
<<
" stat:0x"
<< hex << stat() <<
" sm:0x"
<< sm << endl;
else
cerr << taskName() <<
" has not been done. reason:"
<< dec << errCode
<<
" stat:0x"
<< hex << stat() <<
" sm:0x"
<< sm << endl;
static
int
slTimes = 0;
/* We reschedule the task again.
* NOTE:
* task->wait() will not return until the task
* does not exist in both the pending pool and the
* scheduling queue.
*/
if
(++ slTimes < 5)
queue();
/* The task will be marked with @sm_ONCE_AGAIN if user calls
* @queue to reschedule it while it is being scheduled. and
* @sm_ONCE_AGAIN will be removed by the pool after it having
* been delived into the pool. */
cout << dec << slTimes <<
" sm:0x"
<< hex <<
this
->sm() << endl << endl;
}
};
int
main()
{
/* Create a pool instance with 1 servering thread */
CTaskPool *pool = CTaskPool::createInstance(1, 0,
false
);
/* Test running the task */
myTask *task =
new
myTask;
/* Set the task's parent before our's calling @queue */
task->setParent(pool);
/* Deliver the task into the pool */
task->queue();
/* Wait for the task's being done */
task->wait();
cout <<
"\ntask has been done !"
<< endl;
/* Free the task object */
delete
task;
/* Shut down the pool */
pool->release();
cin.get();
return
0;
}
|
5. [图片] linux_win_demo-c++.png
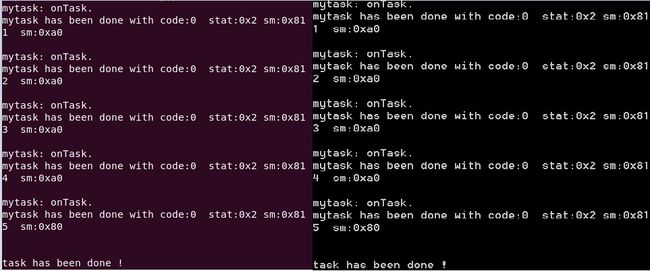
6. [文件] demo-sche.c ~ 3KB 下载(8)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
/* COPYRIGHT (C) 2014 - 2020, piggy_xrh */
#include
#include "stpool.h"
#ifdef _WIN
#ifdef _DEBUG
#ifdef _WIN64
#pragma comment(lib, "../../../lib/Debug/x86_64_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Debug/x86_64_win/libstpool.lib")
#else
#pragma comment(lib, "../../../lib/Debug/x86_32_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Debug/x86_32_win/libstpool.lib")
#endif
#else
#ifdef _WIN64
#pragma comment(lib, "../../../lib/Release/x86_64_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Release/x86_64_win/libstpool.lib")
#else
#pragma comment(lib, "../../../lib/Release/x86_32_win/libmsglog.lib")
#pragma comment(lib, "../../../lib/Release/x86_32_win/libstpool.lib")
#endif
#endif
#else
#include
#include
#endif
/* (log library) depends (task pool library)
* libmsglog.lib <-------------libstpool.lib
*/
static
void
do_work(
int
*val) {
*val += 100;
*val *= 0.371;
}
int
task_run(
struct
sttask_t *ptsk) {
size_t
i, j, sed = 20;
for
(i=0; i
for
(j=0; j
do_work((
int
*)ptsk->task_arg);
/* Do not call @printf in the test since it will waste our
* so much time on competing the IO.
*/
return
0;
}
void
task_complete(
struct
sttask_t *ptsk,
long
vmflags,
int
code) {
}
int
main()
{
time_t
now;
int
i, c, times, j=0;
int
sum, *arg;
HPOOL hp;
/* Creat a task pool */
hp = stpool_create(50,
/* max servering threads */
0,
/* 0 servering threads that reserved for waiting for tasks */
1,
/* suspend the pool */
0);
/* default number of priority queue */
printf
(
"%s\n"
, stpool_status_print(hp, NULL, 0));
/* Add tasks */
times = 90000;
arg = (
int
*)
malloc
(times *
sizeof
(
int
));
for
(i=0; i
/* It may take a long time to load a large amount of tasks
* if the program is linked with the debug library */
if
(i % 4000 == 0 || (i + 1) ==times) {
printf
(
"\rLoading ... %.2f%% "
, (
float
)i * 100/ times);
fflush
(stdout);
}
arg[i] = i;
stpool_add_routine(hp,
"sche"
, task_run, task_complete, (
void
*)&arg[i], NULL);
}
printf
(
"\nAfter having executed @stpool_add_routine for %d times:\n"
"--------------------------------------------------------\n%s\n"
,
times, stpool_status_print(hp, NULL, 0));
printf
(
"Press any key to resume the pool.\n"
);
getchar
();
/* Wake up the pool to schedule tasks */
stpool_resume(hp);
stpool_task_wait(hp, NULL, -1);
/* Get the sum */
for
(i=0, sum=0; i
sum += arg[i];
free
(arg);
now =
time
(NULL);
printf
(
"--OK. finished.
,
sum,
ctime
(&now), stpool_status_print(hp, NULL, 0));
#if 0
/* You can use debug library to watch the status of the pool */
while
(
'q'
!=
getchar
()) {
for
(i=0; i<40; i++)
stpool_add_routine(hp,
"debug"
, task_run, NULL, &sum, NULL);
}
/* Clear the stdio cache */
while
((c=
getchar
()) && c !=
'\n'
&& c != EOF)
;
#endif
getchar
();
/* Release the pool */
printf
(
"Shut down the pool now.\n"
);
stpool_release(hp);
getchar
();
return
0;
}
|
7. [图片] win32_linux_demo_sche1.jpg

8. [图片] win32_linux_demo_sche2.jpg
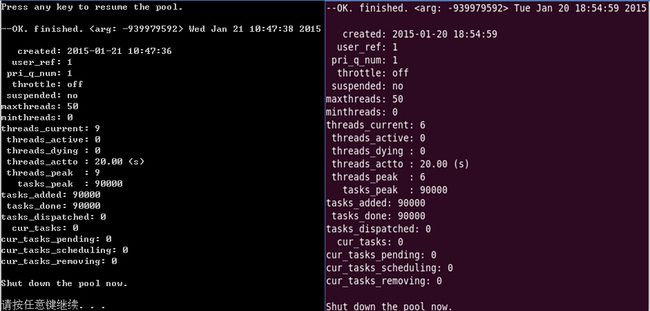
9. [代码]demo-sche结果分析
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
线程和任务峰值统计(现仅统计win32/linux)
win32(xp) linux(ubuntu 10.04)
----------------------------------------------------
threads_peak: 9 threads_peak: 6
tasks_peak: 90000 tasks_peak: 90000
------------------------------------------------------
完成90000个任务,stpool最高峰线程数目为9(win32),6(linux),根据任务
执行情况智能调度任务,90000个任务都在1s内完成.
(ubuntu为xp的vmware虚拟机, 运行设置为2核2线程)
root@ubuntu_xrh:~/localhost/task/stpool# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 42
model name : Intel(R) Pentium(R) CPU G620 @ 2.60GHz
stepping : 7
cpu MHz : 2594.108
cache size : 3072 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss nx rdtscp constant_tsc arch_perfmon pebs bts xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 sse4_1 sse4_2 popcnt hypervisor arat
bogomips : 5188.21
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits
virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 42
model name : Intel(R) Pentium(R) CPU G620 @ 2.60GHz
stepping : 7
cpu MHz : 2594.108
cache size : 3072 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss nx rdtscp constant_tsc arch_perfmon pebs bts xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 sse4_1 sse4_2 popcnt hypervisor arat
bogomips : 5188.21
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits
virtual
power management:
|
10. [文件] demo.c ~ 7KB 下载(9)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|