Mycat使用
文章目录
- Mycat使用
- 主从复制
- 进入正题
- 概述
- 安装使用
- 读写分离
- 垂直分库
- 水平分表
- 关联表
- 分表小结
- 全局序列
- 数据库方式
- 自主生成
Mycat使用
主从复制
复制的基本原理
slave 会从master 读取 binlog 来进行数据同步
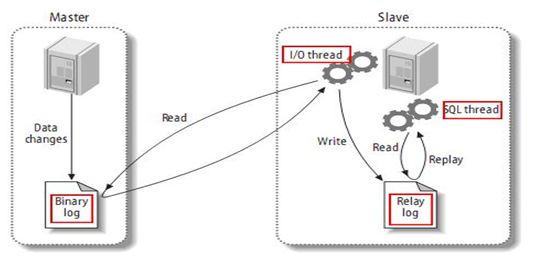
- master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events
- slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- slave 重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL 复制是异步的且串行化的
复制的基本原则
- 每个 master 可以有多个 salve
- 每个 slave 只有一个 master
- 每个 slave 只能有一个唯一的服务器 ID
配置思路

- 配置主机,win的 my.ini,注意是:
[mysqld]下
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
server-id=1
log-bin=自己本地的路径/data/mysqlbin #自定义的路径
binlog-ignore-db=mysql
binlog-do-db=需要复制的主数据库名字
binlog_format=STATEMENT
binlog_format 有三种:STATEMENT(默认,记录写操作sql,函数调用会出错)、ROW(记录每行变化,效率问题)、MIXED(有函数切换到R,无函数切换到S,有系统变量会出错)
- 从机,修改 Linux 中的 my.cnf(/etc 目录)
[mysqld]
#加入这些
server-id = 2
relay-log=mysql-relay
- 重启,模拟时关闭防火墙
- 在 Windows 主机上建立帐户并授权 slave,查看
执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
GRANT REPLICATION SLAVE ON *.* TO 'zhangsan'@'从机器数据库IP' IDENTIFIED BY '123456';
show master status;
- 在Linux 从机上配置需要复制的主机
CHANGE MASTER TO MASTER_HOST='主机IP',
MASTER_USER='zhangsan',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='File名字',
MASTER_LOG_POS=Position数字;
start slave;
show slave status\G;# 查看是否配置成功
主机新建库、新建表、insert记录,从机复制
进入正题
概述
是什么?
Mycat 是数据库中间件,前身是阿里的 cobar,属于 proxy 层方案。
拓展:sharding-jdbc:当当开源的,属于 client 层方案。
能够干什么?
- 读写分离
- 数据分片
- 垂直拆分
- 水平拆分
- 垂直+水平拆分
- 多数据源整合
原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,
- 首先对 SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,
- 然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,
- 最终再返回给用户
所以,我们只要配置 mycat,它会拦截,自动发给对应服务器处理

安装使用
下载地址:http://www.mycat.org.cn/
修改配置文件
- schema.xml:定义逻辑库,表、分片节点等内容
- rule.xml:定义分片规则
- server.xml:定义用户以及系统相关变量,如端口等.
启动前先修改 schema.xml
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
writeHost>
dataHost>
mycat:schema>
再修改 server.xml
<user name="root">
<property name="password">654321property>
<property name="schemas">TESTDBproperty>
user>
验证数据库访问情况:
mysql -uroot -p123123 -h 192.168.154.1 -P 3306
mysql -uroot -p123123 -h 192.168.154.154 -P 3306
# 如本机远程访问报错,请建对应用户
grant all privileges on *.* to root@'缺少的host' identified by '123123';
启动程序:
- 控制台启动 :去mycat/bin 目录下 mycat console
- 后台启动 :去mycat/bin 目录下 mycat start
启动时可能出现报错:域名解析失败
- 用 vim 修改 /etc/hosts 文件 (在 127.0.0.1 后面增加你的机器名)
- 修改后重新启动网络服务 service network restart
登录:
- 后台管理窗口
- mysql -uroot -p654321 -P9066 -h192.168.67.131
- show database
- show @@help
- 数据窗口
- mysql -uroot -p654321 -P8066 -h192.168.67.131
读写分离
注意:必须完成主从复制的搭建,才能实现读写分离

配置 schema.xml,在前面的基础上加了读库配置
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
schema>
<dataNode name="dn1" dataHost="host1" database="atguigu_mc" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm1" url="192.168.67.1:3306" user="root"
password="123123">
<readHost host="hosts1" url="192.168.67.131:3306" user="root"
password="123123">
readHost>
writeHost>
dataHost>
mycat:schema>
负载均衡类型,目前的取值有4 种:
balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。balance="2",所有读操作都随机的在 writeHost、readhost 上分发。balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
读写分离:
- 创建表 t_replica
- 分别在两个库下插入:
insert into t_replica(name) values (@@hostname) - 然后再 mycat下执行 select * from t_replica 查询实验
垂直分库
一个库的瓶颈约为 5kw,一个表的瓶颈约为 500w
水平与垂直拆分
- 水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
- 垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。
场景
有一个库,
- #客户表 rows:20万
- #订单表 rows:600万
- #订单详细表 rows:600万
- #订单状态字典表 rows:20万
垂直分库操作
- 搭建两个干净的库,通过 mycat 做分库操作
- 拆分时需注意 join 关联情况要避免

配置 schema.xml
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" >table>
schema>
<dataNode name="dn1" dataHost="host1" database="atguigu_mc" />
<dataNode name="dn2" dataHost="host2" database="atguigu_sm" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm1" url="192.168.67.1:3306" user="root"
password="123123">
<readHost host="hosts1" url="192.168.67.131:3306" user="root"
password="123123">
readHost>
writeHost>
dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm2" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
mycat:schema>
若未建立新分库,则会报错哦
水平分表
水平分表
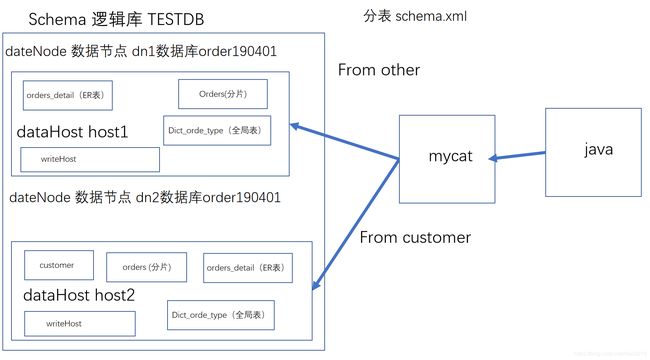
- 我们拆分 order 表
修改 schema.xml
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" >table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" >table>
schema>
<dataNode name="dn1" dataHost="host1" database="atguigu_mc" />
<dataNode name="dn2" dataHost="host2" database="atguigu_sm" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="2"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm1" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm2" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
修改 rule.xml
<tableRule name="mod_rule">
<rule>
<columns>customer_idcolumns>
<algorithm>mod-longalgorithm>
rule>
tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2property>
function>
关联表
跨库无法 join 查询,那关联表(订单详情表)怎么拆呢?
配置 ER 表:为了相关联的表的行尽量分在一个库下,这里就是订单详情表的配置
配置 schema.xml
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" >table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" >
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
table>
<table name="dict_status" dataNode="dn1,dn2" type="global" >table>
schema>
<dataNode name="dn1" dataHost="host1" database="atguigu_mc" />
<dataNode name="dn2" dataHost="host2" database="atguigu_sm" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="2"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm1" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm2" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
mycat:schema>
全局表:每个库都会使用的表,一般数据量不会过大,这里就是订单状态字典表的配置
- 设定为全局的表,会直接复制给每个数据库一份,所有写操作也会同步给多个库。
- 所以全局表一般不能是大数据表或者更新频繁的表
- 一般是字典表或者系统表为宜。
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" >table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" >table>
<table name="dict_order_type" dataNode="dn1,dn2" type="global" >table>
schema>
<dataNode name="dn1" dataHost="host1" database="atguigu_mc" />
<dataNode name="dn2" dataHost="host2" database="atguigu_sm" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="2"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm1" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()heartbeat>
<writeHost host="hostm2" url="192.168.67.1:3306" user="root"
password="123123">
writeHost>
dataHost>
分表小结
- 直接根据 rule 算法分表:如订单表
- ER 表(childTable):如订单详情表 随着订单表
连带分 - 全局表:每个库都会复制的表,如字典表、系统表
全局序列
用于:保证配置多个节点时,如订单 id 不会重复
几种方式:
- 本地文件:不推荐,抗风险能力太差
- 时间戳方式:不推荐,太长了
- 数据库方式
数据库方式
原理
- 利用数据库一个表 来进行计数累加。
- 但是并不是每次生成序列都读写数据库,这样效率太低
- mycat 会预加载一部分号段到 mycat 的内存中,这样大部分读写序列都是在内存中完成的。
- 如果内存中的号段用完了 mycat会再向数据库要一次。
那如果mycat崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果mycat重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复。
建库序列脚本
脚本:
win10
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER;
测试:
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOT
NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;
SELECT * FROM MYCAT_SEQUENCE
TRUNCATE TABLE MYCAT_SEQUENCE
##增加要用的序列
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,
100);
修改 mycat 配置
- vim sequence_db_conf.properties ,修改序列对应的节点,参考schema.xml
- vim server.xml,改成1,使用数据库方式
<property name="sequnceHandlerType">1<property>
自主生成
- 根据业务逻辑组合
- 可以利用 redis 的单线程原子性 incr来生成序列