并行计算——OpenMP加速矩阵相乘
OpenMP是一套基于共享内存方式的多线程并发编程库。第一次接触它大概在半年前,也就是研究cuda编程的那段时间。OpenMP产生的线程运行于CPU上,这和cuda不同。由于GPU的cuda核心非常多,可以进行大量的并行计算,所以我们更多的谈论的是GPU并行计算(参见拙文《浅析GPU计算——CPU和GPU的选择》和《浅析GPU计算——cuda编程》)。本文我们将尝试使用OpenMP将CPU资源榨干,以加速计算。(转载请指明出于breaksoftware的csdn博客)
并行计算的一个比较麻烦的问题就是数据同步,我们使用经典的矩阵相乘来绕开这些不是本文关心的问题。
环境和结果
我的测试环境是:
- CPU:Intel Core i7 4790。主频3.6G,4核8线程,8MB三级缓存,集成HD4600核显。
- 内存:16G
- 操作系统:Windows7 64bit
测试的程序是:
- 32位Release版
- 4096*2048和2048*4096两个矩阵相乘
- 非并行版本直接计算
- 并行版本使用OpenMP库开启8个线程
基础环境
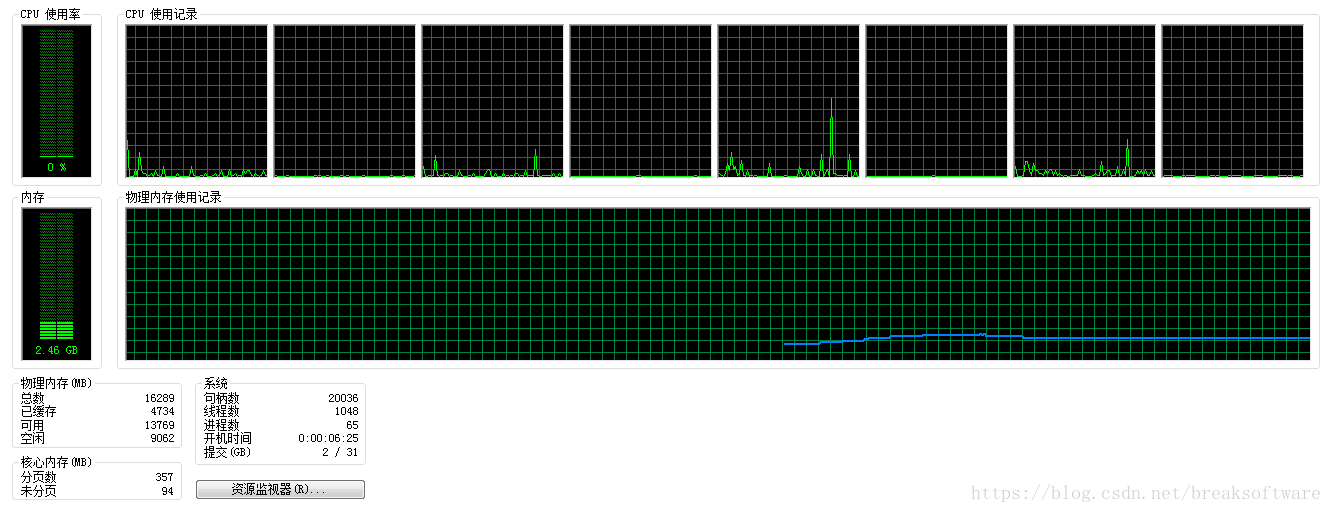
CPU基本处在1%左右,抖动频率很低。
非并行计算
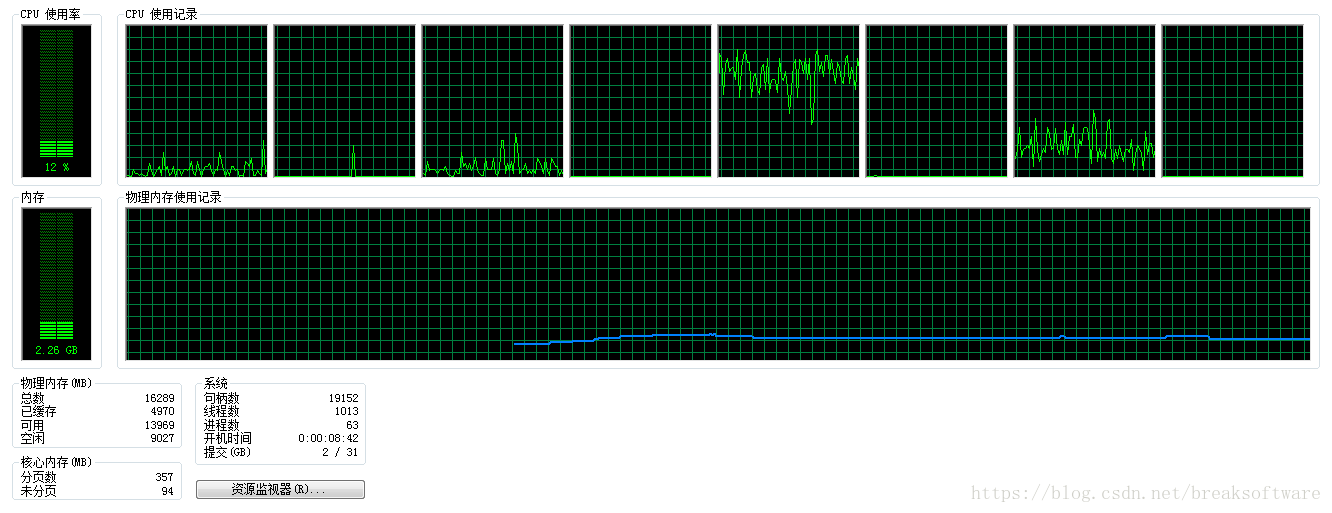
由于是4核8线程,所以CPU最高处在12%(100% 除以8),而且有抖动。
并行计算
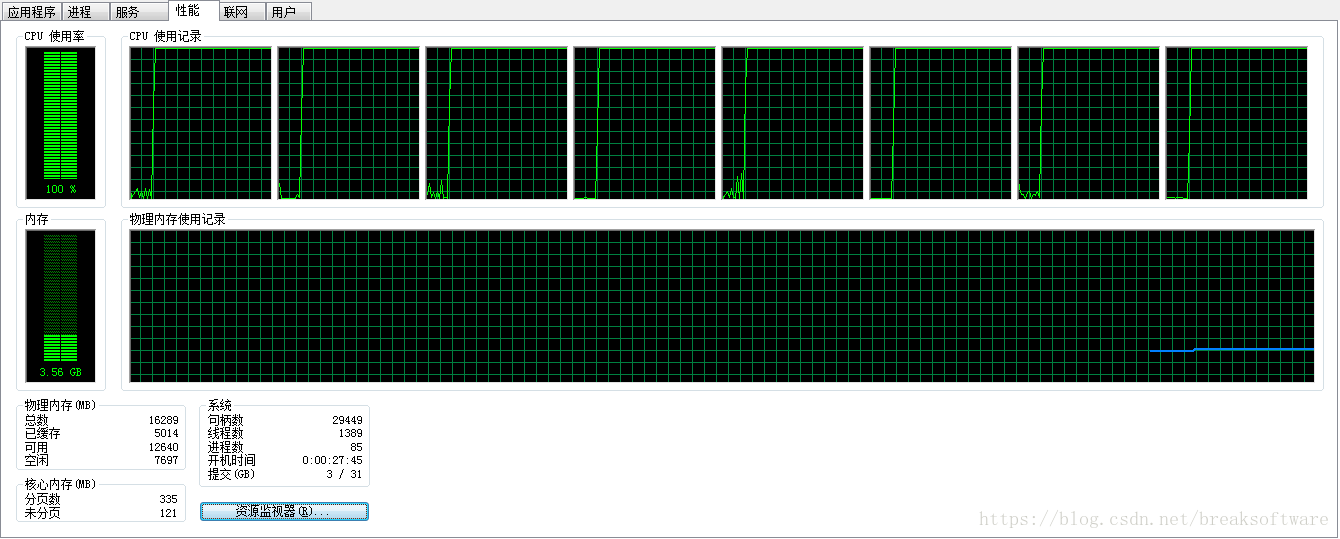
CPU资源被占满,长期处在100%状态。
时间对比
- 非并行计算:243,109ms
- 并行计算:68,800ms
可见,在我这个环境下,并行计算将速度提升了4倍。
测试代码
构建初始矩阵
auto left = std::make_unique >(4096, 2048);
auto right = std::make_unique >(2048, 4096);
left->fill([](size_t x, size_t y) -> decltype(x * y) {return (x + 1) * (y + 1); });
right->fill([](size_t x, size_t y) -> decltype(x * y) {return (x + 1) * (y + 1); }); Matrix是我定义的一个矩阵类,之后会列出代码。
非并行计算
std::vector result;
result.resize(left->get_height() * right->get_width());
{
Perform p;
for (size_t i = 0; i < left->get_height(); i++) {
RowMatrix row(*left, i);
for (size_t j = 0; j < right->get_width(); j++) {
ColumnMatrix column(*right, j);
auto x = std::inner_product(row.begin(), row.end(), column.begin(), 0);
result[i * right->get_width() + j] = x;
}
}
} result用于保存矩阵相乘的计算结果。
RowMatrix和ColumnMatrix是我将矩阵分拆出来的行矩阵和列矩阵。这么设计是为了方便设计出两者的迭代器,使用std::inner_product方法进行计算。
Perform是我统计代码段耗时的工具类。其实现可以参见《C++拾取——使用stl标准库实现排序算法及评测》。
并行计算
std::vector result_parallel;
result_parallel.resize(left->get_height() * right->get_width());
{
Perform p;
omp_set_dynamic(0);
#pragma omp parallel default(shared) num_threads(8)
{
int iam = omp_get_thread_num();
int nt = omp_get_num_threads();
for (size_t i = 0; i < left->get_height(); i++) {
if (i % nt != iam) {
continue;
}
RowMatrix row(*left, i);
for (size_t j = 0; j < right->get_width(); j++) {
ColumnMatrix column(*right, j);
auto x = std::inner_product(row.begin(), row.end(), column.begin(), 0);
result_parallel[i * right->get_width() + j] = x;
}
}
}
} 只增加了7行代码。
第6行,使用omp_set_dynamic关闭OpenMP动态调整线程数。
第7行,告诉OpenMP启动8个线程执行下面区块中的逻辑。
第9行,通过omp_get_thread_num()当前线程在OpenMP中的ID。该ID从0开始递增。
第10行,通过omp_get_num_threads()获取并行执行的线程数。由于第6行和第7行的设置,本例中其值将为8。
第13~15行,分拆任务。这样可以保证每个线程可以不交叉的运算各自的区域。
仅仅7行代码,将程序的计算能力提升了4倍!还是很值得的。
矩阵代码
用于测试的代码比较短小,但是为了支持这个短小的测试代码,我还设计了5个类。
矩阵
template
class Matrix {
public:
Matrix(size_t x, size_t y) : _width(x), _heigth(y) {
assert(x != 0 && y != 0);
size_t size = x * y;
_vec.resize(size);
}
Matrix() = delete;
public:
void fill(std::function fn) {
for (size_t i = 0; i < _heigth; i++) {
for (size_t j = 0; j < _width; j++) {
_vec.at(i * _width + j) = fn(i, j);
}
}
}
public:
const T* get_row_start(size_t row_num) const {
assert(row_num < _heigth);
return &_vec.at(row_num * _width);
}
const T* get_row_end(size_t row_num) const {
assert(row_num < _heigth);
return &_vec.at((row_num + 1) * _width);
}
const T* get_row_data(size_t row_num, size_t index) const {
return &_vec.at(row_num * _width + index);
}
const T* get_column_start(size_t column_num) const {
assert(column_num < _width);
return &_vec.at(column_num);
}
const T* get_column_end(size_t column_num) const {
assert(column_num < _width);
return &_vec.at(_heigth * _width + column_num);
}
const T* get_column_data(size_t column_num, size_t index) const {
return &_vec.at(index * _width + column_num);
}
public:
const size_t get_width() const {
return _width;
}
const size_t get_height() const{
return _heigth;
}
private:
std::vector _vec;
size_t _width;
size_t _heigth;
}; 行矩阵和其迭代器
template class RowMatrixIterator;
template
class RowMatrix {
friend class RowMatrixIterator;
public:
RowMatrix(const Matrix& matrix, size_t row_num) {
_p = &matrix;
_row_num = row_num;
}
RowMatrix() = delete;
public:
RowMatrixIterator begin() {
RowMatrixIterator begin_it(*this);
begin_it._index = 0;
return begin_it;
}
RowMatrixIterator end() {
RowMatrixIterator end_it(*this);
end_it._index = _p->get_width();
return end_it;
}
private:
const T* row_offset(size_t index) const {
return _p->get_row_data(_row_num, index);
}
protected:
const Matrix* _p;
size_t _row_num = 0;
};
template
class RowMatrixIterator : public std::iterator {
friend class RowMatrix;
public:
explicit RowMatrixIterator(RowMatrix& row) : _row(row), _index(0) {
}
RowMatrixIterator& operator=(const RowMatrixIterator& src) {
_row = src._row;
_index = src._index;
}
const T& operator*() {
return *_row.row_offset(_index);
}
RowMatrixIterator& operator++() {
++_index;
return *this;
}
RowMatrixIterator& operator++(int) {
auto temp = RowMatrixIterator(*this);
_index++;
return std::move(std::ref(temp));
}
bool operator<(const RowMatrixIterator& iter) const {
return _index < iter._index;
}
bool operator==(const RowMatrixIterator& iter) const {
return _index == iter._index;
}
bool operator!=(const RowMatrixIterator& iter) const {
return _index != iter._index;
}
bool operator>(const RowMatrixIterator& iter) const {
return _index > iter._index;
}
bool operator<=(const RowMatrixIterator& iter) const {
*this < iter || *this == iter;
}
bool operator>=(const RowMatrixIterator& iter) const {
*this > iter || *this == iter;
}
protected:
RowMatrix& _row;
size_t _index;
}; 列矩阵和其迭代器
template class ColumnMatrixIterator;
template
class ColumnMatrix {
friend class ColumnMatrixIterator;
public:
ColumnMatrix(const Matrix& matrix, size_t column_num) {
_p = &matrix;
_column_num = column_num;
}
ColumnMatrix() = delete;
public:
ColumnMatrixIterator begin() {
ColumnMatrixIterator begin_it(*this);
begin_it._index = 0;
return begin_it;
}
ColumnMatrixIterator end() {
ColumnMatrixIterator end_it(*this);
end_it._index = _p->get_height();
return end_it;
}
private:
const T* column_offset(size_t index) const {
return _p->get_column_data(_column_num, index);
}
protected:
const Matrix* _p;
size_t _column_num = 0;
};
template
class ColumnMatrixIterator : public std::iterator {
friend class ColumnMatrix;
public:
explicit ColumnMatrixIterator(ColumnMatrix& Column) : _p(Column), _index(0) {
}
ColumnMatrixIterator& operator=(const ColumnMatrixIterator& src) {
_p = src._p;
_index = src._index;
}
const T& operator*() {
return *_p.column_offset(_index);
}
ColumnMatrixIterator& operator++() {
++_index;
return *this;
}
ColumnMatrixIterator& operator++(int) {
auto temp = ColumnMatrixIterator(*this);
_index++;
return std::move(std::ref(temp));
}
bool operator<(const ColumnMatrixIterator& iter) const {
return _index < iter._index;
}
bool operator==(const ColumnMatrixIterator& iter) const {
return _index == iter._index;
}
bool operator!=(const ColumnMatrixIterator& iter) const {
return _index != iter._index;
}
bool operator>(const ColumnMatrixIterator& iter) const {
return _index > iter._index;
}
bool operator<=(const ColumnMatrixIterator& iter) const {
*this < iter || *this == iter;
}
bool operator>=(const ColumnMatrixIterator& iter) const {
*this > iter || *this == iter;
}
protected:
ColumnMatrix& _p;
size_t _index;
};