php模拟面试——redis篇
set、setx、setex 命令区别?
set命令,将key-value 设置到数据库。若key已经设置,则set会用新值覆盖旧值,不管原value是何种类型,如果在设置时不指定EX或PX参数,set命令会清除原有超时时间。
setx命令,将key-value设置到数据库,并且指定key的超时秒数。
setnx命令,将key-value设置到数据库,当且仅当key不存在时。
如何找redis中特定的key?
keys、scan。
keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,所有读写 Redis 的其它的指令都会被延后甚至会超时报错,因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完了才可以继续。
scan的出现就是为了解决这些问题。
scan相比keys 具备有以下特点:
1、复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程;
2、提供 limit 参数,可以控制每次返回结果的最大条数,limit 只是一个 hint,返回的结果可多可少;
3、同 keys 一样,它也提供模式匹配功能;
4、服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
5、返回的结果可能会有重复,需要客户端去重复,这点非常重要;
6、遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
7、单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零;
描述下redis 的管道pipeline?
pipeline 是由客户端提供的,而非服务器。
当我们使用客户端对 Redis 进行一次操作时,客户端将请求传送给服务器,服务器处理完毕后,再将响应回复给客户端。这要花费一个网络数据包来回的时间。
如果执行多条指令就会花费多个来回时间。pipeline 可使得来读写,变成连续write 再连续read。
客户端对管道中的指令列表改变读写顺序就可以大幅节省IO时间。管道指令越多,效果越好。
lpop/rpop 跟 blpop/brpop的区别?
lpop/rpop 在队列空了以后,会陷入pop的死循环,不停地pop,没有数据,接着再pop,有没有数据。这种空轮询会拉高客户端CPU
,redis 的qps也会被拉高,假设空轮询的客户端比较多,Redis慢查询会变多。
blpop/brpop 其中b表示blocking,阻塞读。没有数据的时候,会立即进入休眠状态,数据到来,即刻醒来。消息的延迟几乎为零。
如果线程一直阻塞在哪里,Redis 的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候blpop/brpop会抛出异常来。所以编写客户端消费者的时候要小心,注意捕获异常,还要重试。
延时队列如何实现?
可用zset (有序列表)实现。消息序列化成一个字符串作为 zset 的value,这个消息的到期处理时间作为score,然后用多个线程轮询 zset 获取到期的任务进行处理,多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处理。因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。
上面的算法中同一个任务可能会被多个进程取到之后再使用zrem进行争抢,那些没抢到的进程都是白取了一次任务,这是浪费。可以考虑使用lua scripting来优化一下这个逻辑,将zrangebyscore和zrem一同挪到服务器端进行原子化操作,这样多个进程之间争抢任务时就不会出现这种浪费了。
控制用户行为,避免垃圾请求,这种限流如何实现?
第一种:zset
这个限流需求中存在一个滑动时间窗口,想想 zset 数据结构的 score 值,是不是可以通过 score 来圈出这个时间窗口来。而且我们只需要保留这个时间窗口,窗口之外的数据都可以砍掉。那这个 zset 的 value 填什么比较合适呢?它只需要保证唯一性即可,用 uuid 会比较浪费空间,那就改用毫秒时间戳吧。
zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。
因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
漏斗算法,redis-cell模块
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令
Redis 如何做锁?
setnx 、expire实现有个问题,setnx和expire之间服务器进程突然挂掉了,expire得不到执行,也会造成死锁。根源就在于 setnx 和 expire 是两条指令而不是原子指令。如果这两条指令可以一起执行就不会出现问题。
解决办法,redis 2.8 作者加入了set指令的扩展参数nx、ex,使得setnx和expire指令可以一起执行,解决了分布式锁的乱象。
超时问题
Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。因为这时候锁过期了,第二个线程重新持有了这把锁,但是紧接着第一个线程执行完了业务逻辑,就把锁给释放了,第三个线程就会在第二个线程逻辑执行完之间拿到了锁。
有一个更加安全的方案是为 set 指令的 value 参数设置为一个随机数,释放锁时先匹配随机数是否一致,然后再删除 key。但是匹配 value 和删除 key 不是一个原子操作,Redis 也没有提供类似于delifequals这样的指令,这就需要使用 Lua 脚本来处理了,因为 Lua 脚本可以保证连续多个指令的原子性执行。
参考代码:https://github.com/ronnylt/redlock-php/blob/master/src/RedLock.php
集群下的分布式锁
Redlock 算法
为了使用 Redlock,需要提供多个 Redis 实例,这些实例之前相互独立没有主从关系。同很多分布式算法一样,redlock 也使用「大多数机制」。
加锁时,它会向过半节点发送 set(key, value, nx=True, ex=xxx) 指令,只要过半节点 set 成功,那就认为加锁成功。释放锁时,需要向所有节点发送 del 指令。不过 Redlock 算法还需要考虑出错重试、时钟漂移等很多细节问题,同时因为 Redlock 需要向多个节点进行读写,意味着相比单实例 Redis 性能会下降一些。
如果你很在乎高可用性,希望挂了一台 redis 完全不受影响,那就应该考虑 redlock。不过代价也是有的,需要更多的 redis 实例,性能也下降了,代码上还需要引入额外的 library,运维上也需要特殊对待,这些都是需要考虑的成本,使用前请再三斟酌。
Redis单线程为什么那么快?线程IO模型是什么?
所有数据都在内存中,所有的运算都是内存级的运算。但正因为是单线程,要小心使用Redis指令,对于那些时间复杂度为O(n)级别的指令,要谨慎使用,一不小心可能会导致Redis卡顿。
事件轮询(多路复用)采用 epoll(linux)和kqueue(freebsd & macosx)。
持久化有方式是?
RDB快照:
快照有两种触发方式,其一为通过配置参数,比如save 60 1000 则在60秒内如果有1000个key发生变化,会触发一次RDB快照的执行。
其二是客户端执行bgsave命令,显示触发一次RDB快照执行。
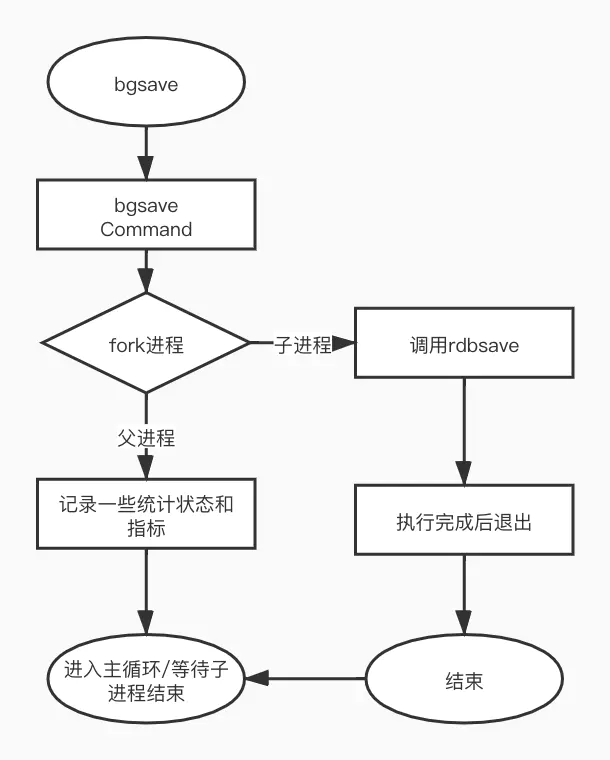
bgsave执行流程
AOF:
将Redis服务端执行过的每一条命令都保存到一个文件,Redis重启时只要按顺序回放这些命令就会恢复到原始状态。
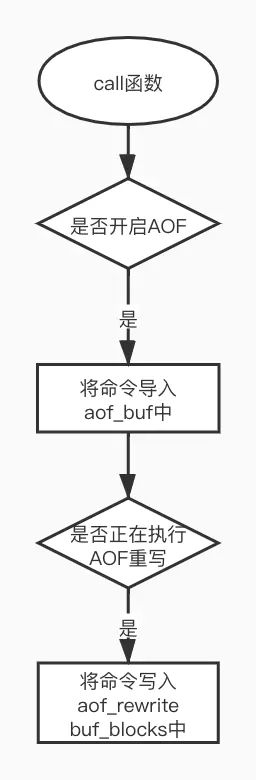
AOF命令同步
为什么有了RDB还要有AOF?
RDB保存的是一个时间点的快照,如果redis故障,丢的数据是最后一次rdb执行时间到故障发生的时间间隔之内的数据。RDB恢复数据只需要把响应的数据加载到内存并生成相应的数据结构。
AOF保存的是一条条命令,理论上可做到发生故障只丢失一条命令。AOF安全性高,但是会造成AOF文件过大(优化方式对AOF重写)并且加载时速度过慢。AOF恢复数据需要创建一个伪客户端,然后把一条条命令发给Redis服务端。
AOF跟RDB各有优缺点,Redis会同时开启AOF重写会加快。
Redis4.0新增了,混合持久化。rdb跟aof存在一起。aof不再是全量日志,而是自持久化到持久化结束这段时间的增量aof日志。Redis重启时,可先加载rdb内容,再重放增量AOF日志可替代AOF全量文件重放了,重启效率大幅提升。
如果机器突然宕机,AOF日志没有完全刷到磁盘中,这时出现日志丢失,怎么办?
glibc提供了fsync(int fd)函数,可将指定文件内容强制从内核缓存刷到磁盘。故redis进程实时调用fsync可保证aof日志不丢失。但fsync是磁盘IO操作,慢,若每执行一条指令就fsync,Redis高性能不起来了。故,redis通常每隔1秒(可配置)一次fsync。
redis的集群模式是?
1.Sentinel
2.Codis
3.Cluster
redis 中LRU的实现方式?
phpredis中的connect和pconnect的区别
内容来源:
- 《Redis深度历险: 核心原理和应用实践》
- 《Redis5 设计与源码分析》
作者:言十年
链接:https://www.jianshu.com/p/7c600a75a4e7
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。