Release 崩溃 ,Debug 不崩?
原文转载于:https://www.jianshu.com/p/b203b2cb313b?hmsr=toutiao.io
Release 崩溃 Debug 不崩?
在夸克2.0版本,出现一个在release 下必崩的问题。经过一轮排查,终于发现问题的根源所在。排查过程相当耗时,故记录下来,方便以后学习。
排查过程比较冗长。看不下的,可以直接查看结论。
0x1 崩溃日志
Exception Type: SIGSEGV
Exception Codes: SEGV_ACCERR at 0x0
Crashed Thread: 1
Thread 1 Crashed:
0 libobjc.A.dylib 0x0000000189f35e34 (anonymous namespace)::AutoreleasePoolPage::pop(void*) + 68
1 Quark 0x0000000100590494 __65-[CMSDataModel saveSubRes:resCode:subResUrl:decompress:callback:]_block_invoke (CMSDataModel.mm:258)
2 libdispatch.dylib 0x000000018a36e9e0 _dispatch_call_block_and_release + 24
3 libdispatch.dylib 0x000000018a36e9a0 _dispatch_client_callout + 16
4 libdispatch.dylib 0x000000018a37d0d4 _dispatch_queue_override_invoke + 644
5 libdispatch.dylib 0x000000018a37ea50 _dispatch_root_queue_drain + 540
6 libdispatch.dylib 0x000000018a37e7d0 _dispatch_worker_thread3 + 124
7 libsystem_pthread.dylib 0x000000018a577100 _pthread_wqthread + 1096
8 libsystem_pthread.dylib 0x000000018a576cac start_wqthread + 4
从崩溃日志知道,崩溃发生的原因是访问了无效的地址0x0(SIGSEGV),查看崩溃的调用现场,很直接,崩溃的发生的地方在:
[CMSDataModel saveSubRes:resCode:subResUrl:decompress:callback:]
下面贴出关键段的代码:
dispatch_async(self.ioQueue, ^{
BOOL ret = NO;
NSFileManager *fileManager = [[NSFileManager alloc] init];
do
{
NSString *path = [self subResFilePathOfOnline:resCode subResUrl:subResUrl filePath:nil createDir:YES];
if (![subResData writeToFile:path atomically:YES])
{
[fileManager removeItemAtPath:path error:nil];
break;
}
if (bDecompress)
{
ZipArchive *archive = [[ZipArchive alloc] init];
if (![archive UnzipOpenFile:path])
{
[fileManager removeItemAtPath:path error:nil];
[archive UnzipCloseFile];
break;
}
//再次访问Self的时候发生崩溃
NSString* tempFolder = [self subResFolderOfOnline:resCode subResUrl:subResUrl isTemp:YES];
if (![archive UnzipFileTo:tempFolder overWrite:YES])
{
[fileManager removeItemAtPath:path error:nil];
[fileManager removeItemAtPath:tempFolder error:nil];
[archive UnzipCloseFile];
break;
}
[fileManager removeItemAtPath:path error:nil];
[archive UnzipCloseFile];
NSString *resFolder = [self subResFolderOfOnline:resCode subResUrl:subResUrl isTemp:NO];
if ([fileManager fileExistsAtPath:resFolder])
{
[fileManager removeItemAtPath:resFolder error:nil];
}
if (![fileManager moveItemAtPath:tempFolder toPath:resFolder error:nil])
{
[fileManager removeItemAtPath:tempFolder error:nil];
}
}
ret = YES;
} while (NO);
if (callback)
{
dispatch_async(dispatch_get_main_queue(), ^{
callback(ret, resCode, subResUrl);
});
}
});
因为崩溃只发生在release包,所有把scheme改成release,模拟案发场景。果然程序很快崩溃在:
NSString* tempFolder = [self subResFolderOfOnline:resCode subResUrl:subResUrl isTemp:YES];
访问self 的时候崩溃了!这看起来不可能呀!
确定的是self 是肯定不会被释放的,而且也不存在多线程读写的问题。那么访问self怎么就会崩溃了呢!这不科学呀!

当时因为赶着发包,需要马上解决这个问题。经过几轮修改,最后的解决方案是,把do ,while 语句去掉(我也不知道为什么想到这么改)。发现居然解决了崩溃问题,那时候怀疑的是编译选项的问题。但是好像也说不过去呀,关do while毛线事呀。
劲总问起,因为还没清楚原因,只是说把do while 改了就修复崩溃了,怀疑与编译选项优化有关。
嗯嗯,问题解决了,先发包吧!
0x2 你良心不会痛吗?

正式包上线后,问题被修复了。但是这么严重怪异的崩溃问题,就这么敷衍的修复了?会不会掩盖了更严重的问题呀?
于是决定研究一下,防止以后再遇到这种问题而无从入手。既然可能是因为编译选项的问题,那么先从汇编上分析一下吧。以下是用hopper查看该函数的汇编代码(部分):
// 0x100d81000 + 0x8d0 定位到 NSFileManager
0000000100551e28 adrp x8, #0x100d81000
0000000100551e2c ldr x0, [x8, #0x8d0]
// 0x100d5c000 + 0xe00 定位到 alloc
0000000100551e30 adrp x8, #0x100d5c000
0000000100551e34 ldr x23, [x8, #0xe00]
0000000100551e38 mov x1, x23
0000000100551e3c bl imp___stubs__objc_msgSend
// 0x100d5c000 + 0xcd8 定位到 init
0000000100551e40 adrp x8, #0x100d5c000
0000000100551e44 ldr x22, [x8, #0xcd8]
0000000100551e48 mov x1, x22
0000000100551e4c bl imp___stubs__objc_msgSend
0000000100551e50 mov x19, x0
0000000100551e54 ldp x0, x2, [x20, #0x20]
0000000100551e58 ldr x3, [x20, #0x30]
// 0x100d72000 + 0x250 定位到 subResFilePathOfOnline:subResUrl:filePath:createDir
0000000100551e5c adrp x8, #0x100d72000
0000000100551e60 ldr x1, [x8, #0x250]
0000000100551e64 orr w5, wzr, #0x1
0000000100551e68 movz x4, #0x0
0000000100551e6c bl imp___stubs__objc_msgSend
0000000100551e70 mov x29, x29
0000000100551e74 bl imp___stubs__objc_retainAutoreleasedReturnValue
0000000100551e78 mov x21, x0
0000000100551e7c ldr x0, [x20, #0x38]
// 0x100d5d000 + 0x120 定位到 writeToFile:atomically:
0000000100551e80 adrp x8, #0x100d5d000
0000000100551e84 ldr x1, [x8, #0x120]
0000000100551e88 orr w3, wzr, #0x1
0000000100551e8c mov x2, x21
0000000100551e90 bl imp___stubs__objc_msgSend
0000000100551e94 tbz w0, 0x0, -[CMSDataModel saveSubRes:resCode:subResUrl:decompress:callback:]+972
0000000100551e98 ldrb w8, [x20, #0x48]
0000000100551e9c cbz w8, -[CMSDataModel saveSubRes:resCode:subResUrl:decompress:callback:]+1000
// 0x100d84000 + 0x110 定位到 ZipArchive
0000000100551ea0 adrp x8, #0x100d84000
0000000100551ea4 ldr x0, [x8, #0x110]
0000000100551ea8 mov x1, x23
0000000100551eac bl imp___stubs__objc_msgSend
0000000100551eb0 mov x1, x22
0000000100551eb4 bl imp___stubs__objc_msgSend
0000000100551eb8 mov x22, x0
// 0x100d72000 + 0x258 定位到 UnzipOpenFile
0000000100551ebc adrp x8, #0x100d72000
0000000100551ec0 ldr x1, [x8, #0x258]
0000000100551ec4 mov x0, x22
0000000100551ec8 mov x2, x21
0000000100551ecc bl imp___stubs__objc_msgSend
0000000100551ed0 tbz w0, 0x0, -[CMSDataModel saveSubRes:resCode:subResUrl:decompress:callback:]+1008
//按照调用约定,,x0 寄存器保存self,x0 = x20+0x20 , x0作为函数调用的第一个参数传入。但是发现x0 寄存器的值是0x20,导致访问self 的时候发生崩溃。这是典型的空指针问题呀~~~
0000000100551ed4 ldr x0, [x20, #0x20]
0000000100551ed8 adrp x8, #0x100d72000
那么关键是要看x20寄存器的值,究竟是谁动了x20寄存器!
0x3 谁动了x20寄存器
发生崩溃的原因很明显,就是x20的值被修改了,只要查出是谁动了0x20寄存器,就知道这是谁的pot了。
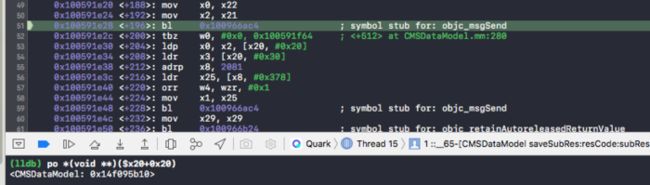
在执行bl 0x1009aaac4前,通过lldb查看$x20+0x20地址上的值是多少。
bl 0x1009aaac4 执行后,x20 就被修改了。那么关键就要看:bl 0x1009aaac4做了什么。下面是调用0x1009aaac4 后的汇编代码:
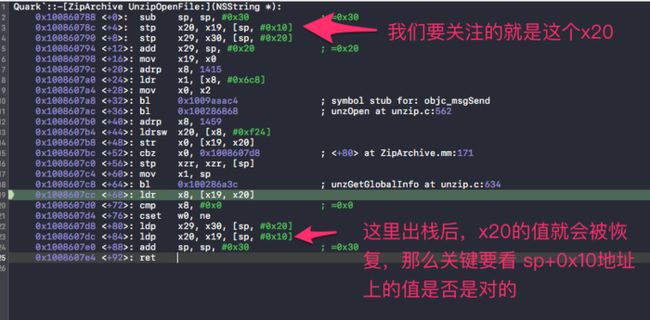
x20 的值保存在sp+0x10上,待函数执行完后,x20重新恢复原来的值,x20 = sp+0x10.那么关键点就落在 观察sp+0x10是否被修改。观察一个地址是否被修改,可以通过设置watchpoint来观察。
(lldb) watchpoint set expression $sp+0x10
接着继续执行,断点果然被命中了!
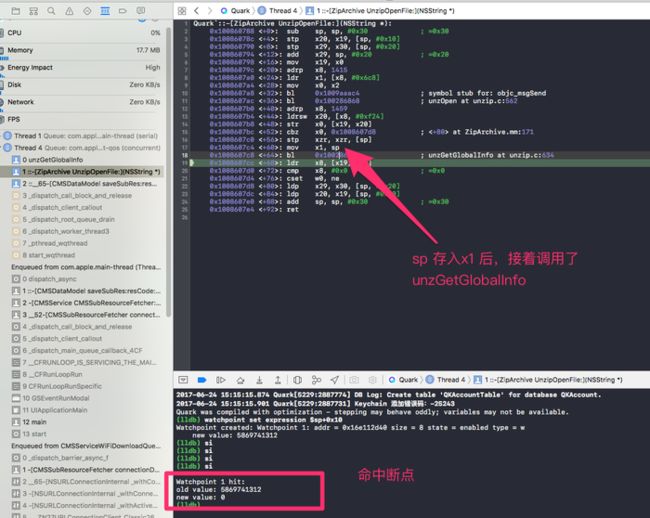
sp 存入x1 后,紧接着就去调用unzGetGlobalInfo 。
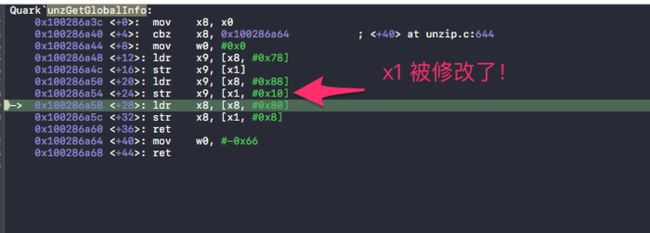
x1+0x10 其实就是sp+0x10 ,x1+0x10 被修改成0 。接着函数返回后,

0x1008607dc <+84>: ldp x20, x19, [sp, #0x10]
x20 = sp + 0x10 = 0。
x20+0x20 = 0x20 这就是访问的非法地址!
最后问题的关键在于unzGetGlobalInfo 函数,为什么它会修改 x1+0x10 的值?后面会解析,现在先看看为什么在debug下没有问题。
0x4 为什么开发的时候没问题呀? --- Debug with Debug scheme
同样的,通过打断点,查看unzGetGlobalInfo 函数的汇编代码。
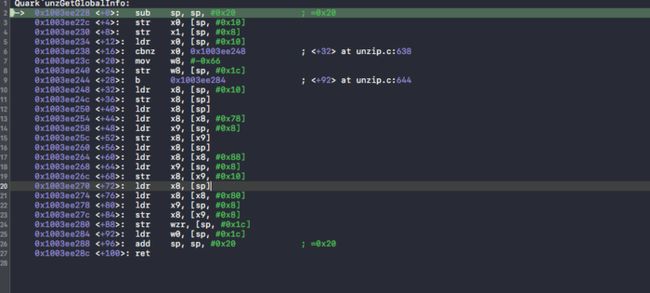
这汇编代码和release下看起来不像是同一份代码呀!难道有两个zip库!
接下来就尴尬了,项目里面真的有两个zip库,unzGetGlobalInfo 的实现是不一样的。
A 版本的:unzGetGlobalInfo
typedef struct unz_global_info_s
{
uLong number_entry; /* total number of entries in
the central dir on this disk */
uLong size_comment; /* size of the global comment of the zipfile */
} unz_global_info;
extern int ZEXPORT unzGetGlobalInfo (file,pglobal_info)
unzFile file;
unz_global_info *pglobal_info;
{
unz_s* s;
if (file==NULL)
return UNZ_PARAMERROR;
s=(unz_s*)file;
*pglobal_info=s->gi;
return UNZ_OK;
}
B 版本的:unzGetGlobalInfo B
typedef struct unz_global_info64
{
unsigned long long number_entry; /* total number of entries in
the central dir on this disk */
unsigned long number_disk_with_CD; /* number the the disk with central dir, used for spanning ZIP*/
unsigned long size_comment; /* size of the global comment of the zipfile */
} unz_global_info64;
extern int ZEXPORT unzGetGlobalInfo(unzFile file, unz_global_info *pglobal_info32)
{
unz64_s *s;
if (file == NULL)
return UNZ_PARAMERROR;
s = (unz64_s *)file;
/* to do : check if number_entry is not truncated */
pglobal_info32->number_entry = (uLong)s->gi.number_entry;
pglobal_info32->size_comment = s->gi.size_comment;
pglobal_info32->number_disk_with_CD = s->gi.number_disk_with_CD;
return UNZ_OK;
}
extern int ZEXPORT unzGetGlobalInfo(unzFile file, unz_global_info *pglobal_info32)
{
unz64_s *s;
if (file == NULL)
return UNZ_PARAMERROR;
s = (unz64_s *)file;
/* to do : check if number_entry is not truncated */
pglobal_info32->number_entry = (uLong)s->gi.number_entry;
pglobal_info32->size_comment = s->gi.size_comment;
pglobal_info32->number_disk_with_CD = s->gi.number_disk_with_CD;
return UNZ_OK;
}
s->gi 在A版本和B版本的结构体类型是不一样的,从上面的汇编代码知道,*pglobal_info=s->gi; 是关键的步骤,会不会由于A版本的unzGetGlobalInfo 函数用了B版本的s->gi 结构体类型呢?导致赋值的时候发生错误。
0x5 删除多余的zip 库
对于上面的假设,可以删除其中一个zip 库来验证。实验证明,删除多余的zip 库后,在release scheme 下,不会崩溃了!
结论
结论很简单,就是因为用了两个zip 库,导致编译器编译的时候,发生一些奇异的问题(本人对编译器不是很熟悉,后面有时间再研究学习一下)。大家遇到在release下崩溃,debug不崩的情况,不妨考虑一下是否有两份一样的代码。
遗留的问题
- 两份zip 代码,为什么没有报duplicate symbols。
- 编译器是如何选择哪一份代码编译的。
遗留的问题在这里可以查看!
作者:vedon_fu
链接:https://www.jianshu.com/p/b203b2cb313b
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。