19.12.10 Java大数据开发学习路线
19.12.10 Java大数据开发学习路线
- 学习路线
- 1、第一阶段:深入Java体系
- (1)Java语法基础:
- (2)Java虚拟机(JVM)和并发 (技能1):
- (3)Linux部分(技能2):
- (3)数据库:
- (4)计算机基础:
- (6)缓存:
- (7)源码:
- (8)架构:
- 2、分水岭第二阶段:
- 3、第三阶段:深入大数据体系
- (1)入门:
- (2)Hadoop原理(技能3):
- (3)HBase(《HBase权威指南》)(技能4)
- (4)Hive开发(技能5):
- (3)流计算:
- (4)分布式协议:
- (5)深入源码:
- (6)消息队列Kafka:
- 必须技能1-10条,高阶技能12-17条:
准备明年找Java大数据开发的岗位,因此搜集了Java大数据开发的学习路线和资源。来着博客和知乎。
我是学Java的,想尝试大数据和数据挖掘,该怎么规划学习?
写给需要的Javaer-大数据学习路线篇
java转大数据的学习路线和学习时间
路线1
路线2
java大数据学习路线 经典
学习路线
尚硅谷技术栈视频
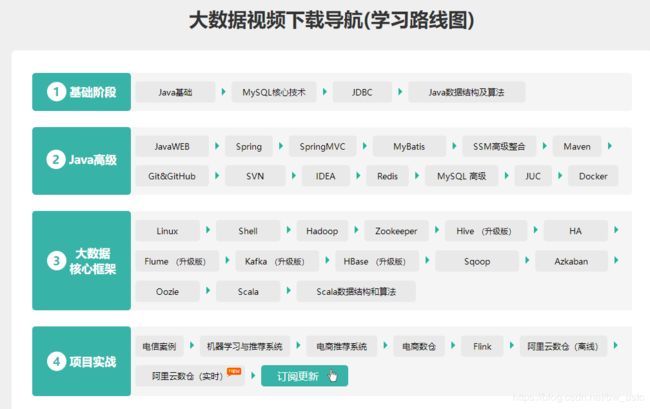
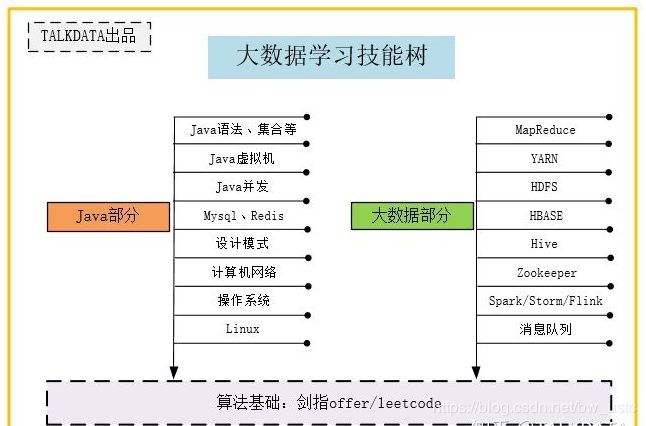
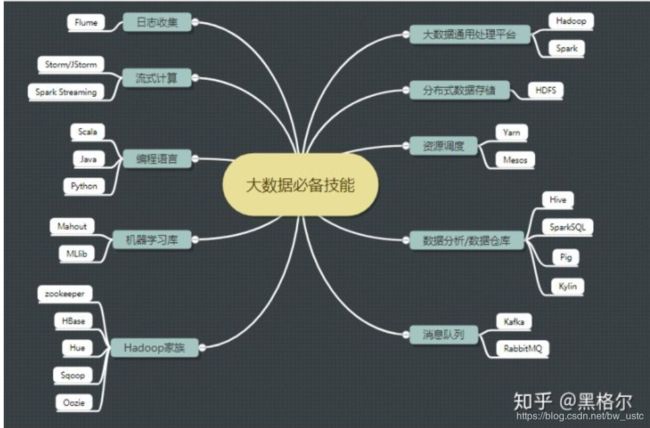
1、第一阶段:深入Java体系
(1)Java语法基础:
跟着毕向东老师的视频敲了一遍,看了《Java核心技术卷I》 和 《Java编程思想》 这两本书,刚开始看编程思想是有点难度的,不懂的地方标记出来,后面学了一段时间,回过头再看,这样的话,Java的语法基础基本过关;
(2)Java虚拟机(JVM)和并发 (技能1):
开始学习《深入理解java虚拟机》、《Java高并发程序设计》这两本书,刚开始看,真心不知道再讲什么,但当后面学了多了,看了一些源码后,再看就明白了,前期看不懂是正常的;
掌握多线程。
掌握并发包下的队列。
了解JMS。
掌握JVM技术。
掌握反射和动态代理。
(3)Linux部分(技能2):
看了《鸟哥Linux私房菜:基础篇》,然后自己装个Linux,练习指令操作,多多总结常见指令。
Linux操作系统介绍与安装。
Linux常用命令。
Linux常用软件安装。
Linux网络。
防火墙。
Shell编程等。
(3)数据库:
看了《MySQL必知必会》,学会了sql语法,刷了几十到牛客上SQL题目,最后看了《MySQL技术内幕:InnoDB 存储引擎》中的索引部分(有点难),数据库基本过关;
(4)计算机基础:
毕竟非科班,需要看的挺多的,看了《现代操作系统》、《图解TCP/IP》,重点掌握了一些关于内存、IO、TCP/IP、HTTP等方面的知识;
(6)缓存:
看了《Redis设计与实现》 和《Redis深度历险》两本书,缓存基本过关;
(7)源码:
推荐学习Java集合和并发包的部分源码,面试必问;
(8)架构:
推荐看下《大型网站技术架构》,扩展自己的知识广度。
2、分水岭第二阶段:
需要选择是Java后端还是大数据开发了Java后端方向:要开始学习Spring框架那一套了,并做一个后端的项目,深入理解数据库、缓存、并发、spring底层等原理,在项目中体现这些基础,面试时可以表现出你学习的深度,不只是会用。大数据开发方向:开始学习hadoop全家桶、spark、storm等流计算,下面第3点重点讲述。
3、第三阶段:深入大数据体系
(1)入门:
个人感觉视频入门最快,我看了一个关于大数据组件的介绍、安装和使用的视频课程,了解了大数据中各个组件是干嘛的,
(2)Hadoop原理(技能3):
先后看了《Hadoop权威指南》、《Hadoop技术内幕:Yarn》(对应技能3)(推荐看博客 ),掌握了hadoop中的Mapreduce、YARN、HBASE、HDFS、Hive的基本原理;
HDFS
HDFS的概念和特性。
HDFS的shell操作。
HDFS的工作机制。
HDFS的Java应用开发。
MapReduce
运行WordCount示例程序。
了解MapReduce内部的运行机制。
MapReduce程序运行流程解析。
MapTask并发数的决定机制。
MapReduce中的combiner组件应用。
MapReduce中的序列化框架及应用。
MapReduce中的排序。
MapReduce中的自定义分区实现。
MapReduce的shuffle机制。
MapReduce利用数据压缩进行优化。
MapReduce程序与YARN之间的关系。
MapReduce参数优化。
MapReduce的Java应用开发
(3)HBase(《HBase权威指南》)(技能4)
hbase简介。
habse安装。
hbase数据模型。
hbase命令。
hbase开发。
hbase原理。
(4)Hive开发(技能5):
看《Hive开发指南》
Hive 基本概念
Hive 应用场景。
Hive 与hadoop的关系。
Hive 与传统数据库对比。
Hive 的数据存储机制。
Hive 基本操作
Hive 中的DDL操作。
在Hive 中如何实现高效的JOIN查询。
Hive 的内置函数应用。
Hive shell的高级使用方式。
Hive 常用参数配置。
Hive 自定义函数和Transform的使用技巧。
Hive UDF/UDAF开发实例。
Hive 执行过程分析及优化策略
(3)流计算:
先后看了《Spark大数据处理技术》、《Storm分布式实时计算模式》《Spark 权威指南》和Flink官网介绍,(《Spark 快速大数据分析》)分析了三者的优点和缺点,学了他们的计算调度原理、容错机制、语义等方面;
enter image description here
Spark core
Spark概述。
Spark集群安装。
执行第一个Spark案例程序(求PI)。
RDD
enter image description here
RDD概述。
创建RDD。
RDD编程API(Transformation 和 Action Operations)。
RDD的依赖关系
RDD的缓存
DAG(有向无环图)
Spark SQL and DataFrame/DataSet
enter image description here
Spark SQL概述。
DataFrames。
DataFrame常用操作。
编写Spark SQL查询程序。
Spark Streaming
enter image description here
enter image description here
park Streaming概述。
理解DStream。
DStream相关操作(Transformations 和 Output Operations)。
Structured Streaming
(4)分布式协议:
主要学了《从paxos到zookeeper分布式一致性协议》 这本书,并根据网上博客学习Raft协议,将这些协议进行总结,并对zk进行深入学习;
Zookeeper分布式协调服务介绍。
Zookeeper集群的安装部署。
Zookeeper数据结构、命令。
Zookeeper的原理以及选举机制。
(5)深入源码:
我选择深入的是HDFS源码,结合《Hadoop 2.X HDFS源码剖析》书籍,看了大概3个月左右,中途看到怀疑人生,甚至想放弃大数据了,还好坚持了下来。也可以选择其他源码,只要是用Java写的就好。
(6)消息队列Kafka:
这个对于Java后端的同学也是需要的,我主要学习时Kafka,根据网上总结一些常见面试题,看了官网的介绍,基本可以应付面试;
必须技能1-10条,高阶技能12-17条:
- .Java高级(虚拟机、并发)
- .Linux 基本操作
- Hadoop(此处为侠义概念单指HDFS+MapReduce+Yarn )
- HBase(JavaAPI操作+Phoenix )
- Hive(Hql基本操作和原理理解)
- Kafka
- Storm
- Scala需要 (《快学Scala》)
Scala概述。
Scala编译器安装。
Scala基础。
数组、映射、元组、集合。
类、对象、继承、特质。
模式匹配和样例类。
了解Scala Actor并发编程。
理解Akka。
理解Scala高阶函数。
理解Scala隐式转换。 - Python
- Spark (Core+sparksql+Spark streaming ) (《Spark 快速大数据分析》)
- 一些小工具(Sqoop等)
- 机器学习算法以及mahout库加MLlib
- R语言
- Lambda 架构
- Kappa架构
- Kylin
- Aluxio
最后自己用虚拟机搭建一个集群,把所有工具都装上,自己开发一个小demo —30小时
可以自己用VMware搭建4台虚拟机,然后安装以上软件,搭建一个小集群(本人亲测,I7,64位,16G内存,完全可以运行起来)
第一步:掌握 hadoop和spark分布式计算框架,了解文件系统、消息队列和Nosql数据库,学习相关组件如hadoop、MR、spark、hive、hbase、redies、kafka等;
第二步:算法和工具
学习了解各种数据挖掘算法,如分类、聚类、关联规则、回归、决策树、神经网络等,熟练掌握一门数据挖掘编程工具:Python或者Scala。目前主流平台和框架已经提供了算法库,如hadoop上的Mahout和spark上的Mllib,你也可以从学习这些接口和脚本语言开始学习这些算法。
第三步:数学
补充数学知识:高数、概率论和线代
第四步:项目实践
1、开源项目:tensorflow:Google的开源库,已经有40000多个star,非常惊人,支持移动设备;
2、参加数据竞赛:Kaggle和国内天池数据竞赛
3、通过企业实习获取项目经验