Kafka 学习
20.1.30 Kafka 学习
- 第 1 章 Kafka 概述
- 1.1 定义
- 1.2 消息队列
- 1.2.1 传统消息队列的应用场景
- 1.2.2 消息队列的两种模式
- 1.3 Kafka 基础架构
- 第 2 章 Kafka 快速入门
- 2.1 安装部署
- 2.1.1 集群规划
- 2.1.2 jar 包下载
- 2.1.3 集群部署
- 2.2 Kafka 命令行操作
- 第 3 章 Kafka 架构深入
- 3.1 Kafka 工作流程及文件存储机制
- 3.2 Kafka 生产者
- 3.2.1 分区策略
- 3.2.2 数据可靠性保证
- 3.2.3 Exactly Once 语义
- 3.3 Kafka 消费者
- 3.3.1 消费方式
- 3.3.2 分区分配策略
- 3.3.3 offset 的维护(保存在zookeeper里)
- 3.3.4 消费者组案例
- 3.4 Kafka 高效读写数据
- 3.5 Zookeeper 在 Kafka 中的作用
- 3.6 Kafka 事务
- 3.6.1 Producer 事务
- 3.6.2 Consumer 事务
- 第 4 章 Kafka API
- 4.1 Producer API
- 4.1.1 消息发送流程
- 4.1.2 异步发送 API
- 4.2.3 创建生产者带回调函数(新API)
- 4.2.4 自定义分区生产者
- 4.3 Kafka消费者Java API
- 4.3.1 高级API
- 4.3.2 低级API
- 第 5 章 Kafka 监控
- 第 6 章 Flume 对接 Kafka
- 第 7 章 Kafka 面试题
第 1 章 Kafka 概述
1.1 定义

只要使用spark,那么百分之90的数据来源于kafka,其对于实时性的很重要。
1.2 消息队列
1.2.1 传统消息队列的应用场景


解耦,两端不需要同时在线。
削峰。解决生产消息速度远远大于消费消息速度的问题。

灵活性:可以随时上下线。
1.2.2 消息队列的两种模式

缺点:消息不可复用。


发布订阅模式里也分两种模式,一种是消费者主动拉消息,可以自己控制获取消息的速度,kafka就是这样(也有缺点,有点耗资源),还有一种是生产者主动推消息。(缺点,如果主动推,有的消费者处理消息速度慢,可能会崩)
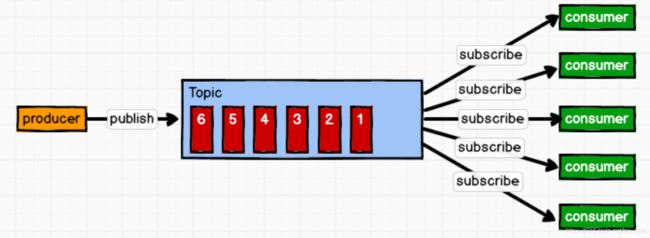
1.3 Kafka 基础架构


比如点赞的消息就是一个topic 浏览的消息也是一个topic 他们属于不同的topic,传进来的消息要分类!
一个topic有多个partition ,这样可以提高kafka负载均衡的能力,同时提高并发度。
消费者组订阅的是topic,同一个分区的数据不可以被同一个消费者组里的不同消费者使用,但是可以被不同消费者组的不同消费者使用。
消费者组里消费者的数量要小于等于某个topic的分区数,大于的话,,假设topicA有两个分区,消费组A订阅它,里面有三个消费者,前两个消费者订阅不同分区的数据,第三个消费者啥事也没有,浪费资源。


leader是针对某个分区的,而不是针对某个broken,follower起到备份的作用,确保kafka高可靠、高可用,所以leader和follower一定不在同一台机器上。而消费者和生产者一定找的是leader,follower仅仅起到备份的作用
第 2 章 Kafka 快速入门
2.1 安装部署
2.1.1 集群规划

2.1.2 jar 包下载

2.1.3 集群部署
1) 解压安装包
[BW@hadoop102 software]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
[BW@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka

2) 修改解压后的文件名称
[atguigu@hadoop102 module]$ mv kafka_2.11-0.11.0.0/ kafka
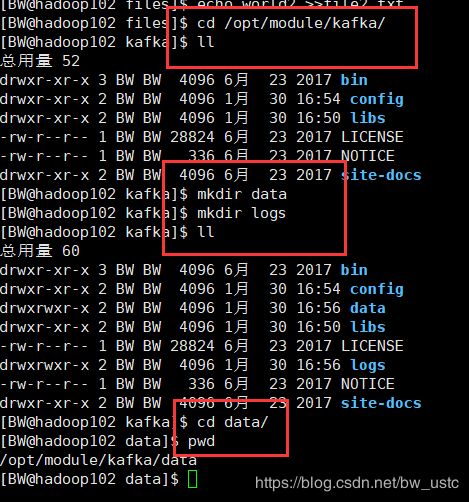
3)在/opt/module/kafka 目录下创建 logs 文件夹
[atguigu@hadoop102 kafka]$ mkdir logs
4) 修改配置文件
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vi server.properties





5)配置环境变量
[atguigu@hadoop102 module]$ sudo vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[atguigu@hadoop102 module]$ source /etc/profile
6)分发安装包
[atguigu@hadoop102 module]$ xsync kafka/

分发成功:


改103 104:


104改成2
8) 启动集群
启动集群之前一定要把zookeeper集群启动!
分别启动Zookeeper
[atguigu@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.4.10]$ bin/zkServer.sh start
然后依次在 hadoop102、 hadoop103、 hadoop104 节点上启动 kafka
[BW@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties
启动成功 发现是阻塞进程

以守护进程的方式启动
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties

9)关闭集群
[atguigu@hadoop102 kafka]$ bin/kafka-server-stop.sh stop
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh stop
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh stop
10) kafka 群起脚本
[BW@hadoop102 bin]$ vim kk.sh
添加以下内容:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo "========== $i =========="
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo "========== $i =========="
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
};;
esac
修改权限
[BW@hadoop102 bin]$ chmod 777 kk.sh
群起:(不成功!)
[BW@hadoop102 bin]$ kk.sh start
群停成功!奇怪了!!!
[BW@hadoop102 bin]$ kk.sh stop

2.2 Kafka 命令行操作
1)查看当前服务器中的所有 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
无反应

2)创建 topic 来分类数据
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --replication-factor 2 --partitions 2 --topic first
依赖于zk存储数据


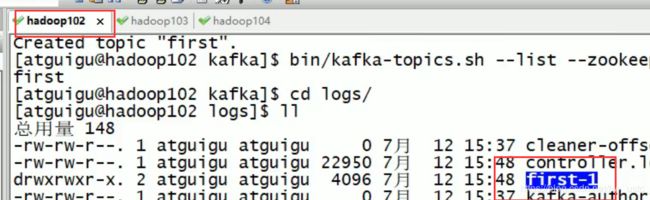
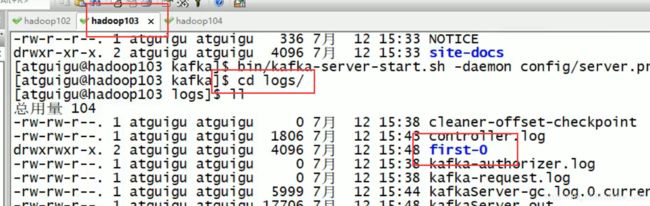
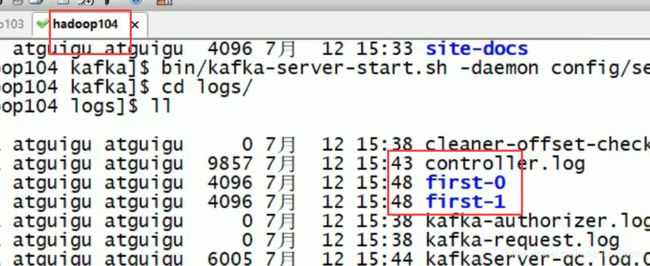
一共两个first0 两个first1 由于是两个副本,0 和1 是分区号,说明数据是存在磁盘的 是按照主题加分区名来命名的

要求副本数不能超过分区数
3)删除 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first
![]()
4)发送消息
开启生产者:
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>atguigu atguigu
![]()
5)消费消息
在103 和104 开启消费者:
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
[atguigu@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
![]()

6)查看某个 Topic 的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --describe --topic first

7)修改分区数
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --alter --topic first --partitions 6
然后进行数据和日志分离:
在102 103 104 都输入:
[BW@hadoop102 kafka]$ rm -rf logs/
然后进入zookeeper,里面存了很多kafka的元数据:
除了zookeeper,其他都是kafka的

用rmr 命令删除。
然后分别进入102 103 104的配置文件 修改到data目录
[BW@hadoop104 kafka]$ cd /opt/module/kafka/config/
[BW@hadoop104 config]$ vim server.properties

第 3 章 Kafka 架构深入
3.1 Kafka 工作流程及文件存储机制




kafka只能保证区内有序性,不能保证全局有序性。每一个分区都维护了一个偏移量。


分片指的就是一片最大是1G。
下面这个偏移量是index文件下面的log文件的最小的偏移量

也就是说 在first-0文件夹下分多个segment,上图有三个segment,分别是000 410 430,每个segment对应一个index文件和一个log文件。
log文件存放实际的数据。是经过序列化的

0 237 562 756 912 1016 是对应log文件6条消息的起始偏移量

3.2 Kafka 生产者
3.2.1 分区策略


3.2.2 数据可靠性保证










由于生产者没有收到ack 所以会重新发数据,但是之前已经同步好了 所以会造成数据重复。


(1)保证的是消费的一致性,(2)保证的是存储数据的一致性。

3.2.3 Exactly Once 语义


3.3 Kafka 消费者
3.3.1 消费方式


3.3.2 分区分配策略


这种策略是按照消费者组来分的
会将消费者组订阅的所有的topic的所有分区放在一起,取每个分区的hash值然后进行排序,然后整体进行轮询。
好处:每个消费者最多差一个分区的数据
存在的问题:使用的前提条件是一个消费者组里的几个消费者订阅的主题是一致的,如果消费者1订阅topic1 消费者2订阅topic2 那么使用轮询的方法,topic1的数据会传到消费者2里 不符合业务逻辑。

系统默认的是这个策略。是按照主题分的,


存在的问题:
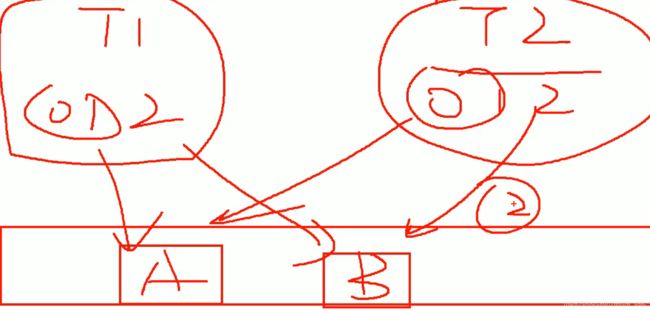
A有4个 B有2个,存在消费者消费消息不对等的情况。
当消费者数量增加或者减少时,都会触发重新分配(重新触发分区分配策略)。
3.3.3 offset 的维护(保存在zookeeper里)

唯一确定offset :消费者组、主题、分区。
假设消费者1消费topic1里的三个分区,消费到10条数据了,这时候进来了消费者2,所以分区分配策略触发,消费者2 至少消费1个分区,他是接着消费,不是从头开始消费


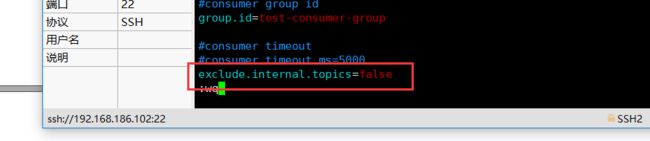
1)修改配置文件 consumer.properties
exclude.internal.topics=false
2)读取 offset
0.11.0.0 之前版本:
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter
"kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
0.11.0.0 之后版本(含):
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter
"kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --frombeginning
元数据是保存在zookeeper里:
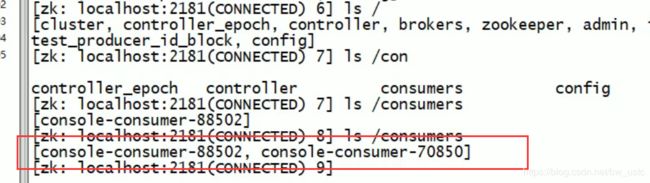

消费者组的id

而且也保存在本地:
在本地也是按照消费者组-topic-分区 来唯一确定offset
在文件是按照KV键值对保存的 k就是 消费者组-topic-分区 的哈希值 ,v就是offset。
这里不是消费者 而是消费者组 如果是消费者 当该消费者挂了以后,就找不到k 如果是消费者组,当一个消费者挂了以后 消费者组还存在,这样可以给别的消费者继续进行消费
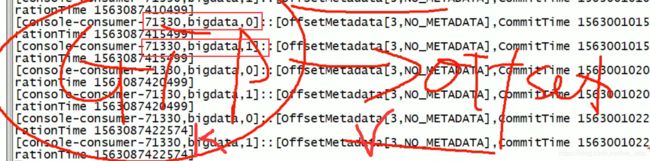
3.3.4 消费者组案例

[atguigu@hadoop103 config]$ vi consumer.properties
group.id=atguigu


(2)在 hadoop102、 hadoop103 上分别启动消费者
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first --consumer.config config/consumer.properties
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first --consumer.config config/consumer.properties
(3)在 hadoop104 上启动生产者
[atguigu@hadoop104 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
(4)查看 hadoop102 和 hadoop103 的接收者。
同一时刻只有一个消费者接收到消息。
注意:
不同组只要订阅了该topic,就可以同时消费信息
例如102 104 客户端属于不同组,同时订阅topic bigdata(两个分区) ,所以102 104 同时接收aaa,但是102(1)和102(2)属于同一组,不能同时消费,轮询消费。
如果再启动一个102(3)和之前的102属于同一个组,会重新触发分区机制,下一次发送的两个消息由102(1)和102(3)消费了。


这个写谁都行 因为他们是以集群方式工作的
3.4 Kafka 高效读写数据


3.5 Zookeeper 在 Kafka 中的作用

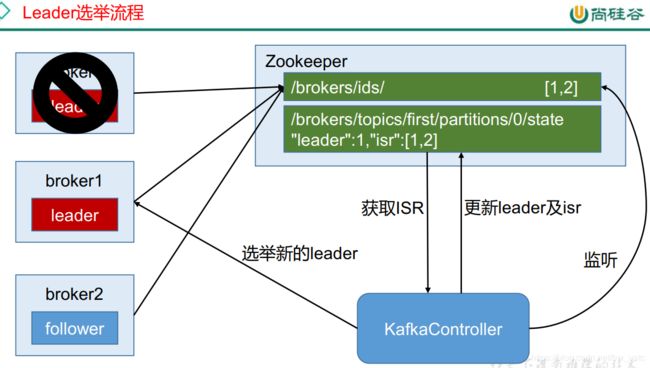
3.6 Kafka 事务

3.6.1 Producer 事务

之前的幂等性是解决单会话单分区的问题,引入Producer 事务结合之前的幂等性可以做到跨会话(Producer 挂了,重连,就不算同一次会话了)跨分区的精准一次性写入。
3.6.2 Consumer 事务

第 4 章 Kafka API
4.1 Producer API
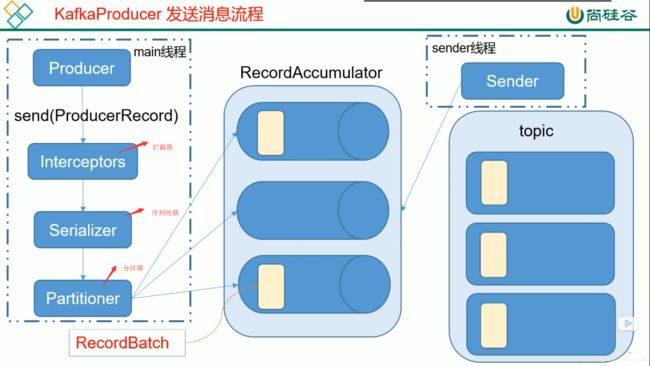
4.1.1 消息发送流程

与ack:
假设发送消息123 和456 。分批次发送,发送完123后,继续发456,来了789继续发789,如果发123的ack一直收不到的话,就重发123。 456 789 类似。

4.1.2 异步发送 API
建一个maven工程,导入依赖:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
</dependencies>
然后建一个包 再建一个类

package kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class CustomerProducer {
public static void main(String[] args) {
//1.创建kafka生产对象的配置信息
Properties props=new Properties();
//2.添加配置信息
//指定连接的kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//ack应答级别
props.put("acks", "all");
//重试次数
props.put("retries", 0);
//批次大小 一次发送多少大小的数据 单位字节 大约16k 每到16k 发送到内存中,内存最大的大小是32M
props.put("batch.size", 16384);
//等待时间 默认1毫秒
props.put("linger.ms", 1);
//RecordAccumulator 缓冲区大小 32M
props.put("buffer.memory", 33554432);
//key value 的序列化对
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//3. 创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//4.发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("bw", "BW--"+i));
}
//5.关闭资源
producer.close();
}
}
然后在102 103 104开启zookeeper的服务端
[BW@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh start
然后开启102 kafka的服务端
[BW@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties
然后开启客户端:
[BW@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic bw

接收成功

批量发送:

4.2.3 创建生产者带回调函数(新API)

修改上面的代码:
package kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class CustomerProducer {
public static void main(String[] args) {
//1.创建kafka生产对象的配置信息
Properties props=new Properties();
//2.添加配置信息
//指定连接的kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//ack应答级别
props.put("acks", "all");
//重试次数
props.put("retries", 0);
//批次大小 一次发送多少大小的数据 单位字节 大约16k 每到16k 发送到内存中,内存最大的大小是32M
props.put("batch.size", 16384);
//等待时间 默认1毫秒
props.put("linger.ms", 1);
//RecordAccumulator 缓冲区大小 32M
props.put("buffer.memory", 33554432);
//key value 的序列化对
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//3. 创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//4.发送数据
for (int i = 0; i < 10; i++) {
//producer.send(new ProducerRecord("bw", "BW--"+i));
producer.send(new ProducerRecord<String, String>("bw", "BW--"+i),new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null) {
System.out.println(metadata.partition()+"---"+metadata.offset());
}else {
System.out.println("发送失败");
}
}
});
}
//5.关闭资源
producer.close();
}
}
运行程序:
客户端:
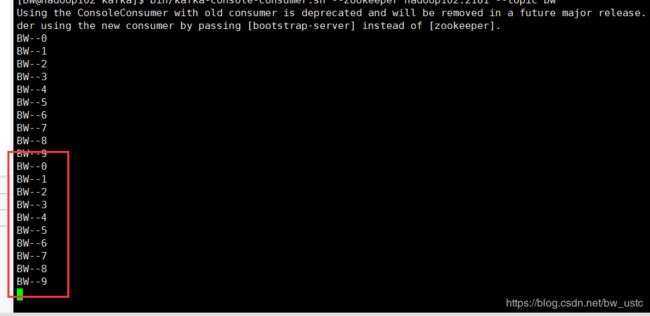
之前是一个分区,下面演示多分区:
创建一个主题:
[BW@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --topic second --partitions 3 --replication-factor 1
将之前的消费者停掉:重新启动 topic改成second

启动程序:
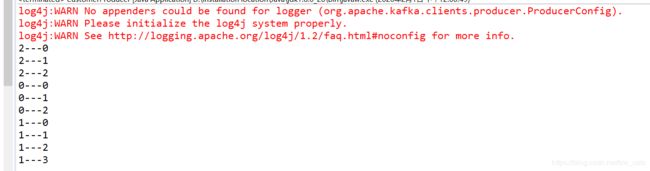
前面分区 后面偏移量 每个分区维护自己的偏移量 所以都从0开始。
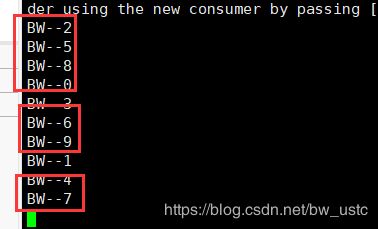
说明是分区发送的,先消费一个分区,这个分区消费完了,再消费下一个分区。
4.2.4 自定义分区生产者
- 编写CustomerProducer类 实现Partitioner接口,重写里面的方法
package kafka;
import java.util.Map;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
public class CustomerPatition implements Partitioner{
public void configure(Map<String, ?> configs) {
// TODO Auto-generated method stub
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 控制分区
return 0;
}
public void close() {
// TODO Auto-generated method stub
}
}
- 在代码中调用
package kafka;
import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class CustomerProducer {
public static void main(String[] args) {
//1.创建kafka生产对象的配置信息
Properties props=new Properties();
//2.添加配置信息
//指定连接的kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//ack应答级别
props.put("acks", "all");
//重试次数
props.put("retries", 0);
//批次大小 一次发送多少大小的数据 单位字节 大约16k 每到16k 发送到内存中,内存最大的大小是32M
props.put("batch.size", 16384);
//等待时间 默认1毫秒
props.put("linger.ms", 1);
//RecordAccumulator 缓冲区大小 32M
props.put("buffer.memory", 33554432);
//key value 的序列化对
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//自定义分区
props.put("partitioner.class", "kafka.CustomerPatition");
//3. 创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
//4.发送数据
for (int i = 0; i < 10; i++) {
//producer.send(new ProducerRecord("bw", "BW--"+i));
producer.send(new ProducerRecord<String, String>("second", "BW--"+i),new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null) {
System.out.println(metadata.partition()+"---"+metadata.offset());
}else {
System.out.println("发送失败");
}
}
});
}
//5.关闭资源
producer.close();
}
}
结果:

全在0分区

因为都在0分区 所以消息又有顺序了
4.3 Kafka消费者Java API
4.3.1 高级API
0)在控制台创建两个发送者,发送不同topic的消息
[atguigu@hadoop104 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world


1)官方提供案例(自动维护消费情况)(新API)
package customer;
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class CustomerConsumer {
public static void main(String[] args) {
//1.设置配置信息
Properties props = new Properties();
// 连接kafka集群
props.put("bootstrap.servers", "hadoop102:9092");
//设置消费者组id
props.put("group.id", "test");
//设置自动提交offset
props.put("enable.auto.commit", "true");
//提交延时 可能会重复消费
props.put("auto.commit.interval.ms", "1000");
//KV的反序列化
// key的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//2.创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);
//指定topic 里面放一个集合的参数,说明一个消费者可以消费多个topic
consumer.subscribe(Arrays.asList("second","first","third"));
while(true) {
//消费数据
ConsumerRecords<String, String> consumerRecords = consumer.poll(100);
//打印数据:
for (ConsumerRecord<String, String> record:consumerRecords) {
System.out.println(record.topic()+"---"+record.partition()+"---"+record.value());
}
}
}
}
运行程序:成功获取信息

4.3.2 低级API
先打开集群102 103 104
然后开集群102 103 104的zookeeper
然后开集群102 103 104的kafka:
/opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties
然后运行程序:

第 5 章 Kafka 监控

[BW@hadoop102 kafka]$ xsync bin/kafka-server-start.sh

[BW@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.3.7.tar.gz
kafka-eagle-bin-1.3.7/
kafka-eagle-bin-1.3.7/kafka-eagle-web-1.3.7-bin.tar.gz
[BW@hadoop102 software]$ cd kafka-eagle-bin-1.3.7
[BW@hadoop102 kafka-eagle-bin-1.3.7]$ tar -zxvf kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
[BW@hadoop102 module]$ mv kafka-eagle-web-1.3.7/ eagle
[BW@hadoop102 eagle]$ pwd
/opt/module/eagle
#EAGLE_HOME
export KE_HOME=/opt/module/eagle
export PATH= P A T H : PATH: PATH:KE_HOME/bin
source /etc/profile
[BW@hadoop102 bin]$ chmod 777 ke.sh


http://192.168.186.102:8048/ke
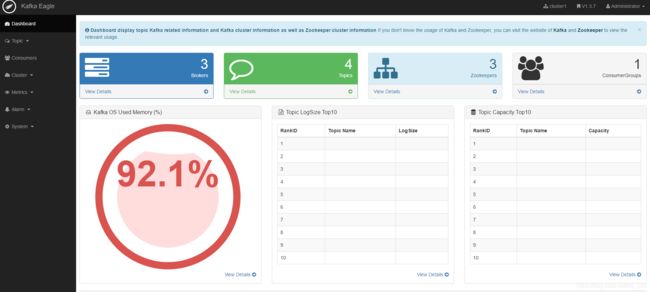


重点掌握:



第 6 章 Flume 对接 Kafka
为什么要flume接kafka:
生产环境中,经常将数据采集到日志文件中,而flume是日志监控框架。为啥要对接kafka?由于flume采集数据后要对接多个业务线,内存不太够,业务线上的要保证数据一致,而且不能动态增加业务线
在flume里增加配置文件
[BW@hadoop102 job]$ vim kafka.conf
#Name
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#a1.sources.r1.command = tail -F -c +0 /opt/module/data/flume.log
#a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在102 103 104 启动kafka
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
然后在102创建一个消费者
[BW@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first
然后102启动flume
[BW@hadoop102 flume]$ bin/flume-ng agent -c conf/ -f job/kafka.conf -n a1
然后用netcat写信息:
[BW@hadoop102 ~]$ nc localhost 44444
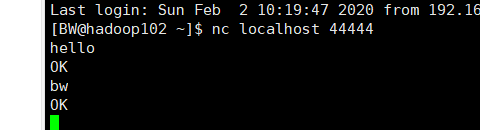
然后查看kafka消费者是否收到信息;

还有一个数据分类的案例 看新版的P42
第 7 章 Kafka 面试题
![]()
ISR+OSR=AR

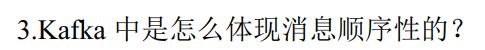
区内有序
![]()
看课件
![]()
两个线程 讲过

对 但是生产环境下不能让这种事发生
![]()

![]()



offset从0开始存 加入一个数据,提交的位移是0+1=1

8:先处理数据,后提交offset,有可能在中间挂了,消费了数据,但是没有提交offset 下一次又来一遍,导致重复消费,
9:先提交offset 后处理数据


可增不可减
不可减:已经存在的数据无法处理

有, consumeroffsets 作用:给普通的消费者存offset

两种:range(按照主题划分) round…(按照消费者组,进行轮询分)

index和log 如何找到具体的数据:
![]()
第一步通过二分查找法定位index文件 然后扫描这个文件
找到这个数据在log里面具体的偏移量
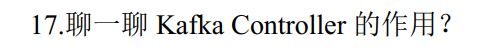
(问的比较少)相当于临时选举的老大。当元数据更新时,通知别的节点保持一致
等
![]()
两处地方:controller(原则比较简单:抢资源) 和leader (原则 ISR 一个看同步的时间 一个看同步的条数)
ISR
分布式
顺序写磁盘
零拷贝
![]()





