TIDB在伴鱼的实践
一、背景介绍
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一,旗下包括伴鱼绘本、伴鱼少儿英语、伴鱼自然拼读和伴鱼精读课等系列产品。伴鱼使用的数据库种类有Tidb,MongoDB,MySQL,Codis。在伴鱼,目前生产环境共有11套Tidb集群,服务于在线教学、绘本、消息、交易和少儿等众多核心业务。
目前线上Tidb部署版本统一为2.1.15。Tidb server和PD混部,机器配置:64C64G500G SAS;Tikv单独部署,机器配置:64C64G1.5T NVME
下面从伴鱼为何选择Tidb,伴鱼Tidb架构、伴鱼在使用Tidb过程中遇到的问题、我们是如何解决这些问题的以及Tidb在伴鱼的后续使用计划等几个方面进行阐述。
二、伴鱼为何选择Tidb
伴鱼发展之初,选择了MongoDB作为数据存储,但随着业务的快速发展,逐渐暴露出一些问题,比如业务对事务的需求、单表数据极速增长导致的性能问题以及集群实例容量问题等。因此,我们对新存储的诉求有以下几点:
集群高可用
MongoDB副本集架构支持高可用,不需要通过第三方程序来支持高可用,可以减少依赖和运维成本。因此对于新存储,我们也需要它天然支持高可用。
支持事务
目前我们生产使用的MongoDB 3.2版本对事务的支持较弱,而业务的很多场景需要事务的支持。
大容量、高吞吐
MongoDB副本集主节点永远只有一个,当业务快速发展时,可能出现写瓶颈,如果这时想扩展写就非常痛苦了。同时,机器的磁盘空间有限,在数据增长到一定量级时,也会出现集群容量瓶颈的问题。
不分表
不管MySQL还是MongoDB数据库,表数据达到一定的量级,读写性能都会下降。通过分表可以提高读写性能,但是业务代码需要维护比较复杂的分表逻辑和路由。
基于以上这些需求,我们通过调研,选择了当前流行的Tidb分布式数据库,主要原因包括:Tidb天然支持以上几点需求;同时Tidb已经在很多公司使用起来,经历了众多业务场景的历练,而且我们的业务使用场景也比较类似。
三、伴鱼Tidb架构
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。

TiDB Server
TiDB Server负责接收SQL请求,处理SQL相关的逻辑,并通过PD找到存储计算所需数据的TiKV地址,与TiKV交互获取数据,最终返回结果。TiDB Server是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展。
PD Server
Placement Driver是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个Key存储在哪个TiKV节点);二是对TiKV集群进行调度和负载均衡(如数据的迁移、Raft group leader的迁移等);三是分配全局唯一且递增的事务ID。
PD为master-slave架构,通过Raft协议进行选举保障服务高可用。Raft的leader server负责处理所有操作,其余的PD server仅用于保证高可用。
TiKV Server
TiKV Server负责存储数据,从外部看TiKV是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Region,每个Region负责存储一个Key Range(从 StartKey到EndKey的左闭右开区间)的数据,每个TiKV节点会负责多个Region。TiKV使用Raft协议做复制,保持数据的一致性和容灾。副本以Region为单位进行管理,不同节点上的多个Region构成一个Raft Group,互为副本。数据在多个TiKV之间的负载均衡由PD调度,这里也是以Region为单位进行调度。
伴鱼Tidb架构
目前伴鱼Tidb的业务接入方式主要通过SLB接入,当TiDB-Server节点宕机,10s可以被负载均衡识别,自动剔除故障节点。PD和Tikv数据默认三副本,组件自身的高可用由raft算法协议保证。

四、伴鱼在使用Tidb过程中遇到的问题
伴鱼在使用Tidb之初,我们统一了集群使用的Tidb版本,规范了版本的配置,这样可以避免维护多个版本带来的潜在问题,同时有利于增强我们对特定版本的把控程度。我们生产环境的Tidb版本为2.1.15,随着业务的快速发展,主要遇到以下几个问题:
优化器选择索引不准确
在生产环境中,我们碰到过以下几种现象
1)单表数据30W+,查询请求并发约10+,某次业务上线,新增一个索引后,导致原有的查询索引选择错误,tikv实例所在机器cpu迅速被打满,引发故障。
2)线上某张大表,请求量比较大,偶尔出现个别条件走不到索引,导致全表扫描,从而引发接口响应时间的抖动,影响业务。
3)线上某张14亿的大表,查询条件区分度很高,某天出现特定条件突然走不到索引,导致全表扫描,引发故障。后面经过pingcap同学排查,系bug导致。
数据库性能问题定位慢
生产环境发生过一次今人印象深刻的故障,持续时间约一天。其实现在回过头来看,问题可以简单描述为:一个sql由于走错索引,数据扫描比较大,同时加上高峰期并发比较大,导致tikv cpu被打满,导致整个集群响应时间变高,引发故障。但是这次问题的定位,我们付出了很大的代价。
大数据同步问题
许多公司都有数据分析的需求,我们把上游各Tidb集群的数据通过Pump/Drainer汇聚到一个Tidb集群供大数据分析使用。在使用过程中,遇到数据不一致以及数据同步慢等问题。
五、我们如何解决在使用Tidb过程中遇到的问题
对于优化器选择索引不准确问题
在开发使用Tidb的过程中,对于数据量大的表和请求量比较大的表,我们强烈要求开发使用强制索引,防止在特殊情况下,请求走不到索引。同时,我们SQL审核平台,对新建表的索引数量都有严格的限制,防止研发同学建过多的索引。索引越少,理论上可以降低优化器选错索引的概率。
对于数据库性能问题的快速定位
Tidb兼容了MySQL协议,运维方式上跟MySQL有很多相似之处。我们认为,数据库的性能问题,绝大部分原因都是由慢SQL导致的,当然像数据库bug、业务异常流量等情况,在伴鱼还是比较少见的。所以,我们如何准实时收集分布式Tidb的慢日志、如何快速的做分析统计以及如何及时的告警,对于快速解决线上问题,甚至将性能风险扼杀在摇篮里至关重要。
1)如何快速收集Tidb慢日志
我们采用了业界比较成熟的开源日志采集/分析/存储架构,很好的解决了我们对慢日志的分析统计需求。

日志采集架构中,其中filebeat负责增量收集Tidb产生的慢日志,由于filebeat比较轻量,对线上性能基本无影响;kafka负责接收从filebeat采集过来的慢日志;logstash负责读取kafka中的慢日志并进行解析,转换成我们想要的kv键值对;最后解析后的数据入到es,供kibana查询分析统计。

对于Tidb的慢日志,我们重点关注慢日志中的某些特定字段,比如:
Time:表示日志打印时间。
DB:表示执行语句时使用的database。
Query_time:表示执行这个语句花费的时间。
Total_keys:表示Coprocessor扫过的key的数量。
Process_keys:表示Coprocessor处理的key的数量。相比total_keys,processed_keys不包含 MVCC的旧版本。
SQL:执行的sql语句。
2)如何快速的分析统计
logstash解析的数据入到es,通过kibana,我们可以很方便的对数据进行分析统计,比如:
1)近5分钟内,查询时间超过1s的请求/倒序排列/按表统计
2)近5分钟内,Process_keys大于5000的请求/倒序排列/按表统计
3)按照业务db统计慢日志数量
等等,同时我们还开发了慢日志分析报表平台,从各个维度(库/表/操作类型/慢日志数量/总时间/平均响应时间等)对慢日志进行统计分析,及时发现性能风险。
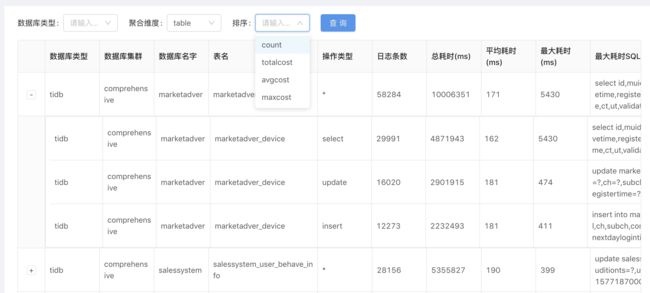
3)如何及时的告警
在伴鱼,一个db对应一个服务,所以告警都是在特定db下设置规则。目前,我们告警粒度是一分钟,主要基于以下三类规则告警:某个db的慢日志达到一定数量则告警;某个db下的请求时间超过500ms且达到一定数量则告警;某个db下的查询Process_keys大于1000且达到一定数量则告警。当然告警规则的设置不是一蹴而就的,需要根据不同的业务场景,不断的调整,最终达到一个比较合理的阀值。

对于大数据同步问题
我们通过pump/drainer将上游Tidb的数据同步到大数据Tidb集群,供大数据分析统计。在使用过程中,我们遇到以下几个问题,并逐一解决。
1)某天业务反馈,大数据集群某些表的数据少于线上集群。通过排查发现,上游某张表数据乱码,drainer同步下游报错,导致服务重启,重启时同步的位点不正确,导致上下游数据不正确。最后通过修复上游数据,重新同步解决。
2)drainer消费数据很慢,通过加大txn-batch/worker-count数量解决。
3)Tidb大数据集群raft store cpu长期居高临下,我们通过开启开启Region Merge和调整raft-base-tick-interval解决,最终raft store cpu利用率从90%下降到50%。
六、Tidb在伴鱼的后续展望
目前,我们在保证生产环境Tidb-2.1.15现有版本的稳定的同时,也在调研Tidb-3.0.x新版本的一些特性。从官方介绍,我们重点关注以下特性:
1)3.0与2.1版本相比,提升了大规模集群的稳定性。优化Raft副本之间的心跳机制,按照Region的活跃程度调整心跳频率,减小冷数据对集群的负担;热点调度策略支持更多参数配置,采用更高优先级,并提升热点调度的准确性;优化PD调度流程,提供调度限流机制;新增分布式GC 功能,提升GC的性能,降低大集群GC时间。
2)TiDB 3.0版本采用多种优化手段提升查询计划的稳定性。如新增Fast Analyze功能,提升收集统计信息的速度,降低集群资源的消耗及对业务的影响;新增SQL Plan Management功能,支持在查询计划不准确时手动绑定查询计划。
3)3.0与2.1版本相比,在查询性能上有很大的提升。如TiDB持续优化SQL执行器;TiKV新增多线程Raftstore和Apply功能,提升单节点内并发处理能力和资源利用率,降低延时,大幅提升集群写入能力。
因此,我们计划在2020年上半年,陆续将生产Tidb版本从2.1升级到3.0版本。