CNN Architecture:从LeNet-5到CapsulesNet
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- DenseNet
- CapsulesNet
- Summary
转载请注明出处: http://blog.csdn.net/c602273091/article/details/79119303
对于LeNet-5和AlexNet的论文我都有认真看过,对于另外的结构略看了paper。这篇博客主要还是以总结为主,对各种框架和一些比较常见的如YOLO,shoot learning进行总结。之后还会有博客关于如何不借助框架从0开始撸一个CNN。
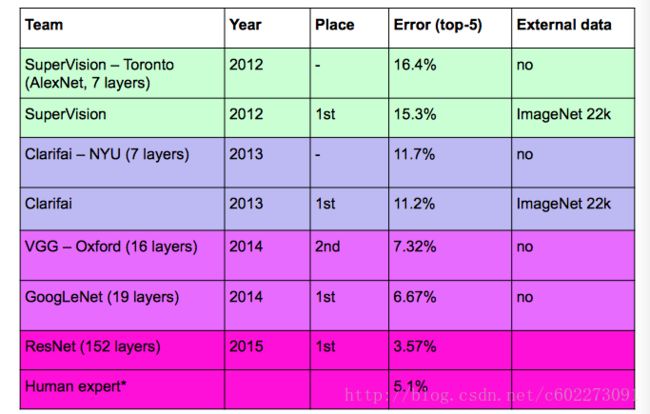
CNN的architecture基本上是靠着CV领域的ILSVRC的Object detection进行推动的,可以从下图中看到Top-5 error(mAP【2】)逐年递减的趋势。
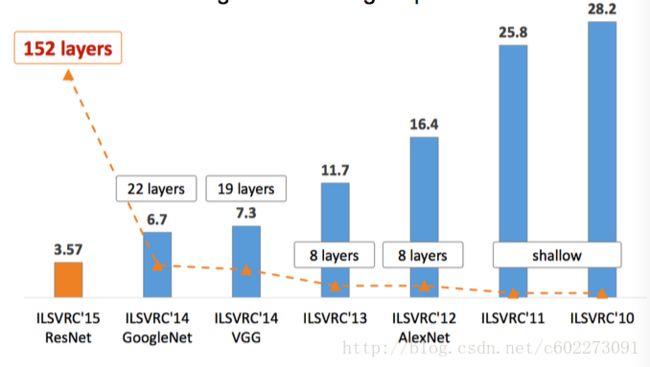
对于mAP举个例子,是关于document ranking的例子,把document换成image的label就是一个意思。就是说第一个example有五个document是relevant的,那么从retrieval出来的n个document计算这5个document都包含进去的precision。然后进行多次的搜索,取平均的precision,就是mAP。

其实mAP没有用到Ranking的信息,所以把ranking也加入了就有类似于NDCG的measure。当然还有很多,这里不再赘述。
LeNet-5
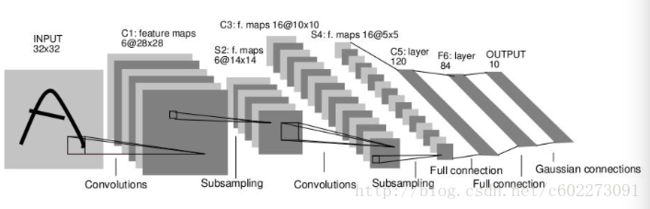
最开始吃螃蟹的人总是让人印象深刻~ 这篇98年的论文与现如今的CapsulesNet比较又有哪些变化呢?LeNet-5使用Average Pooling,Sigmoid或者是tanh做activation function,实现nonlinearity。为什么现在的cnn大多使用max pooling呢?我觉得应该是要回归到pooling的原本的目的,它是为了进行降采样,减小网络的representation,毕竟要考虑计算量。同时,期待使用这个方法在一定程度减少过拟合。那么,做过图像处理的都明白,处理图像的噪声采用中值滤波,去除高频信号。这应该就是使用average pooling的初衷。但是呢我们需要考虑一个问题,feature map不是单个的存在,会对后续的activation产生新的feature map有影响,而我们明白使用linear regression计算activation function的输入,主要是比较大的会对其造成影响。所以我觉得pooling层其实可以优化,对现有的进行改进。另外,我很同意【4】中对于max pooling的去除冗余信息的想法,因为在进行kernel shift的时候,有部分的输入时重叠的,所以我们主要考虑较大的feature response(看到没有,同一个东西,CNN其实经常可以用不同的表述。而这种max pooling的东西为什么要,都是凭ituition,不然来个数学证明。)。
这里的激活函数,使用的是Sigmoid和tanh,那么为什么是这个呢?从引入这个东西出发,主要是为了给网络增加non-linearity,毕竟如果只是一堆矩阵相乘相加,其实还是线性的。所以在那个时候,根据从生物学角度,对神经元进行刺激,发现了神经反应激活有一个阈值,但是属于不可导的图形,为了让其可导,所以有人提出用Sigmoid函数,这种函数求导还有一个特性,等于f(x)(1-f(x))。Sigmoid有个问题就是gradient valish,开始的时候梯度大,但是到后面梯度就基本接近于0,从导数也可以看出当x趋于无穷大的时候,f(x)趋近于1,另外1-f就趋向于0,那么梯度无法进行更新。下图是Sigmoid。具有稀疏激活性,单侧抑制的特点。

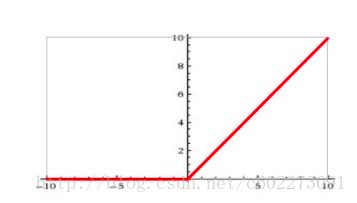
tanh是用:【5】对于为什么用tanh呢?个人以为是因为有正有负,那么正的就对activation有positive effect,负的就有negative effect。不会像Sigmoid那么单调,就会形成一个反差,其实我怎么说都可以,有道理就可以。所以就是这么神奇。 tanh的优点:tanh的值域为[-1, 1]并以0为中心,tanh的缺点:梯度饱和,当tanh的输出为-1或1时,梯度将变成0 (可以观察y=tanh(x)的图像)

激活函数中比较出名的还有ReLU,ReLU是AlexNet开始使用的,这里提前说了。
ReLU:为什么用ReLU呢?主要是为了解决gradient vanish的问题,同时可以减少计算量。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。这可以用来做什么?模型压缩呀~ [6]
当然激活函数还有很多变种,比如leaky ReLU,maxout,都是极其简单的式子,主要用心去感受为什么这样做。当然,需要从具体的实验中进行函数拟合,对每层进行visualize,突然间对CNN越发有感觉了,但是如果都是这样靠ituition的话,我觉得真是要完。在需要安全系数很高的地方,比如自动驾驶,比如家用机器人,谁敢用?若网络遇到与训练相差很大的sample,做出了不可描述的行为都是有可能的。所以大家都在搞transfer learning?(其实transfer learning也可以属于RL)这样看来,RL的解释性明显比DL好。所以在NLP近期好多论文用RL了,对话系统啦,机器翻译啦。
另外呢,在RNN中会使用tanh,其实也有ReLU(如果遇到gradient explode,就使用gradient clipping,直接把很大的gradient截到threshold)
对于梯度下降,看我前一篇博客的推导。另外,对convolution layer进行解释,不少人对这个的理解就停留在于matrix-vector multiply(对于矩阵和vector的乘法可我想到了matrix-matrix multiply的优化,使用CUDA,OpenMP等等),其实这个是数字图像处理有着一个比较明确的含义(我发现CNN的卷积不像卷积,数字图像的convolution定义如下,就当做CNN中的convolution是进行了shift吧)
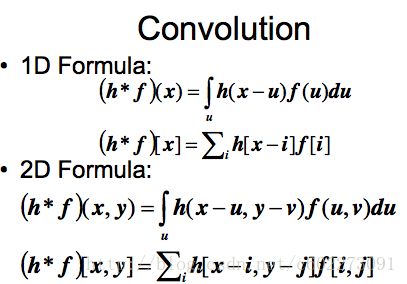
Correlation:

为什么不使用fully-connected的convolution呢?为了减少计算量,同时基于图像是具有local perception的,就是局部的图片具有全局的表征性。
AlexNet
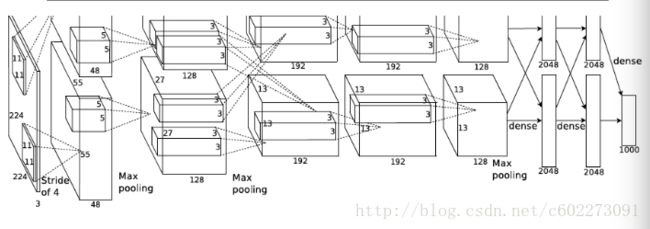
一共有7个隐层,650k个unit,60M的参数。使用了两个GPU进行训练,训练了一周。同时使用了Dropout regularization,Tom Mitchell说Russ在设计这个网络的时候觉得他很crazy,不过事实证明这个东西还是很有效的。假设dropout rate为p, traditional dropout: 训练时,随机把部分feature置为0,测试的时候用dropout rate对feature vector进行scaling;inverted dropout: 训练时,随机把部分feature置为0,在把这个feature vector乘以1/p, 测试时不做任何处理。dropout的作用的缓解过拟合,也可以看做是一种regularization的方式。
其实进行模型加速的时候,ShuffleNet就是使用了group convolution,真是返璞归真。有时候把以前的论文捣鼓一下,换一个名词,披上新的外衣,又是一篇。
VGGNet
把AlexNet中的7x7的kernel全部换成了3x3,这样减少参数的个数。

有size为1的kernel,叫做network in network,这样参数就更少了。从AlexNet 230M的参数到29M参数【8】。具有优点更好的局部抽象;更小的全局Overfitting;更少的参数(没有全连接层) NIN还干掉了全连接层,改成用average pooling作为softmax的输入【9】。为什么这么做呢?这样做通过加强特征图与类别的一致性,让卷积结构更简单,可以使用更少的feature map;(因为经典的CNN为了解决广义线性模型抽象能力不足的问题,采取过多的filter集合来弥补,也就是说不通的滤波器来检查同一特征的不同变体);不需要进行参数优化,减少了参数,所以这一层可以避免过拟合;它对空间信息进行了求和,因而对输入的空间变换更具有稳定性。
具体操作:没有什么好说的,就是kernel size换成了1x1。

GoogLeNet
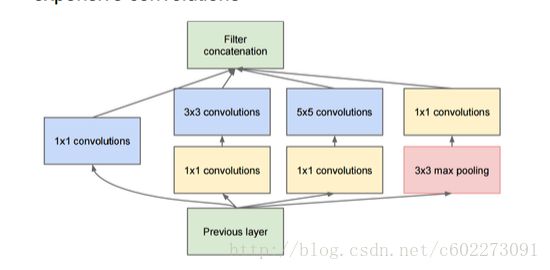
GoogleNet提出了有名的Inception Module,进行卷积的时候,对同一个feature map进行不同size的convolution。这个时候网络已经有152层。

GoogleNet的完整网络:
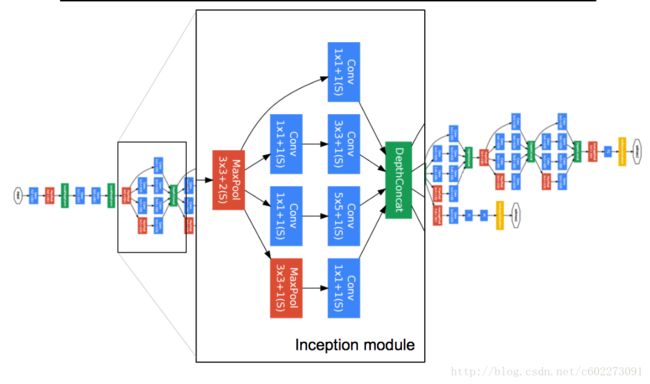
参数列表:【10】
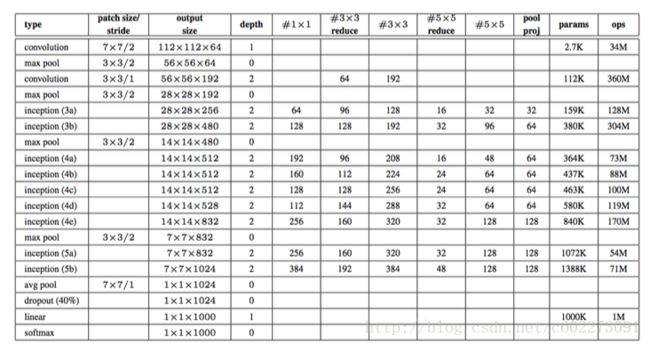
为什么提出这样的网络呢?[11] 【12】
GoogleNet为了建立类似于NIN的网络,增加non-linearity,同时用不同的size,增大视野,以及降低参数的维度【13】(有技巧)。
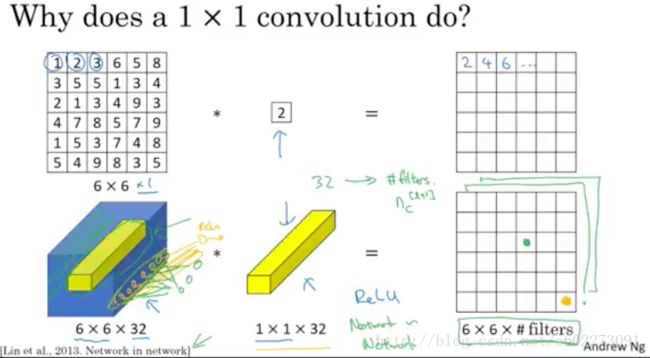
对于此,NG大佬是这么解释的【14】:CNN有1x1,3x3,5x5,7x7的kernel,那么为什么不对同一个feature map一起来呢?
所以呢就有了以下结构:1x1的kernel得到64个feature map,那么需要192x1x1x64。以此类推,max pooling就可以把好几层,这里是相邻六层作为一个输出,这个都可以自己设计。一般size使用3x3.
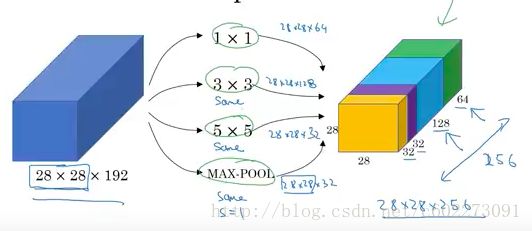
以上网络的问题就在于计算量,可以发现5x5的网络,计算量非常大。为了得到一个feature response,需要进行5x5x192次的乘加操作。有28x28x32个response,所以就有120M次operation。
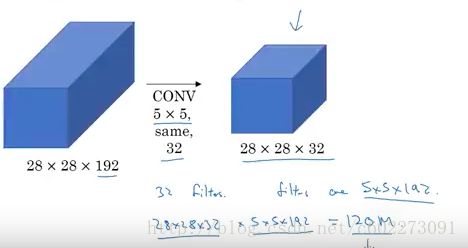
如何进行减少计算量呢?其实很容易想到,在线性代数领域,svd分解可以大大减少求解的计算量。那就给目前的5x5 kernel得到的feature maps加一层。这个时候计算量就小了很多,对于这里的计算需要注意一点,为了得到每一个feature response,需要对所有的输入的feature map的同一位置进行乘加(LeNet-5不是这样,采用的是映射表,group convolution)
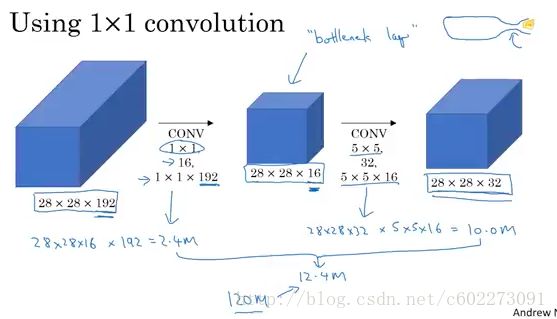
完整的Inception Module如下:
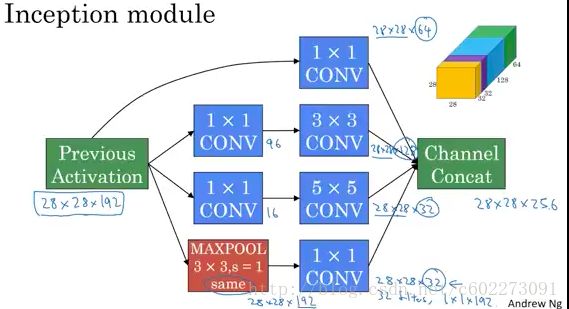
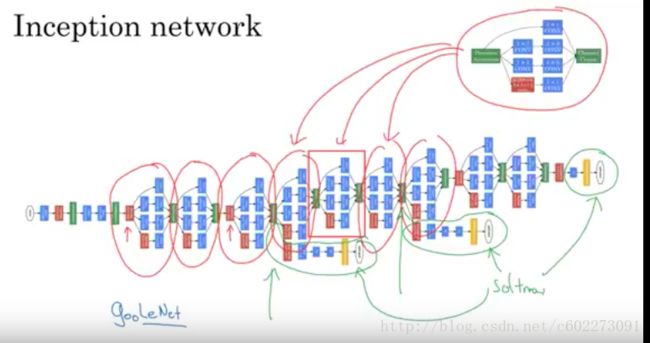
这里还有一个点在于为了说明inception的重要性,在某些层输出了softmax层做预测,发现效果还不错,说明这种inception提取的feature还是不错的。另外,inception的来源就是盗梦空间(英文名inception,是Google出来的科学家都喜欢看电影么?我的导师也喜欢电影,还po在主页上)
之后的inception module的版本还加入了batch normalization,为的就是进行regularize,减少variance。inception v2,v3增加feature map的同时减少了pooling的大小。

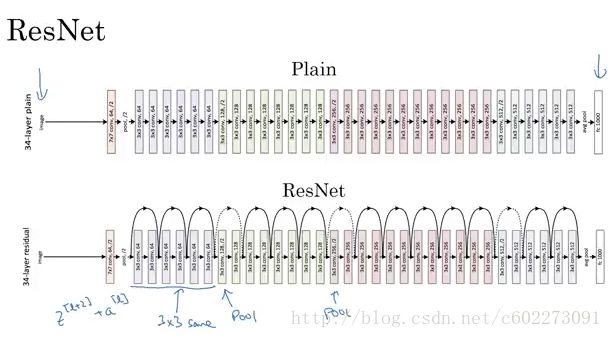
ResNet
总的来说就是skip-convolution,在计算BP的时候对于w的更新要记住从两部分从到来,看我上一篇关于GD的文章。

在进行3x3的convolution之前先进行NIN,输出再用NIN,减少参数。
参数:
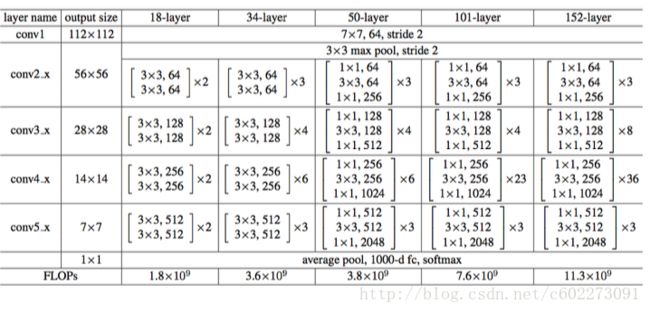
为什么使用ResNet?因为可以缓解gradient vanish和explode的问题。
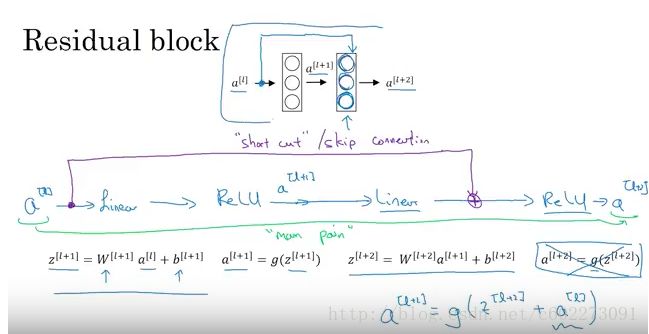
NG[19]用一个图解释了为啥gradient vanish的问题可以解决:
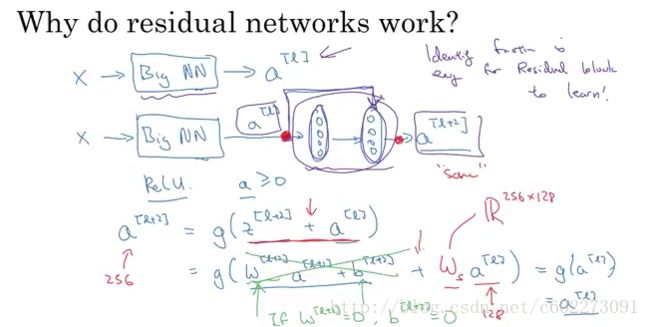
ResNet长这样:
DenseNet
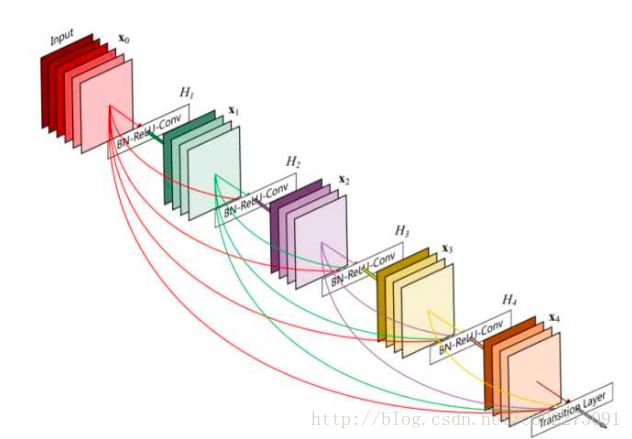
以上的结构叫做Dense Block,它包括输入层在内共有5层,H是BN+ReLU+3x3Conv的操作,并不改变feature map的大小。对于每一层来说,前面所有层的feature map都被直接拿来作为这一层的输入。growth rate就是除了输入层之外,每一层feature map的个数。它的目的是,使得block中的任意两层都能够直接”沟通“。
然后整个网络是这样的:

Why DenseNet?
ResNet直接通过”Summation”操作将特征加起来,一定程度上阻碍(impede)了网络中的信息流。DenseNet通过连接(concatenate)操作来结合feature map,并且每一层都与其他层有关系,都有”沟通“,这种方式使得信息流最大化。其实DenseNet中的dense connectivity就是一种升级版的shortcut connection,提升了网络的鲁棒性并且加快了学习速度。
我真是服了,可以发现这整个网络的变化,ResNet就说我skip convolution,然后DenseNet说你连的不够多,到后来估计就是各种方向的来一下,这个网络变得和RNN越来越像了,怎么办,接下来怎么讲故事。
CapsulesNet
这一部分的资料主要是看了【22】的总结,有摘录。
大佬Hinton对于神经系统的思考:
反向传播难以成立。神经系统需要能够精准地求导数,对矩阵转置,利用链式法则,这种解剖学上从来也没有发现这样的系统存在的证据。神经系统含有分层,但是层数不高。且生物系统传导在ms量级(GPU在us量级),并且同步也出现问题。大部分哺乳类,特别是灵长类大脑皮层中大量存在称为 Cortical minicolumn 的柱状结构(皮层微柱),其内部含有上百个神经元,并存在内部分层。这意味着人脑中的一层并不是类似现在NN的一层,而是有复杂的内部结构。人的视觉系统会建立“坐标框架”,并且坐标框架的不同会极大地改变人的认知;人识别物体的时候,坐标框架是参与到识别过程中,识别过程受到了空间概念的支配。
CNN对旋转没有不变性。可采用 数据增强方式让其达到旋转不变性。CNN中的Invariance可以用batch normalization进行减缓。所以Hinton提出的Capsules有一层中有复杂的内部结构;能表达“坐标框架”;实现同变性(Equivariance)
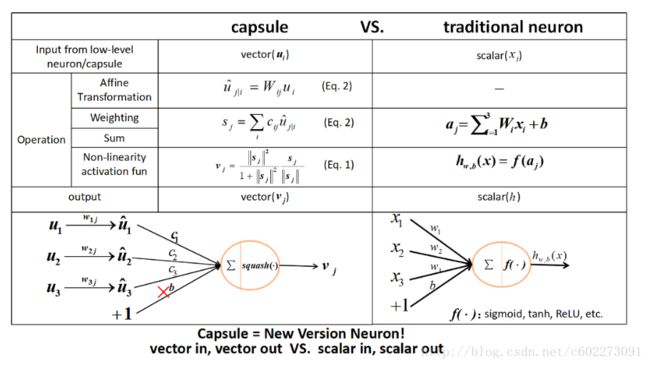
Capsule用一组神经元而不是一个来代表一个实体,且仅代表一个实体。它是一个高维向量:(之前的神经网络由softmax输出,一个输出就代表一个实体)
- 模长代表某个实体(某个物体,或者其一部分)出现的概率。
- 方向/位置代表实体的一般姿态 (generalized pose),包括位置,方向,尺寸,速度,颜色等等。同变性就是一个物体换了一个位置观测,内容不变化。
这篇论文主要是想解决视角变化的问题,如今需要进行数据增强才能处理视角变化所带来的影响。这个网络出来以后感觉又挖了很多坑,网络结构又可以进行新一轮的猜想,估计今年就有很多CapsuleNet的paper。
网络结构:
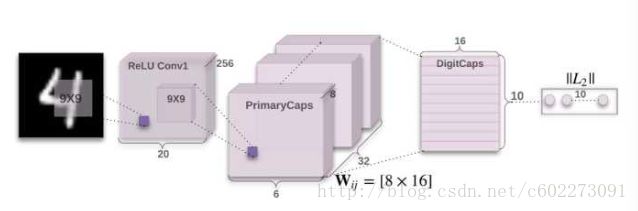
第一层为卷积,输入为28x28x1,输出为20x20x256,kernel size是9x9。
第二层Capsule卷积层,kernel size还是9x9,但是输出的不是标量的feature response,而是一个8x1的vector。输出的是一个6x6x32个Capsule(每一个都是8x1的vector)
第三层DigitCaps是Capsule全连接层,DigitCaps层有10个Capsules(分别对应10个数字),每个Capsule都会接受所有上一层Capsules的输出,然后计算输出16维活跃度向量。第二层共输出 6×6×32=1152 个capsule,即i层共有1152个Capsule,第三层j层有10个Capsules(每个是16维的向量)。
- W_ij有1152×10个,每个是8×16的向量
- u_i(8×1的向量)与W_ij相乘得到预测向量([8,16].T*[8,1]=[16,1])后,接着就有1152×10个耦合系数c_ij。
- 将s_j传入squashing后就得到激活后的最终输出v_j。
- DigitCaps 层与 PrimaryCaps 层之间的参数中,所有 W_ij 的参数数量是 1152×10×8×16=1474560,c_ij 的参数数量为 1152×10,b_ij参数数量是1152×10。
与原本的CNN的neuron进行比较:
论文作者选择了给每个数字计算边缘损失(Margin Loss)来作为模型优化的目标。除此以外,还加入重构损失(Reconstruction Loss)来进行正则化(Regularization)。在训练过程中,图片标注对应的数字Capsule被选中,经过3层全连接层产生重构图片,并计算重构图片和原始图片的平方差和(Sum of Squared Differences)来作为重构损失。
![]()
- 其中 c 是分类类别,T_c 为分类的指示函数(c 存在为 1,c 不存在为 0),m+ 为上边界,m- 为下边界。此外,v_c 的模即向量的 L2 距离。
- 对每一个表征数字 k 的 Capsule 分别给出单独的 Margin loss。
- 实例化向量的长度来表示 Capsule 要表征的实体是否存在。
TF的CapsNet的实现[24]
Summary
所以总结一下:
- LeNet-5基本上奠定了整个CNN的框架
- AlexNet用了ReLU,max pooling,更多的层数和kernel size,算法加速,dropout,Learning rate decay,之后的网络在它的基础上进行修改
- VGGNet把大的网络拆成更小的网络,使用了NIN。
- GoogleNet提出inception module在增大视野的同时就加入了NIN,降低参数的位数,batch normalization
- ResNet:skip convolution,解决了gradient vanish的问题
- DenseNet:连得更猛了~
- CapsuleNet:Hinton提出的用于解决视角invariant的问题。将原本的scalar的response改成了vector,squashing function也是进行了改进。同时loss采用了SVM的margin loss和reconstruction loss。
那么请问,ReLU,pooling,ResNet Module这些求导你会了么?看我前一篇关于GD的文章吧·~ 提示,让我写代码的话,做BP的时候,只计算前向gradient的时候,我会存一个比较大的pooling之前的矩阵,如果是对应的输出的值的那个梯度就是1,否则就是0.
这里的总结呢少了一些训练的trick,initialization(比如随机呀,transfer learning呀),regularization,data augmentation。之后会再写一篇关于CNN的一些trianing的trick总结。
个人想法:从这些年来看,CNN架构都是在进行一点点改进,理论上的证明我不太清楚。有没有类似于SVM这样把最小化loss转换成求解它的对偶问题 通过KKT condition找出support vector这样的东西。我觉得接下来应该就是DRL的舞台了,从智能的程度上,还是DRL更加好,算是基本上达到了自主学习。我还是继续站DRL,不过RL更加像是一种策略,数学上的证明也更加完备一些。RL在拟合policy-function,value-function的时候也用DL,但是不仅仅是DL就是了。RL可以把目前所有的算法都包括进去。
Ref Links:
[1] Convolutional Neural Network Architectures: from LeNet to ResNet: http://web.engr.illinois.edu/~slazebni/spring17/lec01_cnn_architectures.pdf
[2] mAP: https://www.youtube.com/watch?v=pM6DJ0ZZee0
[3] LeNet-5: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[4] Why Max pooling: https://www.zhihu.com/question/41948919
[5] tanh: https://www.zhihu.com/question/41948919
[6] ReLU: https://www.zhihu.com/question/29021768
[7] RNN tanh: https://www.zhihu.com/question/61265076
[8] NIN: https://tangxman.github.io/2015/12/26/nin/
[9] NIN paper: https://arxiv.org/abs/1312.4400
[10] Going Deeper with convolutions: https://arxiv.org/abs/1409.4842
[11] Why Inception: http://iamaaditya.github.io/2016/03/one-by-one-convolution/
[12] Why inception: https://ziyubiti.github.io/2016/11/13/googlenet-inception/
[13] Inception uasge: http://nooverfit.com/wp/inception深度学习家族盘点-inception-v4-和inception-resnet未来走向何方/
[14] NG Inception Network Motivation: https://www.youtube.com/watch?v=HunX473yXEI&list=PLBAGcD3siRDjBU8sKRk0zX9pMz9qeVxud&index=17
[15] NIN: https://www.youtube.com/watch?v=9EZVpLTPGz8&list=PLBAGcD3siRDjBU8sKRk0zX9pMz9qeVxud&index=16
[16] Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
[17] Summary: https://courses.engr.illinois.edu/cs543/sp2017/lectures/Lecture%2022%20-%20CNNs%20-%20%20Vision_Spring2017.pdf
[18] ResNet NG:https://www.youtube.com/watch?v=K0uoBKBQ1gA
[19] Why ResNet? NG: https://www.youtube.com/watch?v=GSsKdtoatm8
[20] Summary 2: https://zhuanlan.zhihu.com/p/31006686
[21] CapsuleNet: https://zhuanlan.zhihu.com/p/30970675
[22] CapsuleNet2: https://zhuanlan.zhihu.com/p/31728352
[23] CapsuleNet Comparing with traditional neuron: https://github.com/naturomics/CapsNet-Tensorflow/blob/master/README.md
[24] Implementation of TF: https://github.com/naturomics/CapsNet-Tensorflow