AI能写论文了!华人本科生发明AI论文生成器
 来源:arxiv
来源:arxiv
编辑:肖琴、大明
本文经授权转自公众号新智元(ID:AI_era)
AI写论文达到了几近完善的程度!伦斯勒理工学院大四学生王清昀等研究人员最新开发PaperRobot,能够从产生点子、写摘要、写结论到写“未来研究”,甚至它还能为你写出下一篇论文的题目。
还在为写论文想不出好点子而发愁吗?
不用愁了!伦斯勒理工学院、华盛顿大学等的研究人员最新开发的 PaperRobot,提供从产生idea、写摘要、写结论到写“未来研究”的一站式服务!甚至它还能为你写出下一篇论文的题目,从此论文无忧。
这篇题为PaperRobot: Incremental Draft Generation of Scientific Ideas的论文已被ACL 2019录取,近日在推特上引起大量关注。

谷歌大脑科学家David Ha(hardmaru)评价:“May a thousand (incremental) ideas bloom. ?”
论文作者来自伦斯勒理工学院、DiDi 实验室、伊利诺伊大学香槟分校、北卡罗来纳大学教堂山分校和华盛顿大学。其中,第一作者Qingyun Wang (王清昀)是伦斯勒理工学院的大四本科生(今年8月开始讲进入UIUC读计算机科学PhD)。
这不是王清昀同学第一次研究AI写论文,早在2017年他的“论文摘要生成”研究也曾引起热议。王清昀同学中学在杭州第二中学就读,从小就是“发明小达人”,取得专利的发明就有2个。

论文地址:
https://arxiv.org/pdf/1905.07870.pdf
PaperRobot是怎样自动写论文的呢?简单来说,它从以前的论文中提取背景知识图谱,产生新的科学思想,最后写出论文的关键要素。
它的工作流程包括:
(1)对目标领域的大量人类撰写的论文进行深入的理解,并构建全面的背景知识图(knowledge graphs, KGs);
(2)通过结合从图注意力(graph attention)和上下文文本注意力(contextual text attention),从背景知识库KG中预测链接,从而产生新想法;
(3)基于memory-attention网络,逐步写出一篇新论文的一些关键要素:从输入标题和预测的相关实体,生成一篇摘要;从摘要生成结论和未来工作;最后从未来工作生成下一篇论文的标题。
研究者对这个AI论文生产机进行了图灵测试:
PaperRobot生成生物医学领域论文的摘要、结论和未来工作部分,同时展示人类写作的同领域论文,要求一名生物医学领域的专家进行比较。结果显示,分别就摘要、结论和未来工作部分而言,在30%、24%和12%的情况下人类专家认为AI生成的比人类写作的更好。
至于这批AI研究人员为什么选择生物医学领域来做实验,原因很简单:生物医学论文很多,非常多!他们尝试了用自己领域(NLP)来做实验,结果并不理想(NLP的论文语料还不够多)。
接下来,新智元对这篇论文进行了译介:
我们的目标是打造一个论文机器人PaperRobot,来加速科学发现和生产,它的主要任务如下。
阅读现有的论文。
论文太多了。科学家们很难跟上井喷式的论文增长速度。例如,在生物医学领域,平均每年有超过50万篇论文被发表,仅2016年就有超过120万篇新论文发表,总论文数超过2600万篇(Van Noorden, 2014)。
然而,人类的阅读能力几乎是不变的。2012年,美国科学家估计,他们平均每年只能阅读264篇论文(5000篇论文中只读1篇),这个数字与他们在2005年进行的同样调查中报告的数据一致。
PaperRobot自动阅读所有可用的论文,构建背景知识图(KG),其中节点表示实体/概念,边表示这些实体之间的关系。
在本研究中,我们采用的是大量已发表的生物医学论文,提取实体及其关系来构建背景知识图。我们应用了Wei等人(2013)中提出的实体和关系提取系统,提取了3类实体(疾病,化学和基因)。然后,我们进一步将所有实体链接到CTD(比较遗传毒理学数据库),提取出133个子类型的关系,如标记/机制、治疗和提高表达。
图3是一个示例。
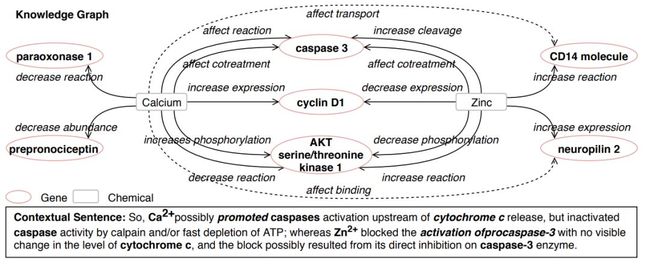
图3:生物医学知识提取与链接预测示例(虚线表示预测的链接)
产生新的想法。
科学发现可以看作是在知识图中创建新的节点或链接(links)。
创建新节点通常意味着通过一系列真实的实验室实验发现新的实体(如新的蛋白质),这对PaperRobot来说可能太难了。但是,使用背景知识图作为起点,自动地创建新的边是更容易的。
Foster等人(2015)的研究表明,640万篇生物医学和化学论文中,60%以上是增量式的工作。这启发我们通过预测背景知识图(KGs)中的新链接来自动地增加新想法和新假设。
我们提出了一种新的实体表示方法,结合了KG结构和非结构化上下文文本来进行链接预测。
如上面的图3所示,虚线表示了预测的链接,由于钙和锌在上下文文本信息和图结构上都相似,我们预测了钙的两个新邻居:CD14分子和神经纤毛蛋白2(neuropilin 2),它们是初始背景知识图中锌的邻居。
写一篇关于新想法的新论文。
最后一步是把新想法清晰地传达给读者,这是一件非常困难的事情;事实上,许多科学家都是糟糕的作家(Pinker, 2014)。
使用一个新颖的memory-attention网络架构,基于输入的标题和预测的相关实体,PaperRobot自动写出了一篇新论文的摘要,然后进一步写出了结论部分和相关工作部分,最后,为后续论文写了新标题。
这个流程如图1所示。
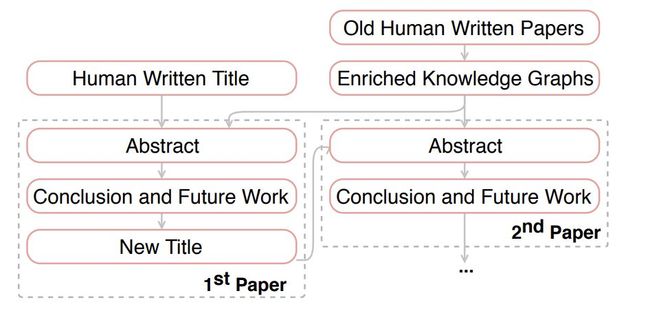
图1: PaperRobot论文写作流程
我们选择生物医学作为我们的目标领域,因为这一领域有大量的可用论文。
图灵测试表明,PaperRobot生成的输出内容有时比人工编写的内容更受欢迎;而且大多数论文摘要只需要领域专家进行少量编辑,就可以变得信息丰富、条理清晰。
让我们看看AI写的摘要:
Background: Snail is a multifunctional protein that plays an important role in the pathogenesis of prostate cancer. However, it has been shown to be associated with poor prognosis. The purpose of this study was to investigate the effect of negatively on the expression of maspin in human nasopharyngeal carcinoma cell lines. Methods: Quantitative real-time PCR and western blot analysis were used to determine whether the demethylating agent was investigated by quantitative RT-PCR (qRT-PCR) and Western blotting. Results showed that the binding protein plays a significant role in the regulation of tumor growth and progression.
PaperRobot的整体框架如图2所示。
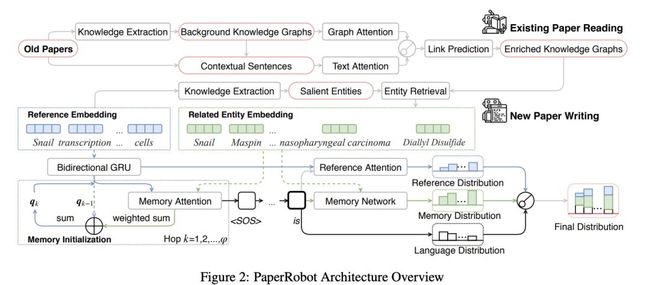
图2
表1显示了从整个过程生成的示例。
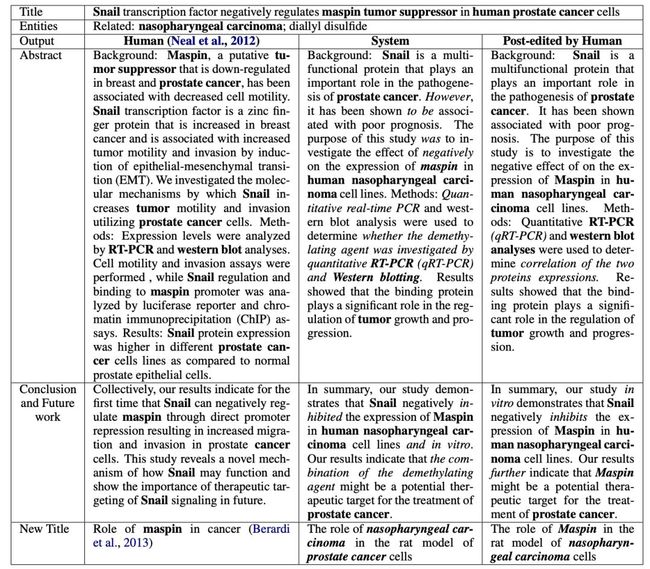
表1:人类写的论文与AI系统写的论文的比较(粗体字表示与主题相关的实体;斜体表示人工编辑)
(关于每个步骤的算法的详细介绍,请阅读原始论文。)
实验过程及结果
数据收集
我们从PMC开放存取子集中收集了生物医学论文。为人类书面论文引用一篇论文来构建新标题预测的ground truth,我们假设论文A的标题是从论文B的“结论和未来工作”中生成的。我们从1,687,060篇论文中构建了背景知识图,其中包括30,483个实体和875,698个关系。表2所示为详细数据统计。
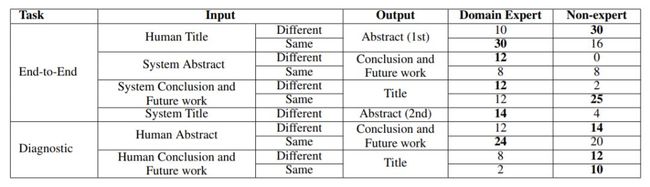
表2 论文写作统计结果
自动评估
以前的相关研究表明,自动评估长文本生成是一项重大挑战。在故事生成之后,我们使用METEOR来量度文章主题与给定标题的相关性,并使用困惑度(perplexity)来进一步评估语言模型的质量。
我们的模型的困惑度评分是基于在PubMed上的论文(500,000篇题材,50,000篇摘要,50,000个结论和未来工作)中学习的语言模型评出的,这些论文在我们的实验中没有用于训练或测试。结果如表3所示。我们的框架优于以前的所有方法。
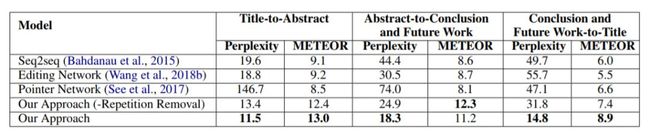
表3 对诊断任务论文写作的自动评估结果
图灵测试
由生物医学专家(非母语人士)和非专家(母语人士)对模型进行图灵测试。测试中要求每个人类对系统输出的字符串和人类创作的字符串,并选出质量更高的字符串。

表4 对模型的图灵测试结果(%)。百分比表示人类裁判选择我们的模型输出结果的频率。如果输出字符串(如摘要)基于相同的输入字符串(如标题),输入条件标记为“相同”,否则标记为“不同”。
可以看到,在专家的选择中,PaperRobot生成的摘要入选率比人类撰写的摘要入选率最多高出30%,“结论和未来工作”部分最多高24%,新标题最多高出12%。领域内专家的表现并未明显优于非专家,因为这两类人倾向于关注不同方面:专家侧重于内容(实体,主题等),而非专家侧重于语言。
人类后期编辑
为了测量PaperRobot作为写作助手的有效性,我们在第一次迭代中随机选择了系统生成的50篇论文摘要,并要求领域内的专家对其进行编辑,直到专家认为编辑后摘要具有足够的信息性和连贯性。然后由BLEU,ROUGE和TER通过比较人类编辑前后的摘要质量给出评分,如表5所示。专家花了大约40分钟。完成了50篇摘要的编辑。
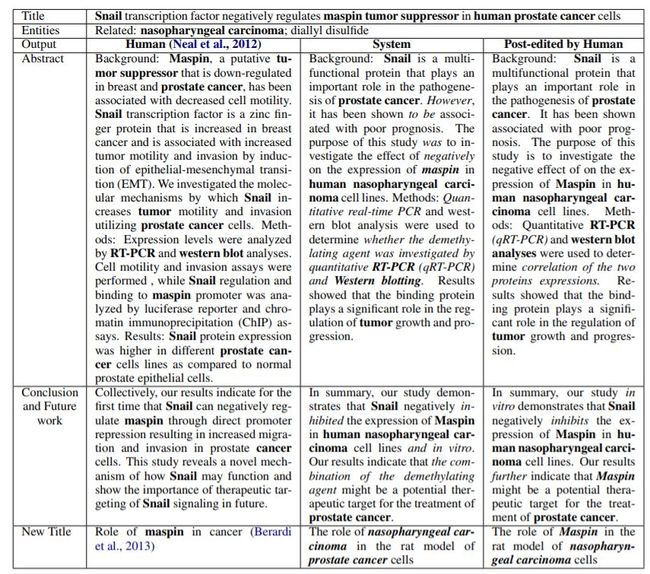
一些后期编辑后的示例。可以看到大多数编辑内容都是形式上的变化。

论文一作Qingyun Wang (王清昀)是伦斯勒理工学院的大四本科生,主修计算机科学与数学双学位。今年8月开始他将在伊利诺伊大学厄巴纳香槟分校读博,主修计算机科学。
王清昀对自然语言处理很感兴趣,专研自然语言生成、信息提取和对话系统,本科期间已发表多篇相关论文。

令人意外的是,王清昀简历中还列举了2项专利,分别是“遥控方便桌”和“家用废油制皂装置”,都是中学时期取得的,其中《遥控方便桌》获得第27届浙江省创新大赛一等奖。

中学时期的王清昀同学
看来,王同学从小就是发明达人啊。AI写论文机不用说也是一大造福人类的好发明,期待王同学继续改进。