强化学习(一)-DQN控制倒立摆
这里,使用gym环境实现仿真,从小车倒立摆的环境模型中,我们不难看到,小车倒立摆的状态空间为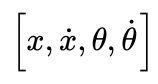 共四个,动作空间为
共四个,动作空间为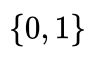 为两个,当动作为1时,施加正向的力10N;当动作为0时,施加负向的力-10N。
为两个,当动作为1时,施加正向的力10N;当动作为0时,施加负向的力-10N。
在码中使用了env.step()函数来对每一步进行仿真,在gym中,env.step()会返回 4 个参数(observation, reward, done, info)。
代码如下:
# -*- coding: utf-8 -*-
import os
import random
import numpy as np
import gym
from collections import deque
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
import pandas as pd
# from DRL import DRL
import matplotlib.pyplot as plt
class DQN():
"""Deep Q-Learning.
"""
def __init__(self):
super(DQN, self).__init__()
self.model = self.build_model()
self.env = gym.make('CartPole-v0')
if not os.path.exists('model'):
os.mkdir('model')
if not os.path.exists('history'):
os.mkdir('history')
# experience replay.
self.memory_buffer = deque(maxlen=2000)
# discount rate for q value.
self.gamma = 0.95
# epsilon of ε-greedy.
self.epsilon = 1.0
# discount rate for epsilon.
self.epsilon_decay = 0.995
# min epsilon of ε-greedy.
self.epsilon_min = 0.01
def load(self):
if os.path.exists('model/dqn.h5'):
self.model.load_weights('model/dqn.h5')
def build_model(self):
"""basic model.
"""
inputs = Input(shape=(4,))
x = Dense(16, activation='relu')(inputs)
x = Dense(16, activation='relu')(x)
x = Dense(2, activation='linear')(x)
model = Model(inputs=inputs, outputs=x)
model.compile(loss='mse', optimizer=Adam(1e-3))
return model
def save_history(self, history, name):
name = os.path.join('history', name)
df = pd.DataFrame.from_dict(history)
df.to_csv(name, index=False, encoding='utf-8')
def play(self, m='pg'):
"""play game with model.
"""
print('play...')
observation = self.env.reset()
reward_sum = 0
random_episodes = 0
while random_episodes < 10:
self.env.render()
x = observation.reshape(-1, 4)
if m == 'pg':
prob = self.model.predict(x)[0][0]
action = 1 if prob > 0.5 else 0
elif m == 'acs':
prob = self.actor.predict(x)[0][0]
action = 1 if prob > 0.5 else 0
else:
action = np.argmax(self.model.predict(x)[0])
observation, reward, done, _ = self.env.step(action)
reward_sum += reward
if done:
print("Reward for this episode was: {}".format(reward_sum))
random_episodes += 1
reward_sum = 0
observation = self.env.reset()
self.env.close()
def egreedy_action(self, state):
"""ε-greedy
Arguments:
state: observation
Returns:
action: action
"""
if np.random.rand() <= self.epsilon:
return random.randint(0, 1)
else:
q_values = self.model.predict(state)[0]
return np.argmax(q_values)
def remember(self, state, action, reward, next_state, done):
"""add data to experience replay.
Arguments:
state: observation
action: action
reward: reward
next_state: next_observation
done: if game done.
"""
item = (state, action, reward, next_state, done)
self.memory_buffer.append(item)
def update_epsilon(self):
"""update epsilon
"""
if self.epsilon >= self.epsilon_min:
self.epsilon *= self.epsilon_decay
def process_batch(self, batch):
"""process batch data
Arguments:
batch: batch size
Returns:
X: states
y: [Q_value1, Q_value2]
"""
# ranchom choice batch data from experience replay.
data = random.sample(self.memory_buffer, batch)
# Q_target。
states = np.array([d[0] for d in data])
next_states = np.array([d[3] for d in data])
y = self.model.predict(states)
q = self.model.predict(next_states)
for i, (_, action, reward, _, done) in enumerate(data):
target = reward
if not done:
target += self.gamma * np.amax(q[i])
y[i][action] = target
return states, y
def train(self, episode, batch):
"""training
Arguments:
episode: game episode
batch: batch size
Returns:
history: training history
"""
history = {'episode': [], 'Episode_reward': [], 'Loss': []}
episode_all = []
Epispde_reward_all = []
Loss_all = []
count = 0
for i in range(episode):
observation = self.env.reset()
reward_sum = 0
loss = np.infty
done = False
self.env.render()
while not done:
# chocie action from ε-greedy.
self.env.render()
x = observation.reshape(-1, 4)
action = self.egreedy_action(x)
observation, reward, done, _ = self.env.step(action)
# add data to experience replay.
reward_sum += reward
self.remember(x[0], action, reward, observation, done)
if len(self.memory_buffer) > batch:
X, y = self.process_batch(batch)
loss = self.model.train_on_batch(X, y)
count += 1
# reduce epsilon pure batch.
self.update_epsilon()
if i % 5 == 0:
history['episode'].append(i)
history['Episode_reward'].append(reward_sum)
history['Loss'].append(loss)
print('Episode: {} | Episode reward: {} | loss: {:.3f} | e:{:.2f}'.format(i, reward_sum, loss, self.epsilon))
episode_all.append(i)
Epispde_reward_all.append(reward_sum)
Loss_all.append(loss)
self.model.save_weights('model/dqn.h5')
return history,episode_all,Epispde_reward_all,Loss_all
if __name__ == '__main__':
model = DQN()
history,episode_all,Epispde_reward_all,Loss_all = model.train(600, 32)
model.save_history(history, 'dqn.csv')
model.load()
model.play()
plt.figure(1)
plt.xlabel('epoch')
plt.ylabel('reward')
plt.title('reward')
plt.plot(episode_all,Epispde_reward_all)
plt.show()
plt.figure(2)
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.title('Loss')
plt.plot(episode_all,Loss_all)
plt.show()DQN的原理这里就不讲了,网上有很多资料,这里,主要给出代码,我觉得代码结构很清晰,分为四个部分即可完成DQN的搭建:
1.使用 model = DQN()初始化网络结构,
2.使用history,episode_all,Epispde_reward_all,Loss_all = model.train(600, 32)训练网络
3.model.load()导入保存的模型
4.model.play()使用保存的模型参数直接控制倒立摆。