动手学无人驾驶(4):基于激光雷达点云数据3D目标检测
上一篇文章《动手学无人驾驶(3):基于激光雷达3D多目标追踪》介绍了3D多目标追踪,多目标追踪里使用的传感器数据为激光雷达Lidar检测到的数据,本文就介绍如何基于激光雷达点云数据进行目标检测。
本文介绍论文:《PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud》
Github项目地址:https://github.com/sshaoshuai/PointRCNN
KITTI数据集百度云下载地址:https://pan.baidu.com/s/1qDzslt5mwI_JkEbumGJSUA 提取码: ct4q
目录
1.KITTI数据集
2.PointRCNN
3.目标检测结果
参考资料
1.KITTI数据集
KITTI目标检测数据集(http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d)中共包含7481张训练图片和7518张测试图片,以及与之相对应的点云数据和label以及calib文件。这里以训练集编号为000008的场景为例介绍KITTI数据集中calib和label文件所含信息。

(training/image_2/000008.png)
Calib文件:在KITTI数据采集过程中使用到了摄像头和激光雷达,采集到的数据坐标分别为摄像头坐标和激光雷达坐标下的测量值,这时就需要calib文件将摄像头与激光雷达进行标定,calib文件通过txt格式来保存。
velodyne:velodyne中存储着激光雷达点云采集到数据,数据以2进制格式存储(.bin),点云数据存储格式为(N,4)。N为激光线束反射点个数,4代表着:(x,y,z,r),分别返回在3个坐标轴上的位置和反射率。
label文件:label文件为标注数据,以txt格式保存,000008.txt中标注的object内容如下:
Car 0.88 3 -0.69 0.00 192.37 402.31 374.00 1.60 1.57 3.23 -2.70 1.74 3.68 -1.29
Car 0.00 1 2.04 334.85 178.94 624.50 372.04 1.57 1.50 3.68 -1.17 1.65 7.86 1.90
Car 0.34 3 -1.84 937.29 197.39 1241.00 374.00 1.39 1.44 3.08 3.81 1.64 6.15 -1.31
Car 0.00 1 -1.33 597.59 176.18 720.90 261.14 1.47 1.60 3.66 1.07 1.55 14.44 -1.25
Car 0.00 0 1.74 741.18 168.83 792.25 208.43 1.70 1.63 4.08 7.24 1.55 33.20 1.95
Car 0.00 0 -1.65 884.52 178.31 956.41 240.18 1.59 1.59 2.47 8.48 1.75 19 -1.25
DontCare -1 -1 -10 800.38 163.67 825.45 184.07 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 859.58 172.34 886.26 194.51 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 801.81 163.96 825.20 183.59 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 826.87 162.28 845.84 178.86 -1 -1 -1 -1000 -1000 -1000 -10
关于label文件的理解可以参考下面的代码:
class Object3d(object):
''' 3d object label '''
def __init__(self, label_file_line):
data = label_file_line.split(' ')
data[1:] = [float(x) for x in data[1:]]
# extract label, truncation, occlusion
self.type = data[0] # 'Car', 'Pedestrian', ...
self.truncation = data[1] # truncated pixel ratio [0..1]
self.occlusion = int(data[2]) # 0=visible, 1=partly occluded, 2=fully occluded, 3=unknown
self.alpha = data[3] # object observation angle [-pi..pi]
# extract 2d bounding box in 0-based coordinates
self.xmin = data[4] # left
self.ymin = data[5] # top
self.xmax = data[6] # right
self.ymax = data[7] # bottom
self.box2d = np.array([self.xmin,self.ymin,self.xmax,self.ymax])
# extract 3d bounding box information
self.h = data[8] # box height
self.w = data[9] # box width
self.l = data[10] # box length (in meters)
self.t = (data[11],data[12],data[13]) # location (x,y,z) in camera coord.
self.ry = data[14] # yaw angle (around Y-axis in camera coordinates) [-pi..pi]
def print_object(self):
print('Type, truncation, occlusion, alpha: %s, %d, %d, %f' % \
(self.type, self.truncation, self.occlusion, self.alpha))
print('2d bbox (x0,y0,x1,y1): %f, %f, %f, %f' % \
(self.xmin, self.ymin, self.xmax, self.ymax))
print('3d bbox h,w,l: %f, %f, %f' % \
(self.h, self.w, self.l))
print('3d bbox location, ry: (%f, %f, %f), %f' % \
(self.t[0],self.t[1],self.t[2],self.ry))2.PointRCNN
3D目标检测模型PointRCNN借鉴了PointNet++和RCNN的思想,提出了自底向上的生成和调整候选检测区域的算法,网络结构如下图所示:
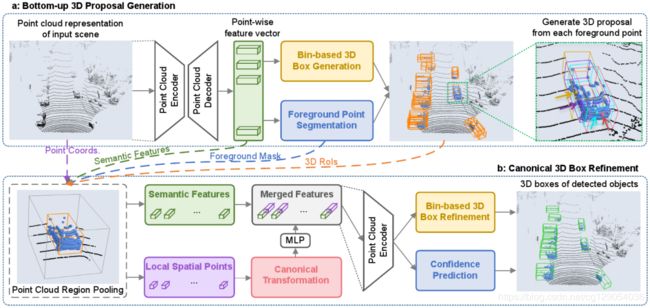
PointRCNN的网络结构分为两个阶段:第一阶段自底向上生成3D候选预测框;第二阶段在规范坐标中对候选预测框进行搜索和微调,得到更为精确的预测框作为检测结果。
第一阶段:对3D点云数据进行语义分割和前背景划分,生成候选预测框,有如下三个关键步骤:
点云特征提取:通过PointNet++对点云数据进行编码和解码,提取点云特征向量。
前景点分割:根据提取的点云特征向量,使用focal loss区分前景点和背景点。focal loss能有效地平衡前景点和背景点比例失衡问题,从而得到更为准确的分类效果。
生成候选框:采用候选框箱模型(bin)的方法,将前背景点分割信息生成预测候选框。
举例来说,将候选框定义为参数(x,y,z,h,w,l,θ)表征的空间中的箱体,其中(x,y,z)为箱体中心坐标,( h,w,l)为箱体在中心坐标方向上的大小,θ为鸟瞰视角上(y方向从上往下看)箱体在x-z平面的角度。
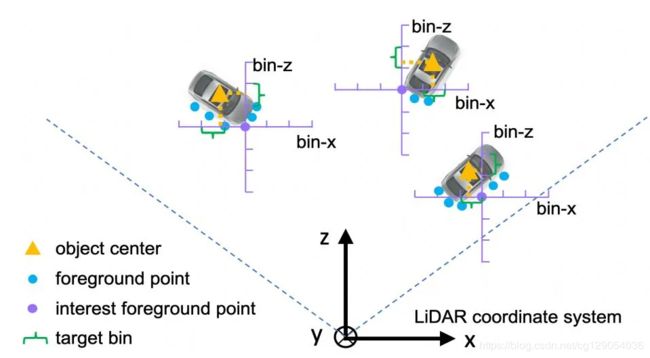
bin的执行方式为:先根据前景点的分割信息粗分其所属的箱体;再在箱体内部对其做回归,得到箱体参数作为预测框;最后对预测框做NMS(Non-Max Suppress,非极大值抑制),得到最终预测候选框。
第二阶段:在规范坐标中微调候选预测框,获得最终的检测结果,有如下四个关键部分:
区域池化:对候选框内每个点的特征进行池化。
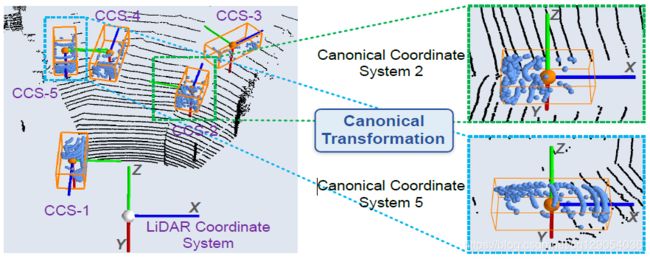
坐标转化:为了更好地获取局部信息,需要将多个候选区域中的前景点坐标(同一个坐标系)转化为局域坐标系中的规范坐标(以预测框为中心点的多个坐标系),如下图所示:
特征编码:将规范坐标时丢失的深度信息、规范后的坐标信息、前后背景语义信息等经过多层感知机提取特征,作为每个点的编码特征。
微调预测框:经过上一步编码后的特征,经PointNet++网络进行特征提取,最后回归得到局部坐标系下的3D预测框。
PointRCNN网络代码如下:
class PointRCNN(nn.Module):
def __init__(self, num_classes, use_xyz=True, mode='TRAIN'):
super().__init__()
assert cfg.RPN.ENABLED or cfg.RCNN.ENABLED
if cfg.RPN.ENABLED:
self.rpn = RPN(use_xyz=use_xyz, mode=mode)
if cfg.RCNN.ENABLED:
rcnn_input_channels = 128 # channels of rpn features
if cfg.RCNN.BACKBONE == 'pointnet':
self.rcnn_net = RCNNNet(num_classes=num_classes, input_channels=rcnn_input_channels, use_xyz=use_xyz)
elif cfg.RCNN.BACKBONE == 'pointsift':
pass
else:
raise NotImplementedError
def forward(self, input_data):
if cfg.RPN.ENABLED:
output = {}
# rpn inference
with torch.set_grad_enabled((not cfg.RPN.FIXED) and self.training):
if cfg.RPN.FIXED:
self.rpn.eval()
rpn_output = self.rpn(input_data)
output.update(rpn_output)
# rcnn inference
if cfg.RCNN.ENABLED:
with torch.no_grad():
rpn_cls, rpn_reg = rpn_output['rpn_cls'], rpn_output['rpn_reg']
backbone_xyz, backbone_features = rpn_output['backbone_xyz'], rpn_output['backbone_features']
rpn_scores_raw = rpn_cls[:, :, 0]
rpn_scores_norm = torch.sigmoid(rpn_scores_raw)
seg_mask = (rpn_scores_norm > cfg.RPN.SCORE_THRESH).float()
pts_depth = torch.norm(backbone_xyz, p=2, dim=2)
# proposal layer
rois, roi_scores_raw = self.rpn.proposal_layer(rpn_scores_raw, rpn_reg, backbone_xyz) # (B, M, 7)
output['rois'] = rois
output['roi_scores_raw'] = roi_scores_raw
output['seg_result'] = seg_mask
rcnn_input_info = {'rpn_xyz': backbone_xyz,
'rpn_features': backbone_features.permute((0, 2, 1)),
'seg_mask': seg_mask,
'roi_boxes3d': rois,
'pts_depth': pts_depth}
if self.training:
rcnn_input_info['gt_boxes3d'] = input_data['gt_boxes3d']
rcnn_output = self.rcnn_net(rcnn_input_info)
output.update(rcnn_output)
elif cfg.RCNN.ENABLED:
output = self.rcnn_net(input_data)
else:
raise NotImplementedError
return output3.目标检测结果
介绍完KITTI数据集和PointRCNN模型后,现在用作者预训练好的模型进行目标预测。
1)首先是准备数据,从百度网盘里下载KITTI数据后按如下方式排放数据:
PointRCNN
├── data
│ ├── KITTI
│ │ ├── ImageSets
│ │ ├── object
│ │ │ ├──training
│ │ │ ├──calib & velodyne & label_2 & image_2
│ │ │ ├──testing
│ │ │ ├──calib & velodyne & image_2
├── lib
├── pointnet2_lib
├── tools2)将预训练好的模型放入/tools文件夹下,执行如下命令,此时会对验证集进行预测:
python eval_rcnn.py --cfg_file cfgs/default.yaml --ckpt PointRCNN.pth --batch_size 1 --eval_mode rcnn --set RPN.LOC_XZ_FINE False
预测结果如下,这里预测的平均准确率略小于原作者预测的。
# 原作者预测结果 Car [email protected], 0.70, 0.70: bbox AP:96.91, 89.53, 88.74 bev AP:90.21, 87.89, 85.51 3d AP:89.19, 78.85, 77.91 aos AP:96.90, 89.41, 88.54# 使用预训练模型输出的结果 Car [email protected], 0.70, 0.70: bbox AP:90.3697, 78.9661, 76.0439 bev AP:88.8698, 75.5572, 69.7311 3d AP:83.3413, 66.9504, 60.1443 aos AP:90.30, 78.51, 75.45
参考资料
飞桨火力全开,重磅上线3D模型:PointNet++、PointRCNN!
PointRCNN地址:https://github.com/sshaoshuai/PointRCNN
论文:《PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud》