hadoop2.2.0集群搭建 centos6.4 32位
centos6.4 32位 hadoop2.2.0 搭建
参考传智播客hadoop1.0的视频以及《Hadoop 技术内幕深入解析 YARN 架构设计与实现原理》中的配置和 网友帖子
环境:VMware 10,jdk:jdk-6u24-linux-i586 centos6.4 32位 hadoop2.2.0
在搭建的过程中遇到很多问题




在搭建的过程中遇到很多问题
1.SSH免登陆,参考传智播客的视频做SSH还是不能免登陆,最后不得已,只得将没有问题的CentOS克隆了过来,这个问题才算解决
2.hadoop2.2.0与hadoop1.x的配置区别很大,有很多地方不能完全按hadoop1.x去配置
一共有2个节点
namenode 192.168.126.101 主机名:hadoop
datanode 192.168.126.102 主机名:slave1
2.hadoop的安装步骤
使用root用户登录
2.1设置静态ip
在centos桌面右上角的图标上,右键修改。
重启网卡,执行命令service network restart
验证:执行命令ifconfig
2.2修改主机名,方便操作 而且主机名比ip名稳定,换ip不换主机名 Linux上vi(vim)编辑器使用教程
执行命令 vi /etc/sysconfig/network 将hostname改为hadoop(192.168.126.101上), slave1(192.168.126.102上)
2.3将主机名和ip绑定 vi /etc/hosts 添加192.168.126.101 ,192.168.126.102
验证 ping hadoop
ctrl+z可以退出ping 重启命令reboot -h now
2.4关闭防火墙 hadoop端口的原因
不安全?
service iptables stop
验证 service iptables status
2.5关闭防火墙自动运行
chkconfig --list |grep iptables 查看iptables服务是否关闭
有打开的
关闭iptables服务
2.6 SSH(secure shell)的免密码登录 远程连接 安全
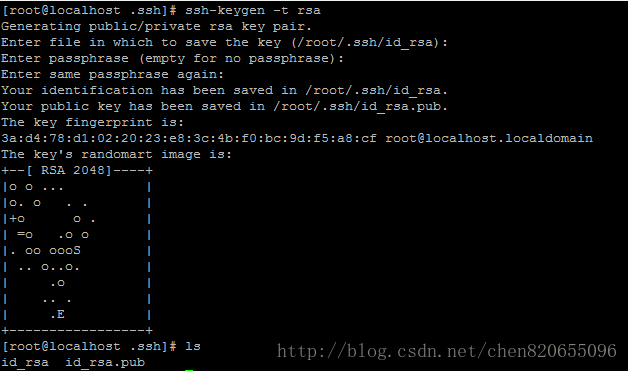
2.6.1 执行命令ssh-keygen -t rsa 产生秘钥,在~/.ssh文件中执行该命令,只需一直回车就可以
2.6.2 执行命令cp id_rsa.pub authorized_keys 即将公钥复制到对方电脑authorized_keys,
必须在.ssh文件夹下执行
验证ssh localhost
2.7安装jdk
2.7.1执行命令rm -rt /usr/local/* 删除所有内容
2.7.2使用winscp把jdk文件从windows复制到/usr/local目录下
2.7.3赋予执行权限 chmod u+x jdk-6u42-linux-i586.bin
2.7.4执行命令 ./jdk-6u42-linux-i586.bin 解压
2.7.5重命名 mv jdk1.6.0_24 jdk
2.7.6设置环境变量 vi /etc/profile 增加两行内容
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
让该设置立即生效 source /etc/profile
验证 java -version
自动补全命令按tab
2.8
2.8.1执行命令 tar -zxvf hadoop-2.2.0.tar.gz 进行解压缩
2.8.2执行命令 mv hadoop-2.2.0 hadoop重命名
2.8.3设置环境变量 vi /etc/profile 增加
export HADOOP_HOME =/usr/local/hadoop
export PATH=.:
$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
这里的配置要注意hadoop2.2.0与hadoop1.x bin目录下的文件有差异
hadoop2.2.0中的bin目录
hadoop1.x中的bin目录
让该设置立即生效 source /etc/profile
2.8.4 修改hadoop的配置文件,位于HADOOP_HOME/etc下
1)设置环境变量。在 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 中,添加 JAVA 安装目录,注意路径要改成自己jdk所在的路径,命令如下:export JAVA_HOME=/usr/local/jdk修改 conf 目录下的 mapred-site.xml、core-site.xml、yarn-site.xml 和 hdfs-site.xml 四个文件,在与 之间添加的内容见下面的介绍。2)在 ${HADOOP_HOME}/etc/hadoop/ 下, 将 mapred-site.xml.templat 重命名成 mapred-site.xml(与hadoop1不同的地方),并添加以下内容:mapreduce.framework.name yarn 【解释】相比于 Hadoop1.0,用户无须再配置 mapred.job.tracker,这是因为 JobTracker相关实现已变成客户端的一个库(实际上在 Hadoop 2.0 中,JobTracker 已经不存在,它的功能由另外一个称为 MRAppMaster 的组件实现),它可能被随机调度到任何一个 slave 上,也就是它的位置是动态生成的。需要注意的是,在该配置文件中需用 mapreduce.framework.name 指定采用的运行时框架的名称,在此指定“yarn”。3)在 ${HADOOP_HOME}/etc/hadoop/ 中,修改 core-site.xml,为了简单,我们仍采用 Hadoop 1.0 中的 HDFS 工作模式(不配置 HDFS Federation), 修改后如下,其中要填自己的hostname,而端口好像不是确定的,待研究:fs.default.name hdfs://hostname: 8020 其中,YARN001 表示节点的 IP 或者 host。4)在 ${HADOOP_HOME}/etc/hadoop/ 中,修改 yarn-site.xml,修改后如下:yarn.nodemanager.aux-services mapreduce-shuffle 【解释】为了能够运行 MapReduce 程序,需要让各个 NodeManager 在启动时加载shuffle server,shuffle server 实际上是 Jetty/Netty Server,Reduce Task 通过该 server 从各个NodeManager 上远程复制 Map Task 产生的中间结果。上面增加的两个配置均用于指定 shuffleserver。5)修改 ${HADCOP_HOME}/etc/hadoop 中的 hdfs-site.xml 文件:dfs.replication 1 【解释】默认情况下,HDFS 数据块副本数是 3,而在集群规模小于 3 的集群中该参数会导致出现错误,这可通过将 dfs.replication 调整为 1 解决。注意 如果你是在虚拟机中搭建 Hadoop 环境,且虚拟机经常关闭与重启,为了避免每次重新虚拟机后启动 Hadoop 时出现各种问题,建议在 core-site.xml 中将 hadoop.tmp.dir 属性设置为一个非 /tmp 目录,比如 /data 或者 /home/dongxicheng/data(注意该目录对当前用户需具有读写权限)。 我没有改注意 修改slaves文件,把node节点的机器名添加进去,如下图:
2.8.5启动 Hadoop。
在 Hadoop 安装目录中,按以下三步操作启动 Hadoop,我们单步启动每一个服务,以
便于排查错误,如果某一个服务没有启动成功,可查看对应的日志查看启动失败原因。
1) 格式化 HDFS,命令如下:
bin/hadoop namenode -format
2)启动 HDFS。你可以使用以下命令分别启动 NameNode 和 DataNode:
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
如果有多个 DataNode,可使用 hadoop-daemons.sh 启动所有 DataNode,具体命令如下:
sbin/hadoop-daemons.sh start datanode
你也可以使用以下命令一次性启动 NameNode 和所有 DataNode:
sbin/ start-dfs.sh
3)启动 YARN。你可以使用以下命令分别启动 ResourceManager 和 NodeManager:
sbin/yarn-daemon.sh start resourcemanagersbin/yarn-daemon.sh start nodemanager
如果有多个 NodeManager,可使用 yarn-daemon.sh 启动所有 NodeManager,具体命令如下:
sbin/yarn-daemon.sh start nodemanager
你也可以使用以下命令一次性启动 ResourceManager 和所有 NodeManager:
sbin/start-yarn.sh
通过如下 jps 命令查看是否启动成功:
dong@YARN001:/opt/hadoop/hadoop-2.0$ jps
27577 NameNode
30315 ResourceManager
27924 SecondaryNameNode
16803 NodeManager
可以在NameNode机器上面执行:hdfs dfsadmin -report 查看下DataNode是否连上NameNode:hdfs dfsadmin -report
如上图,就说明搭建成功了。如果jps看两台机器没问题,但是这里面Datanodes是0的话,说明DataNode没能连上,可以从它们各自的logs目录下看到日志文件。一般出现这个情况,都是操作系统环境的问题,防火墙没关,或者hosts文件设置不对。
