【TCP】Connection reset by peer 原因分析定位
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。
背景
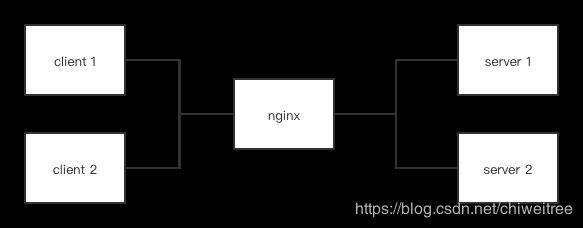
client和server通过websocket协议通信,长连接保活,server前有nginx做反向代理,client和server是多对多关系;
server端定时给client下发任务,client执行任务并将结果上报给server,client还会定时给server发送心跳保活连接。
现象
系统运行一段时间之后,nginx上error日志频繁报错,如下:
2020/04/15 18:02:51 [error] 374#0: *1917238 send() failed (104: Connection reset by peer) while proxying upgraded connection, client: 172.28.25.222, server: localhost, request: "GET /ws/358/5c5d8dafac7f4586a751ff4c68fb2999/websocket HTTP/1.1", upstream: "http://172.28.72.77:8899/ws/358/5c5d8dafac7f4586a751ff4c68fb2999/websocket", host: "172.28.72.114:8443"
2020/04/15 18:03:03 [error] 374#0: *1913375 send() failed (104: Connection reset by peer) while proxying upgraded connection, client: 172.28.25.214, server: localhost, request: "GET /ws/453/60c9a5af41374f9dbaad4d5444d25c96/websocket HTTP/1.1", upstream: "http://172.28.72.77:8888/ws/453/60c9a5af41374f9dbaad4d5444d25c96/websocket", host: "172.28.72.114:8443"nginx端频繁重置连接,导致连接不可用,通信异常
分析
抓包
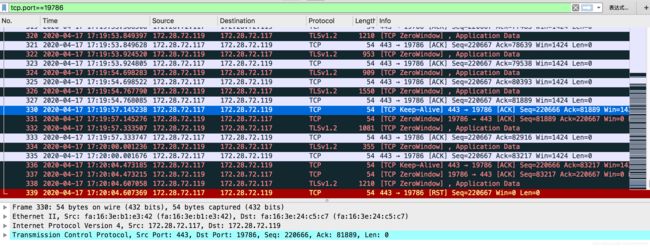
119是client,117是nginx
从图中看出client给服务端发送了很多 tcp zero window的包,说明客户端已经处理不过来了,告诉对端,不要给我发包了,我不行了;
同时,服务端会定期给客户端发送tcp keepalive链路保活的包,在发送多次zero window后仍然没有有效数据发送,服务端RESET关闭连接,导致服务异常;
在服务器netstat发现如下现象:
client客户端
[apprun@vhost18 ~]$ netstat -tnulpao|grep 443
tcp6 362708 0 172.28.72.119:63132 172.28.72.117:443 ESTABLISHED 32278/java off (0.00/0/0)
tcp6 0 0 172.28.72.119:63192 172.28.72.117:443 ESTABLISHED 32278/java off (0.00/0/0)nginx server服务端
[apprun@newvhost02 ~]$ netstat -anop|grep 443
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 13307/nginx: worker off (0.00/0/0)
tcp 0 108528 172.28.72.117:443 172.28.72.119:63132 ESTABLISHED 13308/nginx: worker probe (0.16/0/0)客户端recev-Q阻塞,表明客户端处理不过来,操作系统接收缓冲区阻塞,程序没有及时消费掉;
nginx服务端send-Q阻塞,不能及时发出去,表明下游程序收不过来,和上述客户端现象表现一致;
同时客户端的系统资源也很充裕,没有任何瓶颈。
解决
查看客户端处理代码逻辑,发现单线程处理,效率低下,改成异步线程池提交处理的方式,问题解决。
总结
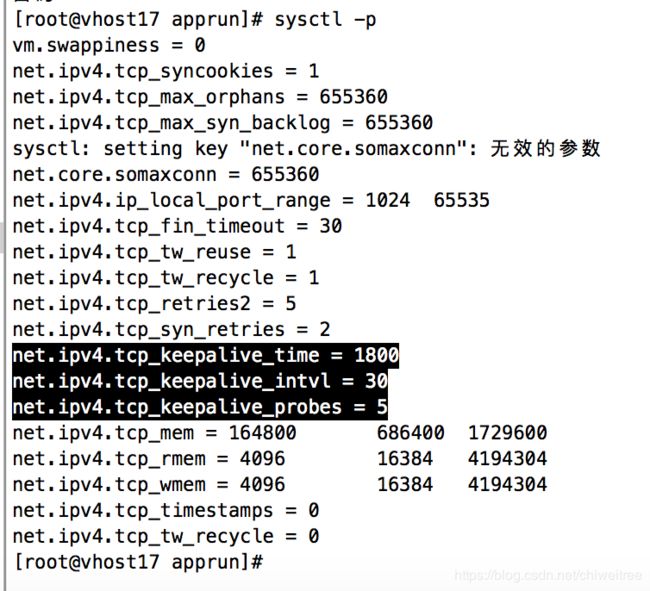
linux操作系统的上述三个参数,跟此次现象有关:
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 5tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测消息的时间,即允许的持续空闲时间。默认值为7200s(2h)。
tcp_keepalive_intvl,保活探测消息的发送频率。默认值为75s。
发送频率tcp_keepalive_intvl乘以发送次数tcp_keepalive_probes,就得到了从开始探测直到放弃探测确定连接断开的时间,大约为11min。
tcp_keepalive_probes,TCP发送保活探测消息以确定连接是否已断开的次数。默认值为9(次)。
从上述抓包和操作系统三个参数配置,并没有通过包和操作系统参数值对应上,当时环境存在多个client和多个server,抓包数量有限,但是综合情况来看RESET应该是跟这三个操作系统参数有关,但本质原因还是客户端处理不过来,导致数据积压,TCP零窗口。