贝叶斯⑤——搜狗新闻分类实战(jieba + TF-IDF + 贝叶斯)
贝叶斯机器学习系列:
贝叶斯①——贝叶斯原理篇(联合概率&条件概率&贝叶斯定理&拉普拉斯平滑)
贝叶斯②——贝叶斯3种分类模型及Sklearn使用(高斯&多项式&伯努利)
贝叶斯③——Python实现贝叶斯文本分类(伯努利&多项式模型对比)
贝叶斯④——Sklean新闻分类(TF-IDF)
贝叶斯⑥——银行借贷模型(贝叶斯与决策树对比)
分类过程:
1、导入文件并用jieba分词
2、随机抽取训练和测试样本
3、建立tf-idf词频权重矩阵
4、朴素贝叶斯分类(采用多项式模型)
数据集下载
选取了搜狗新闻下财经,体育、教育等九大类别共90篇文章,本博文将使用朴素贝叶斯进行分类实战(数据集文末有下载方式,方便你实操一遍)
一、读取文件并用jieba分词
import os
import jieba
# 读取所有文件并组成矩阵,特征和类别单独存放
fold_path = r'C:\Users\cindy407\Desktop\Naive-Bayes-Text-Classifier\Database\SogouC\Sample'
folder_list = os.listdir(fold_path) # 读取文件夹列表
print(folder_list)
artcilt_list = []
class_list = []
for fold in folder_list: # 读取子文件夹列表
new_fold_path = os.path.join(fold_path,fold) # 将路径拼接
files = os.listdir(new_fold_path) # 再读取子文件夹
for file in files: # 读取文件
with open(os.path.join(new_fold_path,file),'r',encoding='utf-8') as fp:
article = fp.read()
article1 =','.join(jieba.cut(article,cut_all=False)) # 精确模式分词
artcilt_list.append(article1) # 组成列表
class_list.append(fold)
print(artcilt_list)
print(class_list)
分词后文章如下:
![]()
类别如下:
![]()
二、随机抽取训练和测试样本
```python
# 将特征与类别组合并打乱,再随机抽取训练集和测试集
import random
data_list = list(zip(artcilt_list,class_list))
random.shuffle(data_list) # 打乱顺序
test_size = 0.2
index = int(len(data_list)*test_size) + 1
train_data_list = data_list[:index]
test_data_list = data_list[:index]
train_data,train_class = zip(*train_data_list)
test_data,test_class = zip(*test_data_list)
# 也可以用sklearn库中的train_test_split打乱并随机抽取特定比例的训练集和测试集
# from sklearn.model_selection import train_test_split
# train_data,test_data,train_class,test_class = train_test_split(artcilt_list,class_list,test_size=test_size,shuffle=True)
三、建立tf-idf词频权重矩阵
# 建立tf-idf词频权重矩阵
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
tfidf = TfidfVectorizer()
tf_train_data = tfidf.fit_transform(train_data)
np.set_printoptions(threshold=np.nan)
print(tfidf.vocabulary_) # 输出词典及位置
print(tfidf.idf_) # 输出逆向文件频率
输出词典:
![]()
输出TF-IDF:

四、朴素贝叶斯分类
# 用贝叶斯多项式模型分类并输出分类结果
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
clf = MultinomialNB(fit_prior=True)
clf.fit(tf_train_data,train_class)
tf_test_data = tfidf.transform(test_data)
y_pred = clf.predict(tf_test_data)
print('训练集分数:', clf.score(tf_train_data,train_class))
print('测试集分数:', metrics.accuracy_score(y_pred,test_class))
print('混淆矩阵:')
print(confusion_matrix(y_pred,test_class))
print('分类报告:', classification_report(y_pred,test_class))

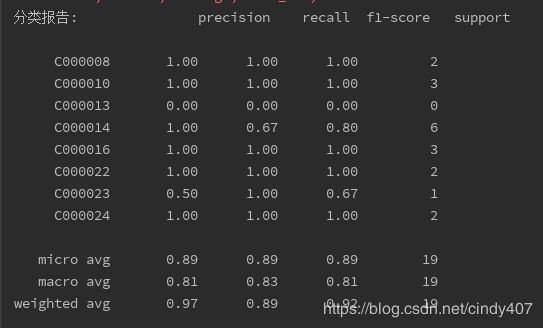
训练集分数和测试集分数一样,都是89,效果不算特别好,可能是由于文章数量过少的原因
上一篇分类文档单词数特别少,使用伯努利效果优于多项式,此篇特征量已经达到 3518,要多很多,再对比一下效果
clf = BernoulliNB(fit_prior=True)
clf.fit(tf_train_data,train_class)
tf_test_data = tfidf.transform(test_data)
y_pred = clf.predict(tf_test_data)
print('训练集分数:', clf.score(tf_train_data,train_class))
print('测试集分数:', metrics.accuracy_score(y_pred,test_class))
print('混淆矩阵:')
print(confusion_matrix(y_pred,test_class))
print('分类报告:', classification_report(y_pred,test_class))

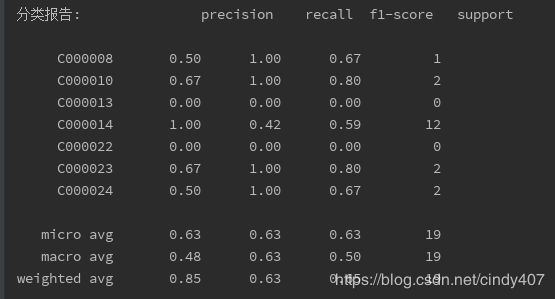
果然效果还是要差一些,进一步佐证了特征量越多,多项式优势越明显
总结一下要点:
① TfidfVectorizer没有分词能力,如果是英文有空格隔开,可以不用对原文本进行分词处理,但是中文要先分词
② 如果特征量较大,应优先选择多项式模型进行文本分类
本人互联网数据分析师,目前已出Excel,SQL,Pandas,Matplotlib,Seaborn,机器学习,统计学,个性推荐,关联算法,工作总结系列。
微信搜索并关注 " 数据小斑马" 公众号
1、回复“搜狗”就可以领取文中数据集
2、回复“数据分析”可以免费获取下方15本数据分析师必备学习书籍一套
