百度paddlepaddle《青春有你2》Python小白逆袭大神技术打卡学习总结
之前参加过百度飞桨深度学习CV疫情训练营7天打卡学习,从了解概念到简单的使用paddle做一些口罩监测类的识别任务,收获特别多,这次又参加了更加基础的小白训练营,感觉对深度学习、padddle,paddleHub的了解又进一步加深,早上晨会的时候还向领导推荐EasyDL,并结合我对公司业务了解谈了自己的建议和想法,以及我们部门未来的技术方向问题。领导很认同,并要了EasyDL的应用案例网址了解一下。所以真心感谢百度paddle训练营的老师团队和班主任,感谢百度提供了这么好的活动和平台,真良心。
很喜欢训练营的学习氛围和形式,在微信学习群进行直播、答疑、互动等,在AIstudio进行练习实践,做作业遇到问题去群里翻阅聊天记录,查查讨论区,网上搜索资料,这种环境让我感觉进步很快。我自己很喜欢用思维模型分析工作和生活中的一些事情,在这里分享一个圈外培训的学习方法把学到的知识转化为能力:
1.掌握20%的核心知识; 2.知识和问题相互靠拢 3.系统化训练。
最后进行一下技术问题总结:
Day1-人工智能概述与入门基础:
掌握Python的基础语法知识
基础知识很重要,如果不能掌握熟练,做作业时会遇到各种奇怪的问题,比如中文符号,缺少操作符,符号不对应,拼写错误,路径找不到等。特别是判断条件循环的综合使用,几乎每个作业都会涉及。推荐去菜鸟教程里面Python练习页面重复练习直至熟练。
Day2-Python进阶
熟悉 Python 的基础语法,并掌握 NumPy,Pandas 及其他基础工具模块的使用对深度学习实践是非常重要的!
Python数据结构(列表、元组、字典和集合)
Python面向对象
Python JSON(非常重要,数据读写)
Python 异常处理(try except)
常见Linux命令(ls,unzip,zip,mkdir,touch,cp,mv,rm等)
熟悉并掌握爬虫数据抓取技术(request,beautifulsoup等),根据具体的页面结构进行调整
#coding=utf-8 #!/usr/bin/python # 导入requests库 import requests # 导入文件操作库 import os import bs4 from bs4 import BeautifulSoup import sys import importlib import random import time importlib.reload(sys) # 越多越好 meizi_headers = [ "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14", "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)", 'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11', 'Opera/9.25 (Windows NT 5.1; U; en)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)', 'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12', 'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9', "Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7", "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0", 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36' ] # 给请求指定一个请求头来模拟chrome浏览器 global headers headers = {'User-Agent': random.choice(meizi_headers)} # 爬图地址 mziTu = 'http://www.win4000.com/mt/yushuxin_1.html' ''' http://www.win4000.com/mt/yushuxin_1.html ''' # 定义存储位置 global save_path save_path = 'D:\pmp\zhao' # 创建文件夹 def createFile(file_path): if os.path.exists(file_path) is False: os.makedirs(file_path) # 切换路径至上面创建的文件夹 os.chdir(file_path) # 下载文件 # def download(): # global headers # #res_sub = requests.get(page_no, headers=headers) # # 解析html # #soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # # 获取页面的栏目地址 # #all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') # #all_a =['http://www.win4000.com/mt/yushuxin_1.html', 'http://www.win4000.com/mt/yushuxin_2.html', 'http://www.win4000.com/mt/yushuxin_2.html'] # # all_a = ['https://www.kuyv.cn/star/xujiaqi/photo/1/', 'https://www.kuyv.cn/star/xujiaqi/photo/2/', 'https://www.kuyv.cn/star/xujiaqi/photo/3/', 'https://www.kuyv.cn/star/xujiaqi/photo/4/', 'https://www.kuyv.cn/star/xujiaqi/photo/5/', 'https://www.kuyv.cn/star/xujiaqi/photo/6/', 'https://www.kuyv.cn/star/xujiaqi/photo/11/'] # all_a = ['http://tushuo.jk51.com/tushuo/6817012.html', 'http://tushuo.jk51.com/tushuo/6817012_p2.html', 'http://tushuo.jk51.com/tushuo/6817012_p3.html', 'http://tushuo.jk51.com/tushuo/6817012_p4.html', 'http://tushuo.jk51.com/tushuo/6817012_p5.html', 'http://tushuo.jk51.com/tushuo/6817012_p6.html', 'http://tushuo.jk51.com/tushuo/6817012_p7.html'] # count = 0 # imgnum = 0 # for a in all_a: # count = count + 1 # if (count ) : # headers = {'User-Agent': random.choice(meizi_headers)} # print("内页第几页:" + str(count)) # # 提取href # #href = a.attrs['href'] # href = a # print(222, a) # print("套图地址:" + href) # res_sub_1 = requests.get(href, headers=headers) # soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') # #print(soup_sub_1) # #break # # ------ 这里最好使用异常处理 ------ # try: # # 获取套图的最大数量 # # imgs = soup_sub_1.find('div', class_='detail').find_all('img') # #print(111, imgs) # # for img in imgs : # # if isinstance(img, bs4.element.Tag): # imgnum +=1 # print(imgnum) # # 提取src # url = 'http:'+ img.attrs['src'] # array = url.split('/') # file_name = str(imgnum)+'.jpg' # # 防盗链加入Referer # headers = {'User-Agent': random.choice(meizi_headers), 'Referer': url} # img = requests.get(url, headers=headers) # print('开始保存图片', img) # f = open(file_name, 'ab') # f.write(img.content) # print(file_name, '图片保存成功!') # f.close() # except Exception as e: # print(e) # 下载文件 def download(): global headers #res_sub = requests.get(page_no, headers=headers) # 解析html #soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # 获取页面的栏目地址 #all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') #all_a =['http://www.win4000.com/mt/yushuxin_1.html', 'http://www.win4000.com/mt/yushuxin_2.html', 'http://www.win4000.com/mt/yushuxin_2.html'] headers = {'User-Agent': random.choice(meizi_headers)} # 提取href #href = a.attrs['href'] href = 'https://m.douban.com/movie/celebrity/1424975/all_photos' res_sub_1 = requests.get(href, headers=headers) soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') print(000, soup_sub_1) # ------ 这里最好使用异常处理 ------ try: # 获取套图的最大数量 imgnum = 0 imgs = soup_sub_1.find('ul', {"id": "photolist"}).find_all('a') print(111, imgs) for img in imgs : if isinstance(img, bs4.element.Tag): imgnum +=1 print(999, imgnum) # 提取src url = img.attrs['style'][22:-1] print(url) break array = url.split('/') file_name = str(imgnum)+'.jpg' # 防盗链加入Referer headers = {'User-Agent': random.choice(meizi_headers), 'Referer': url} img = requests.get(url, headers=headers) print('开始保存图片', img) f = open(file_name, 'ab') f.write(img.content) print(file_name, '图片保存成功!') f.close() except Exception as e: print(e) # 主方法 def main(): res = requests.get(mziTu, headers=headers) # 使用自带的html.parser解析 soup = BeautifulSoup(res.text, 'html.parser') # 创建文件夹 createFile(save_path) download() # # 获取首页总页数 # img_max = soup.find('div', class_='nav-links').find_all('a')[3].text # # print("总页数:"+img_max) # for i in range(1, int(img_max) + 1): # # 获取每页的URL地址 # if i == 1: # page = mziTu # else: # page = mziTu + 'page/' + str(i) # file = save_path + '\\' + str(i) # createFile(file) # # 下载每页的图片 # print("套图页码:" + page) # download(page, file) if __name__ == '__main__': main()
Day3-人工智能常用Python库
Python被大量应用在数据挖掘和深度学习领域,其中使用极其广泛的是Numpy、pandas、Matplotlib、PIL等库。
主要技术点是利用numpy,pandas对数据进行分析处理,使用Matplotlib,PIL进行图片绘制展示等
Day4-PaddleHub体验与应用
PaddleHub是飞桨预训练模型管理和迁移学习工具,通过PaddleHub开发者可以使用高质量的预训练模型结合Fine-tune API快速完成迁移学习到应用部署的全流程工作。其提供了飞桨生态下的高质量预训练模型,涵盖了图像分类、目标检测、词法分析、语义模型、情感分析、视频分类、图像生成、图像分割、文本审核、关键点检测等主流模型。更多模型详情请查看官网:https://www.paddlepaddle.org.cn/hub
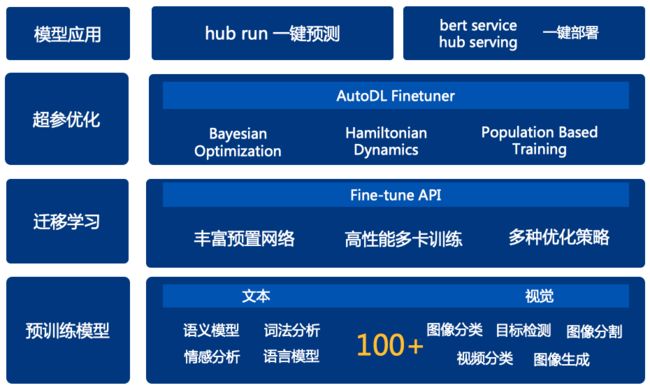
PaddlueHub让你像使用软件操作一样使用深度学习模型进行工作处理。
Day5-EasyDL体验与作业发布
1. 了解EasyDL的产品概念和应用场景
EasyDL 为企业及开发者提供了从完善安全的数据服务、大规模分布式模型训练、丰富灵活的模型部署到预测的一站式服务
2. 综合大作业(评论抓取,词频统计和可视化,内容审核