TF入门03-实现线性回归&逻辑回归
之前,我们介绍了TF的运算图、会话以及基本的ops,本文使用前面介绍的东西实现两个简单的算法,分别是线性回归和逻辑回归。本文的内容安排如下:
- 实现线性回归
- 算法优化
- 实现逻辑回归
1. 线性回归
1.1 问题描述
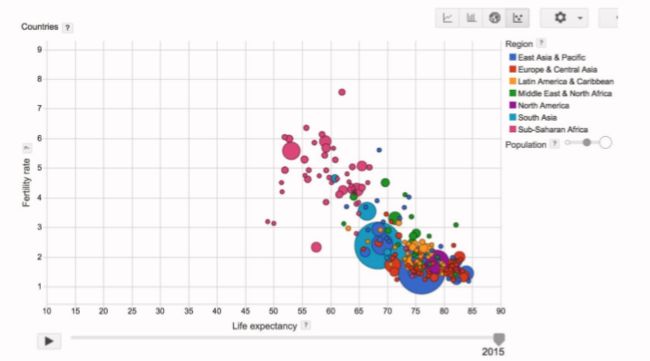
我们将收集到的不同国家的出生率以及平均寿命。通过上图可以发现出生率越高的国家,人口的平均寿命大概率上会越低。
现在,我们想使用线性回归来对这种现象进行描述,之后给定一个国家的出生率后可以来预测其人口的平均寿命。
数据描述如下:

自变量X为出生率,数据类型为float,因变量Y为平均寿命,类型为float;数据集一共有190个数据点。
模型构建:我们使用一种简单的算法-线性回归来描述这个模型, Y = w X + b Y = wX + b Y=wX+b, 其中,w,b均为实数。
1.2 方法实现
我们之前知道TF将计算图的定义与运行分离开来,模型实现时主要分为两个阶段:
- 定义运算图
- 使用会话执行运算图,得到计算结果
我们先来进行运算图的定义,这一部分主要是根据公式将模型在graph中定义。
Step1:读取数据
# read_birth_lift_data:读取txt文件数据
data, n_samples = utils.read_birth_life_data(DATA_FILE)
Step2:创建占位符,用于加载数据和标签
#tf.placeholder(dtype, shape=None, name=None)
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
Step3:创建权重参数weight和bias
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
Step 4: 构建模型预测Y
Y_predicted = w * X + b
Step 5:定义损失函数
loss = tf.square(Y_predicted - Y, name='loss')
Step 6: 创建优化器
opt = tf.train.GradientDescentOptimizer(learning_rate=0.001)
optimizer = opt.minimize(loss)
第二阶段:运行计算图
这个阶段又可以分为:
- 变量初始化
- 运行优化器,同时使用feed_dict传递数据
完整代码如下:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import utils
DATA_FILE = 'data/birth_life_2010.txt'
# Step 1: read in data from the .txt file
data, n_samples = utils.read_birth_life_data(DATA_FILE)
print(type(data))
# Step 2: create placeholders for X (birth rate) and Y (life expectancy)
X = tf.placeholder(tf.float32, name='X')
Y = tf.placeholder(tf.float32, name='Y')
# Step 3: create weight and bias, initialized to 0.0
# Make sure to use tf.get_variable
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: build model to predict Y
Y_predicted = w * X + b
# Step 5: use the square error as the loss function
loss = tf.square(Y_predicted - Y, name='loss')
# Step 6: using gradient descent with learning rate of 0.001 to minimize loss
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
start = time.time()
# Create a filewriter to write the model's graph to TensorBoard
writer = tf.summary.FileWriter('./graphs/linreg', tf.get_default_graph())
with tf.Session() as sess:
# Step 7: initialize the necessary variables, in this case, w and b
sess.run(tf.global_variables_initializer())
# Step 8: train the model for 100 epochs
for i in range(100):
total_loss = 0
for x, y in data:
# Execute train_op and get the value of loss.
# Don't forget to feed in data for placeholders
_, loss_ = sess.run([optimizer, loss], feed_dict={X:x, Y:y})
total_loss += loss_
print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
# close the writer when you're done using it
writer.close()
# Step 9: output the values of w and b
w_out, b_out = sess.run([w, b])
print(w_out, b_out)
print('Took: %f seconds' %(time.time() - start))
值得注意的一点是,上述代码有一行为:
_, loss_ = sess.run([optimizer, loss], feed_dict={X:x, Y:y})
这行用于将数据通过feed_dict传送到placeholder中,我们想要运行的是optimizer和loss;其中一个返回值没用,因此我们用下划线代替,第二个为loss_,要注意返回值和run的fetches里的名字不能相同,否则报错TypeError: Fetch argument 841.0 has invalid type 原因在于,fetches里的对象为tensor,返回值为numpy数组,因此下次循环的时候会报类型错误TypeError。
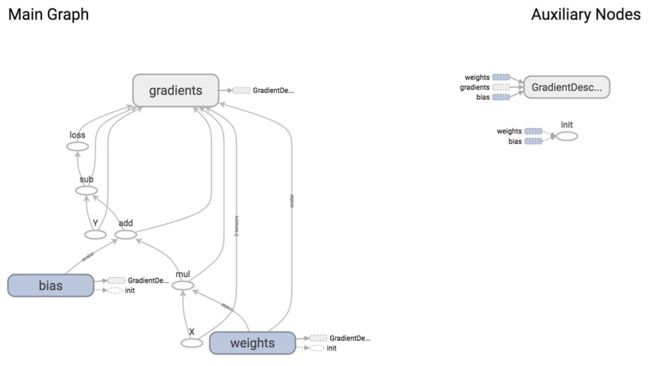
线性回归模型的计算图如下所示:
我们将训练后的参数使用折线图进行可视化:
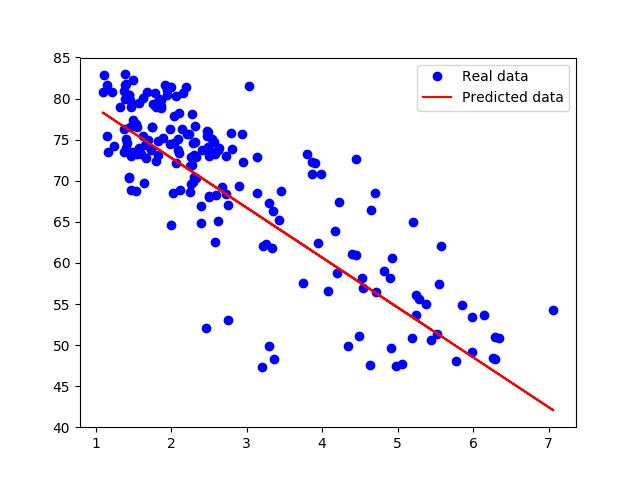
可以看到,模型能对数据走向进行模拟,虽然模拟效果不够精准,毕竟我们的模型非常简单。
1.3 分析优化
损失函数
通过观察上面的算法模拟图,我们可以看到数据中存在一些离群点,如左下方的几个点,这些点会将拟合线向它们这边**“拉”**,进而导致模型准确度下降。因为我们使用的损失函数为平方损失,这样那些模拟特别差的点对损失函数的贡献会进一步加大,我们需要想办法降低离群点对损失函数的“贡献”,降低其占得权重,因此,这里使用Huber损失:如果预测值与标签值之间的差距很小,损失值为平方差;如果差距过大,采用绝对差。Huber损失对离群点不敏感,更鲁棒。
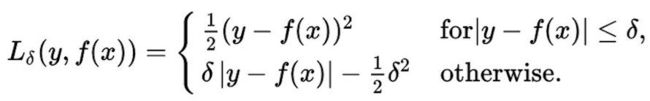
接下来的问题是我们如何使用TF实现这个分段函数呢?答案是使用TF的控制流ops:
tf.cond(condition, fn1, fn2, name=None)
这个函数类似于C++中的三元运算符z = cond ? x : y,含义为如果condition条件为真,执行函数fn1,否则执行函数fn2。huber实现代码如下:
def huber_loss(labels, preds, delta=14.0):
residual = tf.abs(labels - preds)
def f1(): return 0.5 * tf.square(residual)
def f2(): return delta * residual - 0.5 * tf.square(delta)
return tf.cond(residual < delta, f1, f2)
使用huber_loss重新训练后,计算权重为w: -5.883589, b: 85.124306,两种损失的训练结果如下:
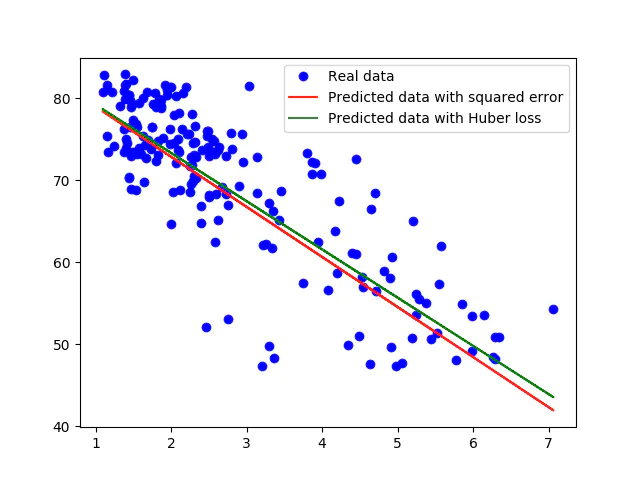
可以看到采用huber的曲线将平方差曲线又“拉回去了”,减少离群点对模型的影响。
数据输入tf.data
之前的视线中,我们使用tf.placeholder结合feed_dict来实现数据的输入,这种方法的优点在于将数据的处理过程和TF分离开来,可以在Python中实现数据的处理;缺点在于用户通常用单线程实现这个处理过程,产生数据瓶颈进而拖慢程序的运行效率。
TensorFlow为数据处理提供了一种数据结构:队列。这种方式允许你进行数据流水线、多线程并行化进而能加快数据加载到placeholder的速度。但是,队列难以使用而且容易崩溃。
TensorFlow还提供了另一种方式为tf.data,它比placeholders方式速度快,比队列方式更简单,还不容易崩溃。那么tf.data模块应该怎么使用呢?让我们接着往下看。
在之前的线性回归中,我们的输入数据存储在numpy数组data中,其中每一行为一个(x,y)pair对,对应图中的一个数据点。为了将data导入到TensorFlow模型中,我们分别为x(特征)和y(标签)创建placeholder,之后再Step8中迭代数据集并使用feed_dict将数据feed到placeholders中。当然,我们也可以使用一个批量的数据来进行更新,但是这个过程的关键点在于将numpy形式数据传送到TensorFlow模型中这个过程是比较缓慢的,限制了其他ops的执行速度。
使用tf.data存储数据,保存对象是一个tf.data.Dataset对象,而不是非TensorFlow对象。我们可以从tensors创建一个Dataset对象:
tf.data.Dataset.from_tensor_slices((features, labels))
其中,features 和labels应该是tensors形式,但由于TF能无缝集成Numpy,因此它们也可以是Numpy数组。这里的初始化为:
dataset = tf.data.Dataset.from_tensor_slices((data[:,0], data[:,1]))
此外,你还可以使用不同的文件格式解析器从不同格式的文件中创建tf.data.Dataset对象:
tf.data.TextLineDataset(filenames):文件中的每一行被解析为一个数据。这种方式适用于被换行符分割的数据,如机器翻译的数据以及csv格式数据tf.data.FixedLengthRecordDataset(filenames):文件中每个数据点的长度相同。适用于每个数据点长度相同的数据集,如CIFAR、ImageNet数据集tf.data.TFRecord(filenames):适用于以tfrecord格式存储的数据
dataset = tf.data.FixedLengthRecordDataset([file1, file2,...])
将数据转换成TF Dataset对象后,我们可以用一个迭代器iterator对数据集进行遍历。每次调用get_next()函数,迭代器迭代Dataset对象,并返回一个样本或者一个批量的样本数据。我们先介绍make_one_shot_iterator(),
iterator = dataset.make_one_shot_iterator()
X, Y = iterator.get_next() # X:出生率,Y:平均寿命
每次执行ops X,Y时,我们可以得到一个新的数据点:
with tf.Session() as sess:
print(sess.run([X, Y])) # >> [1.822, 74.82825]
print(sess.run([X, Y])) # >> [3.869, 70.81949]
print(sess.run([X, Y])) # >> [3.911, 72.15066]
之后Y_predicted的计算和使用placeholder方式相同,不同之处在于执行运算图时,不用再使用feed_dict传送数据。
for i in range(100): # 100 epochs
total_loss = 0
try:
while True:
sess.run([optimizer])
except tf.errors.OutOfRangeError:
pass
因为TF不会自动捕获OutOfRangeError,因此我们需要显式地进行处理。运行上述代码后,可以看到total_loss在第一个epoch中可以得到一个非零值,之后的epoch,total_loss一直为0。原因在于dataset.make_one_shot_iterator(),这种方式顾名思义只能用于一次数据迭代过程,而且这种方式不用自己初始化.在数据集的第一次迭代完成之后,下一个epoch时,iterator没有重新初始化,所以total_loss一直为0.
如果要完成多次epochs的训练,可以使用dataset.make_initializable_iterator().每次epoch之初,你必须重新初始化迭代器iterator。
iterator = dataset.make_initializable_iterator()
...
for i in range(100):
sess.run(iterator.initializer)
total_loss = 0
try:
while True:
sess.run(optimizer)
except tf.errors.OutOfRangeError:
pass
使用tf.data.Dataset对象,你可以使用一行代码完成数据的batch、shuffle和repeat,也可以将数据集中的每个对象进行转换进而创建一个新的数据集。
dataset = dataset.shuffle(1000) # 数据顺序打乱
dataset = dataset.repeat(100) # 用于多个epoch的数据遍历
dataset = dataset.batch(128) # 将数据划分为batch,每个batch大小为128
# 将每个元素转换为one_hot向量
dataset = dataset.map(lambda x: tf.one_hot(x, 10))
tf.data方式比placeholder表现更好吗?
为了比较两种方式的优劣,我们将模型运行100次,计算运行时间的平均值来比较。在2.7GHz Intel Core i5 Macbook上,placeholder模型运行平均时间为9.05271519s,tf.data模型为6.12285947,性能提升32.4%。
优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
sess.run([optimizer])
为什么op optimizer在运行的fetches中呢?TF如何确定需要更新的参数呢?
optimizer是一个用于最小化loss的op,为了执行这个op,我们需要把它放到sess.run()的fetches列表里。当TF执行optimizer op时,TF会执行与这个op依赖的部分子运算图。在这里,optimizer依赖于loss,而loss又依赖于输入X、Y以及权重参数weights和bias。
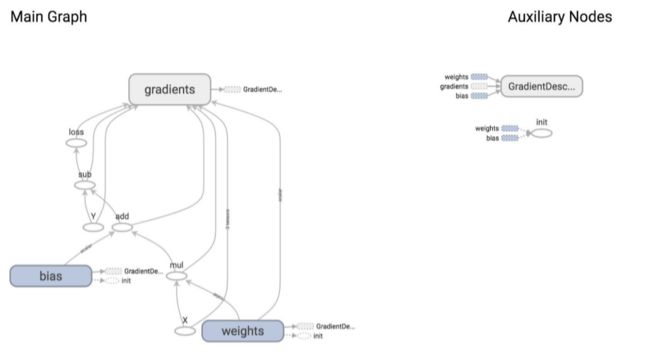
从上图我们可以知道GradientDescentOptimizer结点依赖于3个结点:weights、bias和gradients(梯度,TF可以自动计算)。
GradientDescentOptimizer是指我们的更新为梯度下降。TF可以为我们计算梯度,然后使用梯度值来进行weight和biase的更新,进而来最小化loss。
默认情况下,optimizer可以对loss函数依赖的所有可训练的变量。如果你不想训练某个变量,你可以将其设置为trainable=False。比如对于训练次数global_step这个变量不需要训练:
global_step = tf.Variable(0, trainable=False, dtype=tf.float32)
learning_rate = 0.01 * 0.99 ** tf.cast(global_step, tf.float32)
increment_step = global_step.assign_add(1)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
你也可以将optimizer设定为只对某些变量计算梯度,
# create an optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
# compute the gradients for a list of variables.
grads_and_vars = optimizer.compute_gradients(loss,<list of variables>)
# grads_and_vars is a list of tuples (gradient, variable). Do whatever you
# need to the 'gradient' part, for example, subtract each of them by 1.
subtracted_grads_and_vars = [(gv[0] - 1.0, gv[1]) for gv in grads_and_vars]
# ask the optimizer to apply the subtracted gradients.
optimizer.apply_gradients(subtracted_grads_and_vars)
你也可以阻止特定tensor对loss函数的梯度计算的贡献:
stop_gradient(input, name=None)
对于某些变量在训练过程中需要被冻结的情况非常有用。比如:
- GAN的训练:在对抗样本的生成过程中没有BP
- EM算法:M阶段不应该设计E阶段的输出进行反向传播过程。
optimizer自动计算运算图中的导数,此外,你也可以使TF来计算特定变量的梯度。
tf.gradients(
ys,
xs,
grad_ys=None,
name='gradients',
colocate_gradients_with_ops=False,
gate_gradients=False,
aggregation_method=None,
stop_gradients=None
)
这个方法计算ys相对于每个x的偏导数的和,其中ys、xs分别是一个tensor或一组tensor,grad_ys是一组tensor,内部值为ys计算的梯度结果,长度和ys一致。

使用上述优化方法后的代码为:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import utils
DATA_FILE = 'data/birth_life_2010.txt'
# Step 1: read in the data
data, n_samples = utils.read_birth_life_data(DATA_FILE)
# Step 2: create Dataset and iterator
dataset = tf.data.Dataset.from_tensor_slices((data[:,0], data[:,1]))
# iterator = dataset.make_initializable_iterator()
iterator = dataset.make_initializable_iterator()
X, Y = iterator.get_next()
# Step 3: create weight and bias, initialized to 0
w = tf.get_variable('weights', initializer=tf.constant(0.0))
b = tf.get_variable('bias', initializer=tf.constant(0.0))
# Step 4: build model to predict Y
Y_predicted = X * w + b
# Step 5: use the square error as the loss function
#loss = tf.square(Y - Y_predicted, name='loss')
loss = utils.huber_loss(Y, Y_predicted)
# Step 6: using gradient descent with learning rate of 0.001 to minimize loss
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss)
start = time.time()
with tf.Session() as sess:
# Step 7: initialize the necessary variables, in this case, w and b
sess.run(tf.global_variables_initializer())
writer = tf.summary.FileWriter('./graphs/linear_reg', sess.graph)
# Step 8: train the model for 100 epochs
for i in range(100):
sess.run(iterator.initializer) # initialize the iterator
total_loss = 0
try:
while True:
_, l = sess.run([optimizer, loss])
total_loss += l
except tf.errors.OutOfRangeError:
pass
print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
# close the writer when you're done using it
writer.close()
# Step 9: output the values of w and b
w_out, b_out = sess.run([w, b])
print('w: %f, b: %f' %(w_out, b_out))
print('Took: %f seconds' %(time.time() - start))
2. 逻辑回归
2.1 问题描述
手写数字识别:使用逻辑回归模型来处理MNIST数字分类问题。
MNIST是一个手写数字的数据集。

每张图片为28*28。我们这里将它flatten成784的一维向量,数据标签为0-9表示数字0-9。数据集分为训练集、测试集和验证集,其中训练集为55000张图片,测试集为10000张图片,验证集为5000张图片。
2.2 方法实现
实现过程和线性回归类似。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import numpy as np
import tensorflow as tf
import time
import utils
# Define paramaters for the model
learning_rate = 0.01
batch_size = 128
n_epochs = 30
n_train = 60000
n_test = 10000
# Step 1: 读取数据集
mnist_folder = 'data/mnist'
utils.download_mnist(mnist_folder)
train, val, test = utils.read_mnist(mnist_folder, flatten=True)
# Step 2: 创建dataset以及iterator迭代器
train_data = tf.data.Dataset.from_tensor_slices(train)
train_data = train_data.shuffle(10000) # 数据打乱
train_data = train_data.batch(batch_size)# 划分批量
# 测试集
test_data = tf.data.Dataset.from_tensor_slices(test)
test_data = test_data.batch(batch_size)
# 创建iterator,用于对不同的dataset对象进行迭代
iterator = tf.data.Iterator.from_structure(train_data.output_types, train_data.output_shapes)
img, label = iterator.get_next()
# 迭代器的初始化:分别对训练集和测试集进行遍历,不同的初始化
train_init = iterator.make_initializer(train_data)
test_init = iterator.make_initializer(test_data)
# Step 3: 创建变量w和b
w = tf.get_variable('weights', initializer=tf.random_normal(shape=(784, 10),mean=0,stddev=0.1))
b = tf.get_variable('bias', initializer=tf.zeros((1, 10)))
# Step 4: 模型构建
# 没有计算softmax,将softmax移动到loss的计算过程中
logits = tf.matmul(img, w) + b
# Step 5: loss定义-多分类的交叉熵
loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=label, name='loss')
loss = tf.reduce_mean(loss)
# Step 6: 定义优化器
optimizer = tf.train.AdamOptimizer(0.1).minimize(loss)
# Step 7: 计算准确率
preds = tf.nn.softmax(logits)
correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(label, 1))
accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32))
writer = tf.summary.FileWriter('./graphs/logreg', tf.get_default_graph())
with tf.Session() as sess:
start_time = time.time()
sess.run(tf.global_variables_initializer())
# 模型训练
for i in range(n_epochs):
sess.run(train_init)# 训练集iterator初始化
total_loss = 0
n_batches = 0
try:
while True:
_, l = sess.run([optimizer, loss])
total_loss += l
n_batches += 1
except tf.errors.OutOfRangeError:
pass
print('Average loss epoch {0}: {1}'.format(i, total_loss/n_batches))
print('Total time: {0} seconds'.format(time.time() - start_time))
# 测试集
sess.run(test_init) # 测试集iterator初始化,读取测试集
total_correct_preds = 0
try:
while True:
accuracy_batch = sess.run(accuracy)
total_correct_preds += accuracy_batch
except tf.errors.OutOfRangeError:
pass
print('Accuracy {0}'.format(total_correct_preds/n_test))
writer.close()
模型的运算图如下:
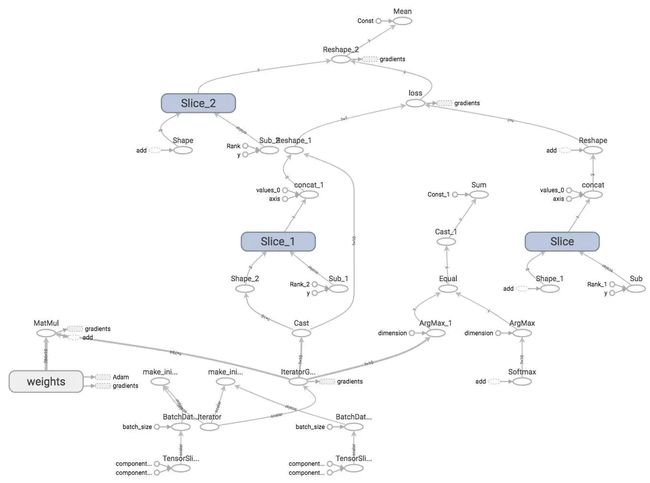
3. References
CS 20: Tensorflow for Deep Learning Research
