持续集成系列(5)------分布式存储ceph部署
持续集成系列------分布式存储ceph部署
文章目录
- 持续集成系列------分布式存储ceph部署
- 目标
- ceph简介
- 系统环境
- 升级内核
- 安装依赖
- 初始化环境
- 集群创建(初始节点为3个)
- 删除集群(后悔药)
- 新增node
- 开启dashboard模块
- 验证
- 移除故障节点
- 重新加入故障节点
- 硬盘故障后更换osd
- 备份ceph-cluster文件夹
- 参考文章
目标
gitlab+jenkins+docker+harbor+k8s初步实现持续集成
ceph简介
Ceph是一个可靠地、自动重均衡、自动恢复的分布式存储系统,根据场景划分可以将Ceph分为三大块,分别是对象存储、块设备存储和文件系统服务。在虚拟化领域里,比较常用到的是Ceph的块设备存储,比如在OpenStack项目里,Ceph的块设备存储可以对接OpenStack的cinder后端存储、Glance的镜像存储和虚拟机的数据存储,比较直观的是Ceph集群可以提供一个raw格式的块存储来作为虚拟机实例的硬盘。
Ceph相比其它存储的优势点在于它不单单是存储,同时还充分利用了存储节点上的计算能力,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,同时由于Ceph的良好设计,采用了CRUSH算法、HASH环等方法,使得它不存在传统的单点故障的问题,且随着规模的扩大性能并不会受到影响。
由于k8s的容器是无状态的,发生pod飘移的时候,数据会丢失,有些应用如mysql等就需要一个分布式存储(ceph)用于存储数据
系统环境
| 主机名 | ip | role |
|---|---|---|
| ceph01 | 10.79.167.29 | mon、mgr、osd |
| ceph02 | 10.79.167.30 | mon、mgr、osd |
| ceph03 | 10.79.167.31 | mon、mgr、osd |
| ceph04 | 10.79.167.32 | osd |
升级内核
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel install kernel-ml -y
sed -i s/saved/0/g /etc/default/grub
grub2-set-default "$(cat /boot/grub2/grub.cfg |grep menuentry|grep 'menuentry '|head -n 1|awk -F "'" '{print $2}')"
#查看默认启动版本
grub2-editenv list
grub2-mkconfig -o /boot/grub2/grub.cfg && reboot
安装依赖
yum install -y ntp ntpdate ntp-doc
sed -i "s/0\.centos\.pool\.ntp\.org/ntp6.aliyun.com/g" /etc/ntp.conf
systemctl start ntpd
systemctl enable ntpd
systemctl disable firewalld
systemctl stop firewalld
systemctl disable iptables
systemctl stop iptables
cat > /etc/yum.repos.d/ceph.repo<初始化环境
# 所有节点添加host
cat >>/etc/hosts <集群创建(初始节点为3个)
cd ~ && mkdir -p ceph-cluster
cd ceph-cluster
# 初始化集群
ceph-deploy new ceph0{1..3}
# 配置优化
cat >>ceph.conf<删除集群(后悔药)
ceph-deploy purge ceph0{1..3}
ceph-deploy purgedata ceph0{1..3}
ceph-deploy forgetkeys
新增node
1、升级内核
2、安装依赖
3、初始化环境
#在deploy节点执行
for disk in sd{b..i};do
ceph-deploy --overwrite-conf osd create --data /dev/${disk} ceph01
done
#同步配置
ceph-deploy --overwrite-conf admin ceph0{1..4}
开启dashboard模块
cat >> /root/ceph-cluster/ceph.conf <验证
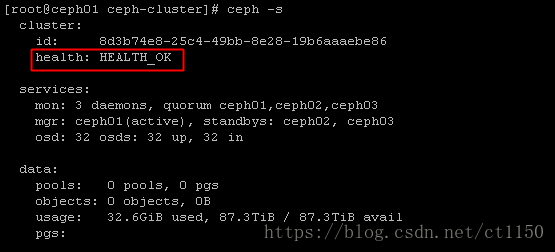
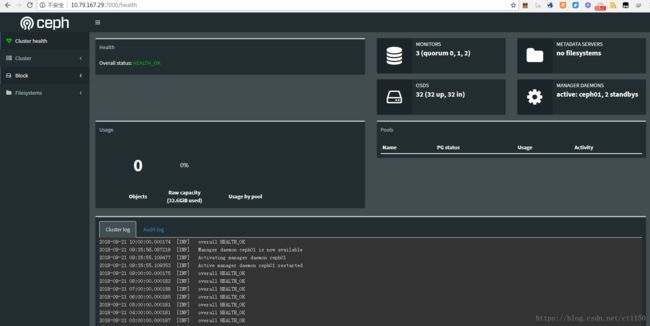
移除故障节点
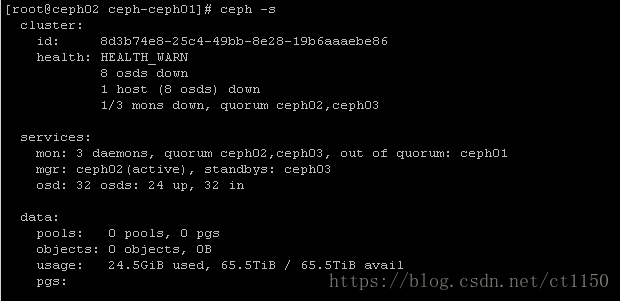
当出现节点异常,需要把故障节点中的ceph角色移除(osd、mon),这里以ceph01故障为例
查看ceph集群状态
ceph -s
# 查看down掉的osd编号
ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 87.31152 root default
-3 21.82788 host ceph01
0 hdd 2.72849 osd.0 down 0 1.00000
1 hdd 2.72849 osd.1 down 0 1.00000
2 hdd 2.72849 osd.2 down 0 1.00000
3 hdd 2.72849 osd.3 down 0 1.00000
4 hdd 2.72849 osd.4 down 0 1.00000
5 hdd 2.72849 osd.5 down 0 1.00000
6 hdd 2.72849 osd.6 down 0 1.00000
7 hdd 2.72849 osd.7 down 0 1.00000
# 调整异常osd的权重为0并移除osd
ceph osd crush reweight osd.{0..7} 0
for i in {0..7};do ceph osd crush reweight osd.${i} 0;done
ceph osd out {0..7}
ceph osd rm {0..7}
# 删除映射以及认证
for i in {0..7};do ceph osd crush rm osd.${i};done
for i in {0..7};do ceph auth del osd.${i};done
# 删除mon节点
ceph mon rm ceph01
# 删除主机
ceph osd crush rm ceph01
参考文档—节点损坏,数据盘正常情况下的数据恢复
重新加入故障节点
1、同新增node章节
2、从其它节点拷贝kering与配置到ceph-cluster文件夹
[root@ceph01 ceph-cluster]# ls
ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.client.admin.keyring ceph-deploy-ceph.log
ceph.bootstrap-mgr.keyring ceph.bootstrap-rgw.keyring ceph.conf ceph.mon.keyring
3、初始化mon并收集key,加入mds&mgr
ceph-deploy --overwrite-conf mon create-initial
ceph-deploy mgr create ceph01
ceph-deploy mds create ceph01
4、加入osd
#由于ceph01为系统盘损坏,数据盘正常,导致旧的vg存在,需要先删除
lvscan
vgscan
pvscan
lvremove
vgremove
pvremove
#清空所有ceph相关vg,lv,pv
for i in `lvscan |grep ceph|awk -F "[ |']+" '{print $3}'`; do lvremove -y $i; done
for i in `vgscan |grep ceph|awk -F '[ |"]+' '{print $5}'`;do vgremove $i;done
pvremove /dev/sd{b..i}
for disk in sd{b..i};do
ceph-deploy --overwrite-conf osd create --data /dev/${disk} ceph01
done
硬盘故障后更换osd
由于luminous版本更新了替换osd的命令,按旧命令删osd会导致无法新增osd成功…
新版命令更简洁了:
# 把旧osd标记为destroy
ceph osd destroy {id} --yes-i-really-mean-it
# 格式化新硬盘
ceph-volume lvm zap {disk-path} --destroy
# 相同id创建新osd
ceph-volume lvm create --osd-id {id} --data {disk-path}
备份ceph-cluster文件夹
为避免ceph-deploy所在主机故障导致ceph-deploy无法使用,提前备份配置到其它主机
# @ceph01
scp -r /root/ceph-cluster ceph02:/root/
scp -r /root/ceph-cluster ceph03:/root/
参考文章
ceph集群维护常用命令
三种方式连接ceph