分布式数据库一致性解决初步
一、关于分布式系统事务一致性问题
Java 中有三种可以的事务模型,分别称作本地事务模型(Local Transaction Model),编程式事务模型(Programmatic Transaction Model),和声明式事务模型(Declarative Transaction Model)。事务要求包含原子性(Atomicity),一致性(Consistency),独立性(Isolation),和持久性(Durability)。
《大型网站系统与Java中间件实践》一书中分享了一些解决分步式系统一致性问题的方案构思与实践,如在第六章中谈到的消息中间件。下表展现了解决一致性方案与传统方式的对比。

传统方式是,我做完了,发你消息。解决一致性的方案的意思就是,我先发你消息,我做完了再跟你确认我做完了。这是改进后的有事务的消息中间件。
因为在非XA 环境中,消息队列的插入过程独立于数据库更新操作,ACID 准则中的原子性和独立性不能得到保证,从而整体上数据完整性受到损害。使用X/Open 的XA 接口,我们便能够做到协调多个资源,保证维持ACID 准则。
在《淘宝技术这十年》这本书里也提到这么一段描写“用户在银行的网关付钱后,银行需要通知到支付宝,但银行的系统不一定能发出通知;如果通知发出了,不一定能通知到;如果通知到了,不一定不重复通知一遍。这个状况在支付宝持续了很长时间,非常痛苦。支付宝从淘宝剥离出来的时候,淘宝和支付宝之间的通信也面临同样的问题,那是2005年的事情,支付宝的架构师鲁肃提出用MQ(Message Queue)的方式来解决这个问题,我负责淘宝这边读取消息的模块。但我们发现消息数量上来之后,常常造成拥堵,消息的顺序也会出错,在系统挂掉的时候,消息也会丢掉,这样非常不保险。然后鲁肃提出做一个系统框架上的解决方案,把要发出的通知存放到数据库中,如果实时发送失败,再用一个时间程序来周期性地发送这些通知,系统记录下消息的中间状态和时间戳,这样保证消息一定能发出,也一定能通知到,且通知带有时间顺序,这些通知甚至可以实现事务性的操作。”
一致性更是可以分为强一致性和弱一致性两种,弱一致性可以允许某一时间间隔内的偶尔不一致,强一致性的要求要高很多。在实际中,弱一致性往往就能达到业务要求,甚至某些银行系统都只要求弱一致性即可,允许不一致性的窗口存在,只要不造成损失即可。
对于每一种分布式系统,其组织方式各不相同,实现形式也各有千秋,业务要求更是千变万化,因此要因地制宜的实施一致性方案。表6-5提出的解决办法是要求处理方在完成业务操作后主动发送给消息中间件这一结果,而后消息中间件确认后再做处理,这样是可以保证事务性。但对于表6-5提出的解决办法,在入HBase和Solr的流程中并不能适用。因为为了保证数据写入Solr的性能,入Solr使用的是Concurrent....方式,然而此种方式并不会返回是否入Solr成功,因此这种异步特性不是表6-5中方案所能解决的。
二、针对HBase和Solr分布式系统事务一致性解决方案
在此,我们对于HBase加Solr这种分布式系统,经过种种构思-推翻-再构思-再推翻,终于成功,特设计了如下事务一致性解决方案。
1、写入数据到HBase和Solr
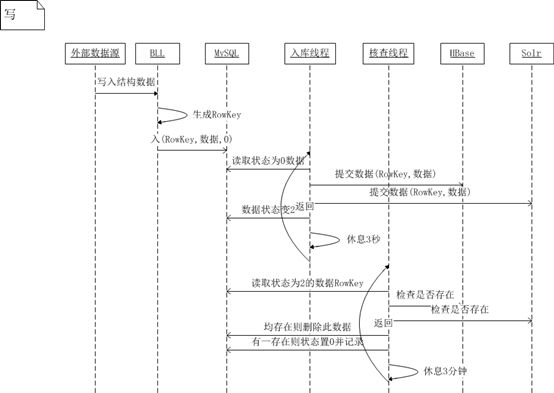
图1 HBase加Solr分布式系统事务一致性解决方案(写入数据)
从图1时序图中可以看出,其思想与表6-5方案还是一致的,但实现手法则完全不同。它的本质即是:需要确认数据处理成功后,方可证实数据同步。关键在于,如何确认数据处理成功,靠HBase返回?靠Solr返回?不行。那只有做个缓存,先把没确认的存着,等后期有时间了挨个确认。这里的MySQL就起到了方案所述的缓存的作用。我们先把数据写入到MySQL缓存起来,写入时数据状态为0,说明还没有提交HBase和Solr,每间隔3秒我们使用“入库线程”取状态为0的数据,提交到HBase和Solr中,并将数据状态更新为2,以此说明此数据已经入了库。如果没有“核查线程”做数据一致性检查,则数据一致性无法保证。有可能存在这样一种情况:HBase里数据写入成功了,Solr里出于某种原因没有写入成功(Solr异常了或网络不通了等等)。如果此不一致性很久没有被发现,那么就会在HBase中出现一些根本无法取得的飘浮数据。我们的“核查线程”可以保证HBase中和Solr里的数据是一致的。
2、从HBase和Solr中删除数据
现在我们已经做到了写入数据操作的事务一致性,同理的还有,删除数据操作的事务一致性,更新数据操作的事务一致性,都可以以这种思想实现。
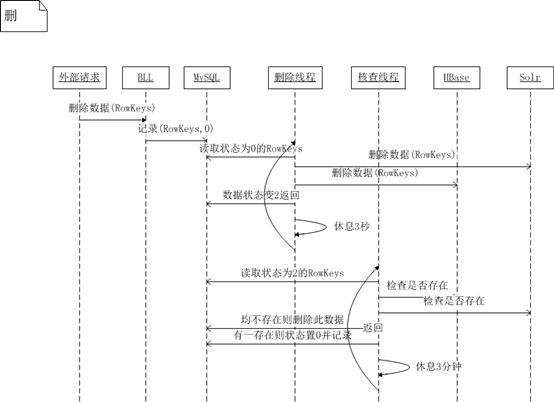
图2 HBase加Solr分布式系统事务一致性解决方案(删除数据)
从图2中可以看出,删除数据先从Solr中删除,再从HBase中删除,同样的,如果发生某种不可预见的异常,HBase中也会出现一些根本无法取得的飘浮数据,这种情况很少见,然而一旦发生,我们的“核查线程”可以保证HBase中和Solr里的数据是一致的。
3、更新数据到HBase和Solr
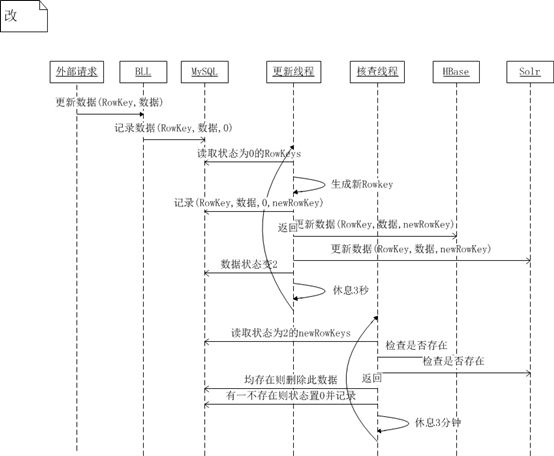
图3 HBase加Solr分布式系统事务一致性解决方案(更新数据)
更新数据的一致性解决方案要稍微复杂一些,因为对HBase和Solr中数据核查某一数据是否已经正确更新是很难做到的。你可以将HBase中的数据一个个地取出来与更新数据进行比较,查看是否已经正确更新;但你没有办法将更新数据所有的字段去Solr中查,是否更新到Solr。因此我们设计的方案是:先对要更新的RowKey-数据生成一个新的newRowKey,再将HBase和Solr中的原始数据进行删除,然后将更新后的数据添加入HBase和Solr中,这样就是完成了一次更新数据的操作,将更新分成了删除与添加两步进行操作,核查此数据是否已经正确更新也因此有迹可寻,此时只需要搜索HBase和Solr中有newRowKey即可证明数据已经更新成功。
三、总结
在这里,我们引用一下《支付宝数据平台》中的海狗系统的架构设计。海狗系统(ARSC)——准实时搜索查询,它提供千亿级别数据实时查询和全文检索、支持每天10亿+级别的数据更新。它的实时性可以保证实时搜索延迟3s、查询和插入TPS > 1.5WTPS。数据容量线性扩展,Schema扩展基于HBase列式无限扩张,基于ZK动态感知节点状态自动容灾。下图即简单表明了其流程。
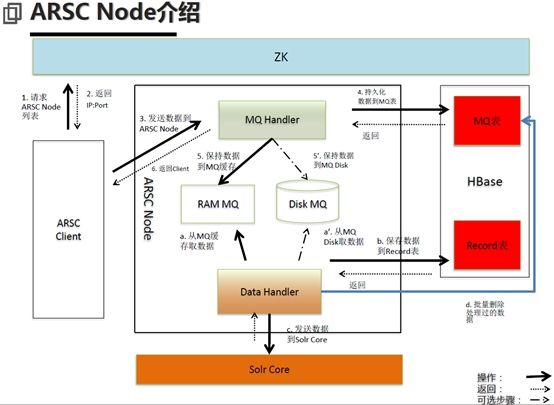
粗看不起眼,琢磨一下便知其是考虑到了HBase和Solr的数据一致性的。在HBase中的MQ表就是起到上面我们的设计方案中的MySQL的作用。在d步骤中,才批量删除处理过的数据,MQ表是留凭证用的。HBase在高性能处理方面还是要远远优于MySQL,如果可以,我们设计方案中的MySQL也可以用HBase取代。
做个总结:无论是我们设计方案,还是其他类似的分布式系统事务性解决方案,其的本质思想是一样的,即是:做个缓存,先把没确认的存着,等后期有时间了挨个确认。
“既然计算是异步的,那么反馈也应该是异步的,你完全可以让SendMail将发送结果写入数据库,并生成报表,然后让应用程序定期对报告中发送失败的邮件执行再次发送。这里需要假设失败的情况并不是很多。”在《构建高性能web站点》第17章分布式计算-异布计算中对此类问题的解决方法,也是构成我们解决HBase和Solr分布式系统事务一致性问题的重要指导,感谢作者郭欣。当然也感谢《大型网站系统与Java中间件实践》的作者曾宪杰、《构建高性能web站点》的作者郭欣。更感谢分享海狗系统设计的蒋杰(花名:平原君),以及众多乐于分享技术的人们。
看这些书,觉得系统架构方面的技术真的是非常庞大,佩服阿里的那群将数据从小做到大的问题解决者。千里之行,始于足下。