神经网络学习笔记(六) 广义回归神经网络
广义回归神经网络 GRNN
(General Regression Neural Network)
广义回归神经网络是基于径向基函数神经网络的一种改进。
结构分析:
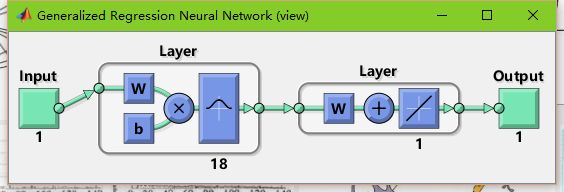
可以看出,这个结构与之前我们所讲过的径向基神经网络非常相似,区别就在于多了一层加和层,而去掉了隐含层与输出层的权值连接。
1.输入层为向量,维度为m,样本个数为n,线性函数为传输函数。
2.隐藏层与输入层全连接,层内无连接,隐藏层神经元个数与样本个数相等,也就是n,传输函数为径向基函数。
3.加和层中有两个节点,第一个节点为每个隐含层节点的输出和,第二个节点为预期的结果与每个隐含层节点的加权和。
4.输出层输出是第二个节点除以第一个节点。
理论基础
广义回归神经网络对x的回归定义不同于径向基函数的对高斯权值的最小二乘法叠加,他是利用密度函数来预测输出。
假定x,y为两个随机变量,联合概率密度为 f(x,y)。
我们就得到以下公式: (x0)=F(y*f(x0,y))/F(f(x0,y)). F代表积分。
(x0)就是y在x0条件下在预测输出。 x0是的观测值。
现在未知数就是f(x,y)。
怎样估计已知数值而未知分布的密度函数呢?这里我们使用Parzen非参数估计方法。
窗口函数选择为高斯窗口。
得到下式 y(x0)=F(y*exp(-d))/F(exp(-d))。
d代表的就是离中心的距离,exp(-d)就是径向基函数隐含层的输出。
程序讲解
首先我们还是和径向基函数神经网络一样,设定一组数据。
p=-9:1:8;
x=-9:.2:8;
t=[129,-32,-118,-138,-125,-97,-55,-23,-4,2,1,-31,-72,-121,-142,-174,-155,-77];
p,t分别代表输入输出,x为测试样本,与径向基函数神经网络不同的是,这些数据需要在创建时一起输入,而不需要类似径向基那样的权值训练,GRNN并不存在权值,所以网络不能保存,用的时候直接拟合即可。
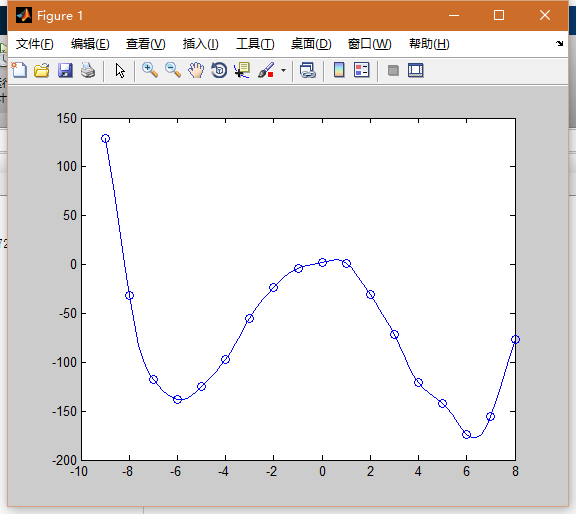
而正因为GRNN没有权值这一说,所以不用训练的优势就体现在他的速度真的很快。而且曲线拟合的非常自然。样本精准度不如径向基精准,但在实际测试中表现甚至已经超越了bp。
接下来就是隐含层的处理,不同于RBF的是,隐含层没有了恒为1的向量输出添加。
spread=1;
chdis=dist(x',p);
chgdis=exp(-chdis.^2/spread);
chgdis=chgdis';最后是加和层与输出层,这里我们把式子写在一起。
y=t*chgdis./(sum(chgdis));看一下输出效果

对比一下径向基函数所训练出来的权值神经网络
结束语
虽然GRNN看起来没有径向基精准,但实际在分类和拟合上,特别是数据精准度比较差的时候有着很大的优势。