《庆余年》值得一看吗?Python告诉你谁在关注 | CSDN原力计划

扫码参与CSDN“原力计划”
作者 | A字头
来源 | 数据札记倌
庆余年电视剧终于在前两天上了,这两天赶紧爬取数据看一下它的表现。
庆余年
《庆余年》是作家猫腻的小说。这部从2007年就开更的作品拥有固定的书迷群体,也在文学IP价值榜上有名。

期待已久的影视版的《庆余年》终于播出了,一直很担心它会走一遍《盗墓笔记》的老路。
在《庆余年》电视剧上线后,就第一时间去看了,真香。

庆余年微博传播分析
《庆余年》在微博上一直霸占热搜榜,去微博看一下大家都在讨论啥:
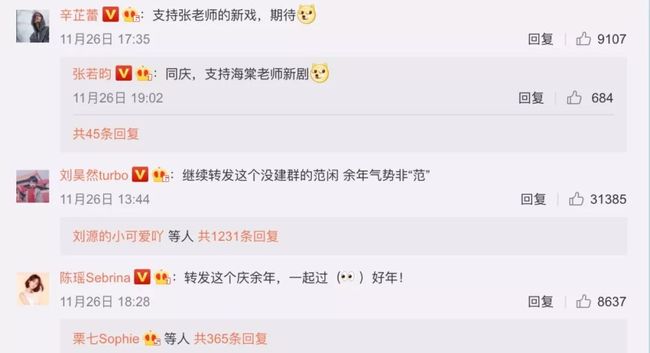
一条条看显然不符合数据分析师身份。
于是爬取了微博超话页面,然后找到相关人员,分别去爬取相关人员的微博评论,看看大家都在讨论啥。
import argparse
parser = argparse.ArgumentParser(description="weibo comments spider")
parser.add_argument('-u', dest='username', help='weibo username', default='') #输入你的用户名
parser.add_argument('-p', dest='password', help='weibo password', default='') #输入你的微博密码
parser.add_argument('-m', dest='max_page', help='max number of comment pages to crawl(number larger than 0 or all)' , default=) #设定你需要爬取的评论页数
parser.add_argument('-l', dest='link', help='weibo comment link', default='') #输入你需要爬取的微博链接
parser.add_argument('-t', dest='url_type', help='weibo comment link type(pc or phone)', default='pc')
args = parser.parse_args()
wb = weibo()
username = args.username
password = args.password
try:
max_page = int(float(args.max_page))
except:
pass
url = args.link
url_type = args.url_type
if not username or not password or not max_page or not url or not url_type:
raise ValueError('argument error')
wb.login(username, password)
wb.getComments(url, url_type, max_page)
相关函数已经封装好,后台回复“微博”下载直接使用。
如何利用Python生成词云图
爬取到微博评论后,老规矩,词云展示一下,不同主角的评论内容差别还是挺大的。
张若昀:

李沁:

肖战:
emmm....算了吧

从目前大家的评论来看,情绪比较正向,评价较高,相信《庆余年》会越来越火的。
这部剧在微博热度这么高,都是谁在传播呢?
于是我进一步点击用户头像获取转发用户的公开信息。
看了一下几位主演的相关微博,都是几十万的评论和转发,尤其是肖战有百万级的转发,尝试爬了一下肖战的微博,执行了6个小时的结果,大家随意感受一下执行过程:
最终还是败给了各位小飞侠,之后有结果再同步给大家。

于是我只能挑软柿子捏,换成官微的微博。
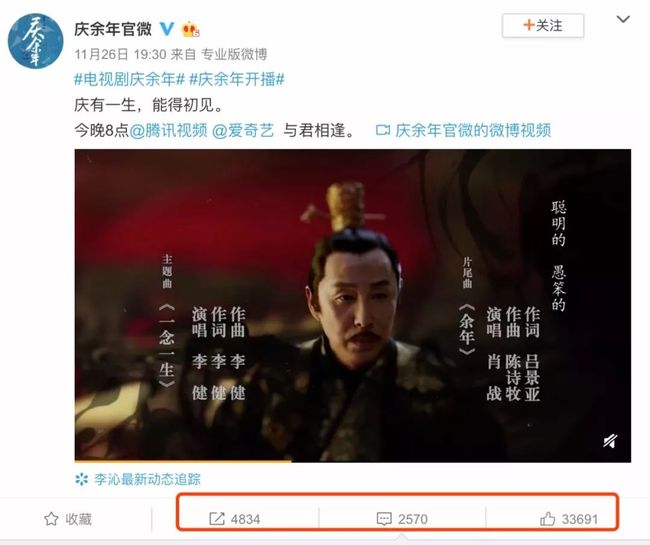
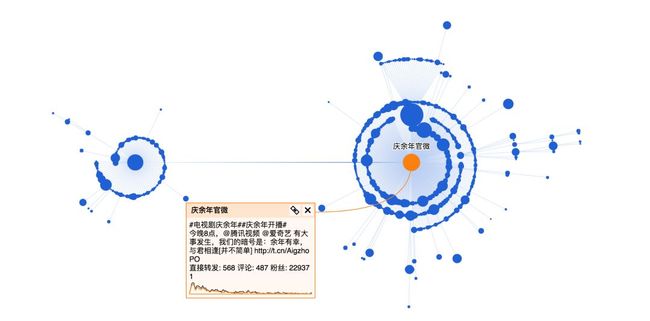
这条微博发布时间是26号,经过一段时间已经有比较好的传播,其中有几个关键节点进一步引爆话题。
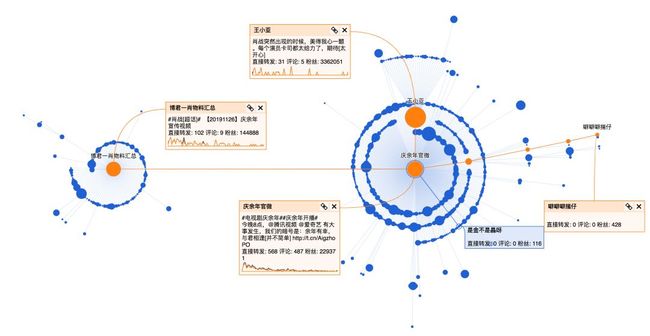
经过几个关键节点后,进一步获得传播,这几个关键节点分别是:
肖战的超话:https://weibo.com/1081273845/Ii1ztr1BH
王小亚的微博:https://weibo.com/6475144268/Ii1rDEN6q
继续看一下转发该微博的用户分析:
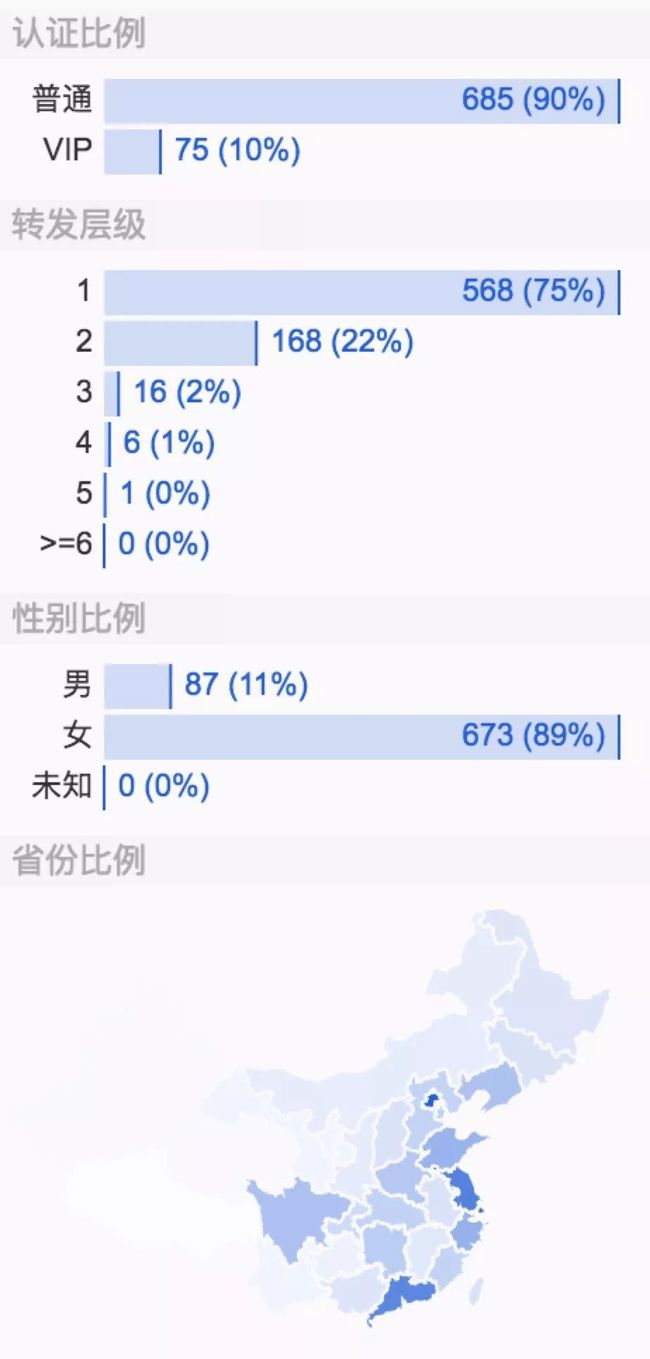
整体看下来,庆余年官微的这条微博90%都是普通用户的转发,这部剧转发层级达到5层,传播范围广,在微博上的讨论女性居多(占比89%),大部分集中在一二线城市。
原著人物关系图谱
如果只看微博,不分析原著,那就不是一个合格的书粉。

于是我去下载了原著画一下人物关系图谱。
先给大家看一下原著的人物关系图谱:

emmm.....确实挺丑的,大家可以去Gephi上调整。
首先我需要从原著里洗出人物名,尝试用jieba分词库来清洗:
import jieba
test= 'temp.txt' #设置要分析的文本路径
text = open(test, 'r', 'utf-8')
seg_list = jieba.cut(text, cut_all=True, HMM=False)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
发现并不能很好的切分出所有人名,最简单的方法是直接准备好人物名称和他们的别名,这样就能准确定位到人物关系。

存储好人物表,以及他们对应的别名(建立成字典)
def synonymous_names(synonymous_dict_path):
with codecs.open(synonymous_dict_path, 'r', 'utf-8') as f:
lines = f.read().split('\n')
for l in lines:
synonymous_dict[l.split(' ')[0]] = l.split(' ')[1]
return synonymous_dict
接下来直接清理文本数据:
def clean_text(text):
new_text = []
text_comment = []
with open(text, encoding='gb18030') as f:
para = f.read().split('\r\n')
para = para[0].split('\u3000')
for i in range(len(para)):
if para[i] != '':
new_text.append(para[i])
for i in range(len(new_text)):
new_text[i] = new_text[i].replace('\n', '')
new_text[i] = new_text[i].replace(' ', '')
text_comment.append(new_text[i])
return text_comment
我们需要进一步统计人物出现次数,以及不同人物间的共现次数:
text_node = []
for name, times in person_counter.items():
text_node.append([])
text_node[-1].append(name)
text_node[-1].append(name)
text_node[-1].append(str(times))
node_data = DataFrame(text_node, columns=['Id', 'Label', 'Weight'])
node_data.to_csv('node.csv', encoding='gbk')
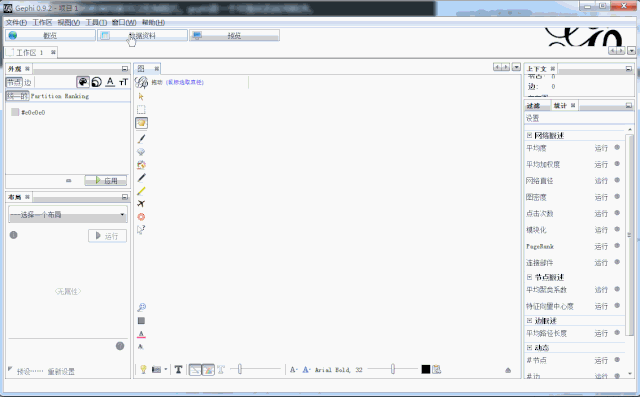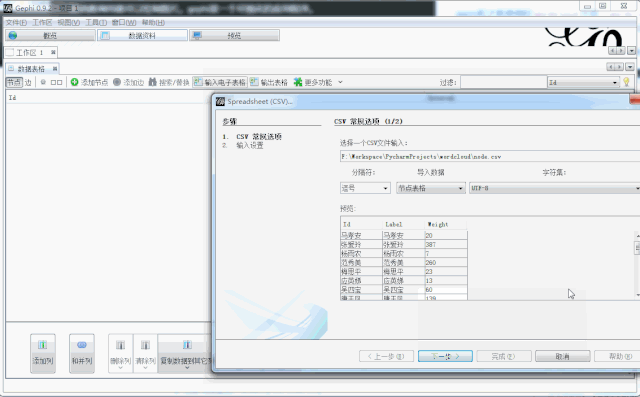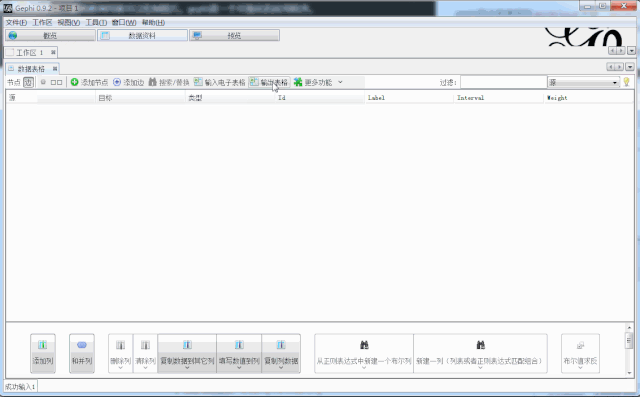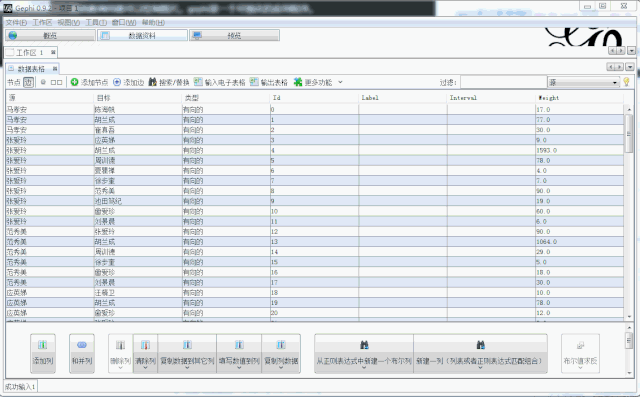
结果样例如下:
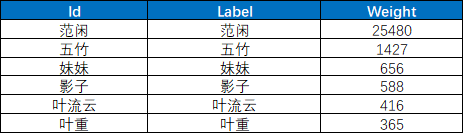
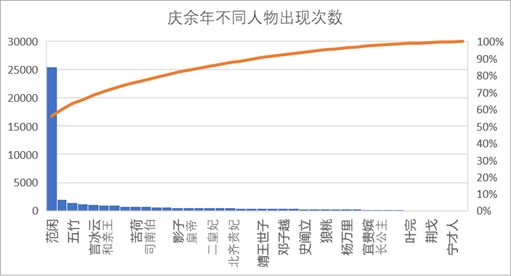
不愧是主角,范闲出现的次数超过了其他人物出现次数的总和,基本每个人都与主角直接或间接地产生影响。
同理可以得到不同人物的边,具体代码参考源文件。
接下来需要做的就是利用Gephi绘制人物关系图谱:
运行结果:
参考文献:Ren, Donghao, Xin Zhang, Zhenhuang Wang, Jing Li, and Xiaoru Yuan. "WeiboEvents: A Crowd Sourcing Weibo Visual Analytic System." In Pacific Visualization Symposium (PacificVis) Notes, 2014 IEEE, pp. 330-334. IEEE, 2014.
数据和源码下载
链接:https://pan.baidu.com/s/1gr8h5BX4X6zm3E3b4bYrRw
密码:oxjs
点击阅读原文,查看作者更多文章!
技术的道路一个人走着极为艰难?
一身的本领得不施展?
优质的文章得不到曝光?
别担心,
即刻起,CSDN 将为你带来创新创造创变展现的大舞台,
扫描下方二维码,欢迎加入 CSDN 「原力计划」!

◆
精彩推荐
◆
开幕倒计时3天!2019 中国大数据技术大会(BDTC)即将震撼来袭!豪华主席阵容及百位技术专家齐聚,十余场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读。

推荐阅读
一张图生成定制版二次元人脸头像,还能“模仿”你的表情
激辩:机器究竟能否理解常识?
阿里正式开源通用算法平台Alink,“双11”将天猫推荐点击率提升4%
最新单步目标检测框架,引入双向网络,精度和速度均达到不错效果
从拨号到 5G :互联网登录完全指南
测试小白必读!从0基础做到「大厂测试」,要掌握什么技能?
科技公司最爱的50款开源工具,你都用过吗?
OceanBase 的前世今生
想做好区块链数据分析?先来看看如何解决“去匿名化”这个大难题
把700元的单片机改造成以太坊节点, 9步get起新技能

你点的每个“在看”,我都认真当成了AI