全球股市巨震,如何用深度学习预测股价?
这两天全球股市都可谓血雨腥风!
这个时候,营长照例会点燃一根烟,看着满屏高高低低的K线,心中又出现了那个历史之问:这时候是该卖出手中持仓?还是用剩余资金抄底?
作为关注 AI 多年的股市老韭菜,营长深知要想完全预测股市是不可能的,但并非无法预测。如果方法得当,就能提高成功的几率。可是什么样的方法才得当呢?心中默念使用数据科学投资的三个关键原则:
- 过去的表现并不是我们所关心的,我们关心未来的表现。
- 过去的数据是我们必须学习的,我们没有未来的数据。
- 不是所有过去发生的都会在未来再次发生。
还是不得操作要领,再次在卷帙浩繁的技术文章中寻找真经,发现有一篇应用深度学习来预测股市的文章还不错,在这里分享给大家。
以下内容由AI科技大本营(微信ID:rgznai100)编译
在过去的几个月里,我对“深度学习”非常感兴趣,尤其是在语言和文本应用方面。我大部分的工作时间都花费在了金融技术上,主要研究算法交易和替代性数据服务。你可以看一下我工作的进程。
写这篇文章的目的是想表达头脑中的想法。尽管我已经成为一个“深度学习”的爱好者,但是深度学习的成果太多太杂,我没有太多机会做出相关的整理。在我看来,如果文章表达的内容思路清晰的话,即便是行外人也能够理解。希望我成功做到了,也希望我的表达让阅读的人感到很愉快。
▌为什么 NLP 与股票预测息息相关
在许多 NLP 问题中,我们最终会得到一个序列并将它编码成一个单个固定大小的形式,然后将该形式编码到另一个序列中。例如,我们可能会标记出文本中的实体,而后将其从英语翻译成法语或将音频转换为文本。NLP 领域涉及方方面面的大量的工作,很多成果的性能正在达到世界领先水平。
在我看来,NLP 和金融分析最大的区别是:语言虽然有一定的结构保证,但是结构的规则是模糊的。另一方面,市场并没有承诺会提供一个可学习的结构,这样的结构之所以存在是建立在此项目会被证明或反驳的假设之上(而不是可能证明或反驳,如果我能找到该结构)。
假设结构是存在的,以我们编码段落语义的方式来概括市场当前状态的想法对我来说似乎是合理的。如果这还没有意义,请继续阅读,总会有意义的。
你应该知道它所持有的公司的一个单词(Firth,J. R. 1957:11)。
有大量关于单词嵌入的文献。Richard Socher 的演讲是一个很好的开始。
总之,我们可以将语言中的所有单词做成一个几何形状,这个几何形状可捕捉单词的意义和它们之间的关系。你可能已见过“国王+女人=女王”这个例子或者其他类似的例子。
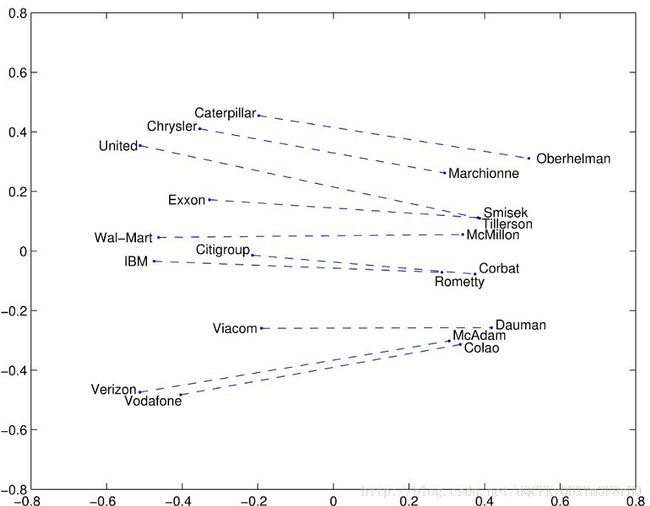
图像来自 Glove 项目
单词之间的几何图形。通过观察上述单词,我们可以看出公司和其 CEO 之间内在的几何关系。
嵌入是很酷的,因为它们允许我们以一种精简的方式来表达信息。旧的表示单词的方式是在知道单词数量的情况下设置出一个向量(一个大的数字列表),随后在我们当前查找的单词位置将其设置为1。这不是一种有效的方法,也没捕捉到任何意义。使用嵌入法,我们可以在固定数量的维度上表示所有的单词(300似乎很多,50比较好),然后用更高维的几何去理解它们。
下面图片中有一个示例。整个互联网都在或多或少的训练嵌入。经过几天的集中计算,每个词都被嵌入在了相对高维空间里。这个“空间”是有几何形状的,类似距离这样的概念,所以我们可以找到那些靠的比较近的单词。该方法的作者或是发明者曾经举过这样一个例子。以下是与青蛙(Frog)最接近的单词。

来自Glove项目
根据 Glove 算法(单词嵌入的一种),以上单词是离“frog”最近的几个单词。请注意它是如何知道这些你以前从未听过的单词的,也请注意它是如何捕捉到这些单词与 Frog 的相似性的。
但是我们能嵌入的不仅仅是单词,比如,我们也可以做股票市场嵌入。
▌Market2Vec
我听说过的第一个词嵌入算法是 word2vec。尽管我需要运用不同的算法,但我想得到同样的市场效应。我输入的数据是一个 csv 文件,第一列是日期,并且有4*1000列相当于1000个股票的高低开市收盘价。我输入的向量有4000个维度,这太大了。所以我要做的第一件事是把它放在一个更低维的空间,比如说300维,因为我喜欢这部电影。

当你奋力把4000维缩小至300维时,你的表情。
将原本4000维才能放下的东西缩小至300维,乍听起来很难,但实际上很容易。我们只需让矩阵相乘就可以了。每个矩阵都相当于一个大的 excel 电子表格,每个单元格里都有数字且不存在格式问题。想象一个具有4000列300行的 excel 表,当我们将其与向量相互碰撞的时候,一个新向量由此诞生,而它的大小只有300。我希望在大学的课堂里也是这样解释的。
我们的想法诞生于在矩阵中随机设置数字的那一刻,并且深度学习其中一部分本就是为了更新这些数字。因此,我们便更改了电子表格。最终该电子表格(从现在起,我将统一用“矩阵”来表示)会填充上数字,这些数字将原始的4000维向量转换成了300维,非常简明。
现在,我们变得越来越感兴趣了,在此引用了所谓的激活函数。我们将采用一个函数,并将其应用到向量中的每个数字中,使它们都处于0和1之间(也可以是0和无穷大,视情况而定)。为什么呢?一方面这会使我们的向量更加特别;另一方面这也能让我们的学习过程能够理解更为复杂的事情。怎么样?
那又怎么样呢?我希望找到的是将市场价格(向量)新嵌入到相对较小的空间中以捕捉当下任务中的所有关键信息、同时又不在其他事宜上浪费时间的方法。所以我希望它们能捕捉到其它股票之间的相关性,例如某个领域的股票正在下跌或某个市场很火热等情况。我不清楚它会发现什么特征,但是我认为它们会很有用。
▌现在谈论什么
暂且把市场向量放到一边,我们先来谈论下语言模型。Andrej Karpathy 曾写过一篇很长的文章 The Unreasonable effectiveness of Recurrent Neural Networks。
如果我以最自由的方式做总结,这篇帖子可以归结为:
- 如果我们看一看莎士比亚的作品,并逐字探讨它们,我们可用“深度学习”来学习一种语言模型。
- 语言模型就像一个魔法盒,你放进去几个前面的字符,它就能告诉你下一个是什么。
- 如果我们取语言模型预测出的字符,并将其反馈回去,我们就可以一直进行下去。
然后,有一个笑点是,最终生成了一堆看起来像莎士比亚作品的文本。接着他用 Linux 源代码又试验了一次,再接下来他又用一本代数几何的教科书试了一次。
因此我马上回到了那个魔法盒的机制,请允许我提醒你一下,我们想要根据过去来预测未来的市场,就像上述 Andrej Karpathy 根据前一个词预测下一个词一样。在 Karpathy 使用字符的地方,我们将使用市场向量,并将市场向量放进魔法盒中。我们还没决定好让它预测什么,但是没关系,我们还不打算将它的输出反馈给它。
▌不断深入
我想说的是,这是我们迈入深度学习的深层之处的开端。截至目前,我们只是在学习它的浅层部分,上述电子表格浓缩了整个市场。现在我们要加入更多的层,并将它们堆叠起来去做些“深度”的东西。这就是深度学习中所谓的深度。
所以 Karpathy 给我展示了一些从 Linux 源代码上输出的例子,以下是他的黑盒子中的内容。
static void action_new_function(struct s_stat_info *wb)
{
unsigned long flags;
int lel_idx_bit = e->edd, *sys & ~((unsigned long) *FIRST_COMPAT);
buf[0] = 0xFFFFFFFF & (bit << 4);
min(inc, slist->bytes);
printk(KERN_WARNING "Memory allocated %02x/%02x, "
"original MLL instead\n"),
min(min(multi_run - s->len, max) * num_data_in),
frame_pos, sz + first_seg);
div_u64_w(val, inb_p);
spin_unlock(&disk->queue_lock);
mutex_unlock(&s->sock->mutex);
mutex_unlock(&func->mutex);
return disassemble(info->pending_bh);
}请注意它自己知道如何打开和关闭括号,并遵从缩近规则。函数内容部分缩进得当,多行 printk 语句中有一个内部缩进。也就是说,这个魔法盒是理解远程相依规则的。在打印语句中缩进时,它知道处于打印语句中,也能记住它处于某个函数中(至少是另一个缩进后的范围中)。这要疯了。很容易忽略的是,一个具有捕捉和记忆长期依赖关系能力的算法是有用的,因为…我们想发现市场的长期依赖性。
▌黑色魔法盒的内部
黑色魔法盒里有什么?是循环神经网络(RNN)的一种类型,叫 LSTM。RNN 是一种操作序列(例如字符序列)的深度学习算法。在每一步上,它都会接受来自下一字符的向量(例如之前谈过的嵌入),并运用矩阵来处理该向量,就像前面所看到的那样。关键点是,RNN 有某种形式的内部存储器,因此它能存储之前看到的内容。它会运用之前存储的内容判定如何准确地处理下一个输入。使用该记忆,RNN 可以“记住”预定范围内的事情,这就是我们正确地获得嵌套输出文本的方式。
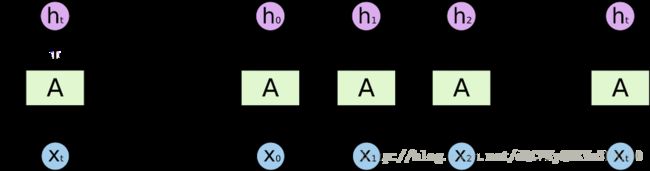
一个基本的 RNN
目前 RNN 一个比较流行的版本叫做长短期记忆网络(LSTM,Long Short-Term Memory)。LSTM 巧妙的设计了内存,并允许它:
- 有选择性的选择它记住的内容。
- 决定去忘记。
- 可以选择输出内存的量。
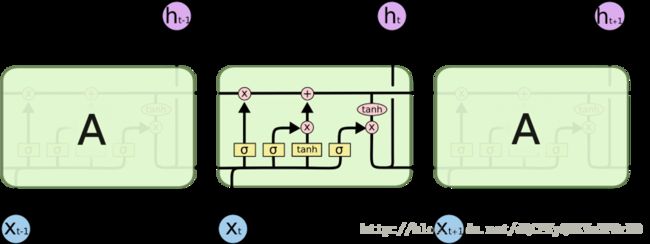
解释 LSTM 的最佳插图
所以,当 LSTM 看到“{”时就会对自己说“奥,我该记住它,这很重要”,它实际上记住的是嵌套范围内的一个迹象。一旦它看到对应的“}”时,它就会决定忘记起初的左大括号,因此也就忘记了它正处于嵌套范围内。
我们可以通过将某些概念叠加在一起的方法,让 LSTM 学到更多抽象概念,这让我们又“深度”了一次。现在,之前的每个 LSTM 的输出变成了下一个 LSTM 的输入,而且都在继续不断地学习进入的更高维的抽象数据。在上面的例子中(这只是说明性猜测),LSTM 的第一层可能会学到,被空格所分开的字符就是独立的单词。其下一层可能会学习单词的类型,如(static void action_new_function) 。接着下一层可能会学习函数概念以及它的参数,等等。尽管 Karpathy 的博客有一个很好的关于如何可视化的例子,但还是很难准确说明每一层正在做什么。
▌连接 Market2Vec 和 LSTMs
好学的读者一定会注意到,Karpathy 用字符来作为他的输入,而不是嵌入(在技术上是一个火热的字符编码)。
但是当 Lars Eidnes 写 Auto-Generating Clickbait With Recurrent Neural Network一文时,他实际上是用了单词嵌入法的。
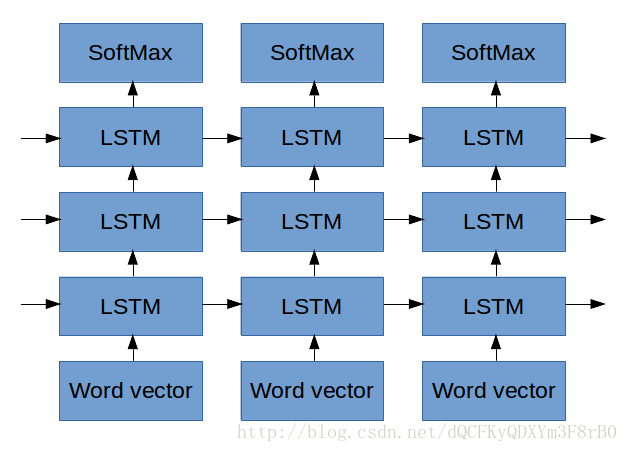
Lars Eidnes 在 Auto-Generating Clickbait With Recurrent Neural Network一文中的网络
上图就是他所使用的网络。先忽略 SoftMax 这部分,稍后再做解释。现在,让我们检查一下他是如何把一系列单词向量放在底部的(请记住,每个单词向量都是关于这个单词的向量,由一串数字组成,就像我们在本文开头看到的那样)。Lars 输入了一系列单词向量,其中每一个单词向量都:
- 影响第一个 LSTM。
- 让 LSTM 输出的东西置于 LSTM 之上。
- 让 LSTM 输出的东西提供给 LSTM 下一个单词。
我们将做些相同的事情,但有一个差异,不是我们要输入的“市场向量”这个单词向量,而是之前描述过的那些市场向量。总之,市场向量应该及时地包含既定时间点上市场正在发生的事情。当这一系列的市场向量通过 LSTM 后,我希望能捕捉到市场中一直在发生着的长期动态。通过把 LSTM 堆叠在一起,我希望能捕捉到市场行为的更高层抽象概念。
▌产出什么
到目前为止,我们还没谈论算法实际上是如何学习东西的,只是谈论了对数据的巧妙转换过程。我们将算法的学习过程推后几个自然段再谈,但是请牢牢记在心里,因为这个过程会让每件事变得有意义起来。
在 Karpathy 的例子中,LSTM 输出的是一个向量,这个向量代表某些抽象表征中的下一个字符。在 Eidnes 的例子中,LSTM 输出的是一个向量,代表某些抽象空间中的下一个单词。以上两种情况的下一步都是将抽象表征变为概率向量,这个向量列表分别说明着每个字符或单词出现在后面的可能性。这就是 SoftMax 功能的作用。一旦我们有了这张可能性列表,我们就能选择接下来最可能出现的字符或单词。
在“预测市场”的情况下,我们需要问下自己想让市场准确预测什么?这里我想到了一些选择:
- 预测每个1000股接下来的价格。
- 预测接下来的n分钟内一些指数值(标准普尔、波动率指数等)。
- 预测哪只股票在接下来的n分钟内会上涨超过x%。
- (我最喜欢的)预测哪只股票在接下来的n分钟内会上涨/下跌2x%,同时在这段时间内下跌/上涨的幅度不超过x%。
- (本文的剩余部分所遵循的)预测波动指数在接下来n分钟内上涨/下跌2x%的时间,同时在这段时间内下跌/上涨的幅度不超过x%。
1和2是回归问题,我们必须预测出实际数字而不是特定事件的可能性(如字母n出现的概率或市场上涨的概率)。这都很好,但不是我想要做的。
3和4非常类似,它们都要求预测一个事件(技术术语称为“类标签”)。事件可以是下一个字母n,也可以指过去的10分钟内某只股票上涨5%而不是下跌超过3%。3和4之间的权衡是:3更常见,因此容易去学习;而4更有价值,既是利润的指标,又对风险有一定约束。
5是这篇文章要继续了解的,因为它和3、4类似,但是有更容易遵循的机制。波动指数 VIX 有时被叫做恐惧指数,代表着 S&P500 中股票的波动程度。它是通过观察指数中每个股票特定期权的隐含波动率得出的。
旁注——为什么预测波动指数 VIX
使 VIX 成为有趣目标的原因在于:
它只是一个数字,而不是1000个股票。这使得它在概念上更容易理解并降低计算成本。
它是对许多股票的总结,因此不是所有的输入都与之息息相关。
它不是我们输入的线性组合。隐含波动率从一个个股票的复杂而又非线性的公式中提取出来的。VIX是从一个复杂公式中派生出来的,如果我们能预测它,这是相当酷的。
它是可交易的,如果真能发挥作用的话,我们就可以使用。
▌回到 LSTM 输出和 SoftMax
我们如何使用之前看到的公式来预测未来几分钟内 VIX 的变化?对于数据集中的每个点,5分钟后我们一起来看一下 VIX 发生了什么。如果在这段时间内它上升了超过1%同时下降幅度又不超过0.5%,我们将输出1,否则为0。然后我们将得到如下一个序列:
0,0,0,0,0,1,1,0,0,0,1,1,0,0,0,0,1,1,1,0,0,0,0,0 …我们想采用 LSTM 输出的向量,将这些向量压缩,这样一来我们就能得到序列中的下一个项目的概率为1。上图中的 SoftMax 部分出现了压缩现象。(从技术上来说,因为我们现在只有1个类,所以使用一个S形)。
那么,在了解其学习原理之前,让我们回顾下迄今为止我们做过的内容吧。
- 我们将1000股股票的系列价格数据作为了输入。
- 序列中的每个时间点都相当于是市场的快照。我们输入了一个有4000个数字的列表,使用嵌入层来表示只有300个数字的关键信息。
- 现在我们有了市场的嵌入序列。我们一步一步的把这些放进一叠 LSTM 中。LSTM 记住了之前步骤中的内容,这会影响它们加工当前内容的方式。
- 我们将 LSTM 第一层的输出传递到了另一层。LSTMs 不仅能够记得,而且能够学习所放进去的更高级的抽象信息。
- 最后,我们拿到 LSTMs 所有的输出,然后“压榨它们”,这样市场信息的序列就变成了一系列的概率。我们在此讨论的是“VIX 在未来5分钟内只上涨1%而不下跌0.5%的可能性”。
▌这个东西是如何学习的?
现在到了文章中比较有趣的部分。到现在为止,我们所做的一切都叫作正向传递。在训练算法以及在生产中使用的时候,我们都要涉及以上这些步骤。这里我们要谈论一下向后传递,而且只谈论在训练中让算法学习的那一部分。
因此,在训练期间我们不仅准备了数年的历史数据,还准备了一系列预测目标,即0和1的列表。这个列表显示的内容,实际上表达的是VIX是否按照我们想要的方式去做了。
为了学习,我们将市场数据反馈到网络中,并将它的输出数据与计算得出的数据进行比较。在我的例子中,比较将只是一道简单的减法问题,也就是我们的模型误差为:
误差 = (((预算)— (预测概率))² )^(1/2)
或者用文字来表达的话,即实际发生的事件与预测的事件之间的差的平方的平方根。
这就是美丽所在。这是一个微分函数,也就是说,如果我们的预测做出了微小的改变,我们也可以通过误差的变化而观察出来。我们的预测是可微函数的结果,SoftMax 输入到 softMax,LSTMs 都是可微分的数学函数。现在所有的函数都满是参数,也就是很久之前我就谈论过那些大的 excel 电子表格。考虑到模型中所有 excel 电子表格中数以万计的参数,所以在这个阶段,我们做的是取误差的导数。在求导过程中我们能够看到,参数值的改变会影响最终的误差。明白其影响原理之后,我们就可以改变其中的某些参数,以降低最终的误差值。
此过程会一直传播直到模型的开端。它调整了我们将输入嵌入到市场向量的方式,因此市场向量代表了任务中最重要的信息。
它调整了每个 LSTM 选择记住的时间和内容,这就使得它们的输出与任务最为息息相关。
它调整了 LSTM 学到的抽象概念,以便它们可以学到任务中最重要的抽象概念。
在我看来是很惊人的,因为它具有我们在任何地方都未曾指定过的所有的复杂性和抽象性。这都是从我们所认为的错误规范中推断出来的。

▌其它想法
这里有一些关于此项目的前沿观点以及我可能会尝试的内容,同时我会说明我觉得有意义的原因,这些想法可能真的会有用。
流动性和资本的有效利用
通常情况下,特定市场的流动性越强,越有效率。我认为这就相当于鸡和蛋的循环,然而当市场的流动性越来越强,它就能吸引更多的资本流出,而不受资本伤害。随着市场的流动性越来越强,有更多的资本可以使用,你会发现更多有经验的玩家纷纷加入。这是因为成为一个富有经验的人是非常昂贵的,所以你必须以大量的资本作为回报,以保证你的运营成本。
很快就能推论出,在不太流动的市场中竞争没那么复杂,因此这样的系统带来的机会可能最终不会涉及交易。重点在于,如果我试图交易的话,我将会选择市场上流动性相对较小的那一部分,可能会是 TASE 100,而不是 S&P 500。
这个东西是新的
至少在我这样平凡的人看来,这些算法的知识、执行算法的框架以及训练它们的计算能力都是新的。假设顶级玩家在几年前就想出了这个东西,并且有能力执行这么长时间,但是正如我在上面提到的,他们也很可能在能够支持其规模的流动市场中执行。我认为下一层市场参与者的技术同化速度较慢。从这个意义上来讲,在尚未开发的市场上,很快就会有一场比赛。
多个时间帧
虽然我在上面提到了单一的输入流,我想一个更有效的训练方式将是(至少)在多个时间帧上训练市场向量,并在推理阶段进行反馈。也就是说,最慢的时间帧将每30秒采样一次,我希望网络去学习延长最多时间的依赖性。
我不知道它们是否相关,但是我认为存在多个时间帧的模式,如果计算成本能足够低,那么值得将它们纳入模型。我仍在绞尽脑汁的想如何在计算图表上表示它们,或许它不是强制性的。
市场向量
当在 NLP 中使用词向量时,我们通常会从预训练模型开始,并在模型训练期间继续调整这些嵌入。在我的例子中,没有可用的预训练市场向量,也没有一个确定的算法来训练它们。
我最初考虑使用一个自动编码器,比如这篇论文中提到的:http://cs229.stanford.edu/proj2013/TakeuchiLee-ApplyingDeepLearningToEnhanceMomentumTradingStrategiesInStocks.pdf,但是端到端的训练使我逐渐打消这个想法。
更值得认真考虑的一个问题是,翻译和语言识别中的从序列到序列模型的成功,序列最终被编码为一个独立的向量,然后被解码成不同的表征形式(比如从语音到文本的形式或者从英语到法语的形式)。在这个观点下,我所描述的整个架构实质上是个编码器,而我并没有真正的向其中放置过解码器。
但是,我想用第一层来实现某些特定的功能,使其在输入4000维向量后输出一个300维的向量。我想让它找到各种股票之间地相关性或关系,并组成它们的特征。
另一种方法是,通过 LSTM 来运行每个输入,可能连接所有的输出向量,并考虑编码阶段的输出。我认为这样效率很低,因为仪器和特征之间的相互作用和相关性将会丢失,而且这将会需要相比之前多于10倍的计算量。另一方面,这样的架构可以在多个 GPU 和主机之间畅通并行,无疑是一个优点。
CNNs
最近有一些关于字符级机器翻译的文章。这篇文章:https://arxiv.org/pdf/1610.03017v2.pdf 引起了我的关注,因为它们采用 CNN 成功捕获了长范围依赖,而没有采用 RNN。我还没有阅读过,但是我认为把每个股票作为一个通道并使其在通道之间相互打通(如在 RGB 图像上),这样一个修改将是捕捉市场动态的另一种方式。同样的,这种做法的实质也是从字符中来编码语法意义。
原文链接
关注AI科技大本营微信公众号,获得更多干货文章。
