一:数据库设计
1:需求分析,粗略了解需求,弄清楚要存储什么
2:概要设计:表关系,强烈推荐使用可视化 E-R图来设计,设计完成之后,可直接生成插入sql语句,便于合作开发 也可以当成数据库字典 (工具名称:powerdesigner)
2:详细设计,设计每个表和字段的含义
二:数据库设计之三大范式
1:第一范式:保持每列的原子性
反面字段例子:一个字段里面通过逗号存储多个信息
2:第二范式:保持第一范式的前提下,一张表只存一个对象
正面例子:用户表只包含用户的关系
反面例子:用户表存了部门,用户,职位,等各种信息
3:第三范式:满足第二范式的同时,每一列都和主键有关
反面例子:冗余字段, 但如果便于查询也可以适当违反
三:数据库之事务
多条sql作为一个整体提交给数据库系统,要么全部执行完成,要么全部取消。是一个不可分割的逻辑单元
事务规范,ACID
1:Atomic原子性:要么都成功 要么都失败
2:COnsistency一致性:事务执行完,数据都是正确的
3:isolation隔离性:两个事务同时操作一张表(一列/一行),B事务要么是在A事务前完成,要么在A事务完成 后完成(锁表)
4:Durability持久性
四:数据库之锁
多个用户同时访问一个数据资源 造成并发访问
乐观锁:认为没有并发 读取更新不加锁(性能高) 更新数据做加判断 时间戳(long)OR 版本号
例子:如张二改名要改成张三 要判断是否有张二合格人 update table set name='张三' where name='张二'
悲观锁:认为有并发
共享锁:S锁 允许事务来查询;但是不允许修改;每一个数据块查询完毕马上释放;查询的时候仅仅只是锁住数据页;
排他锁:X锁,独占;事务准备写数据的时候,我既不允许你查询,我也不允许来修改;
更新锁:U锁,先查询定位到记录后 转换为X锁
怎么避免死锁产生:在高并发的项目下,死锁是无法避免的
降低死锁概率方法:
1. 不加锁就不会死锁 (nolock)
2. 严格控制SQL执行顺序;
3. 减少并发;
4. (提高数据库的性能)分表,加索引; 查的快了 就不会造成拥堵
5. 读写分离
6.设置死锁的时间(已经发现死锁等待,果断放弃一个)
五:存储过程
优点:
1.性能相比与普通SQL语句稍快,理由:sql执行的时候会先检查报错,然后索引优化,再进行执行计划 最后查数据,而存储过程是编译好的直接查数据
2.减少流量传输;降低数据库的吞吐量 只需要传存储过程需要的参数
3.需求更新超级方便;业务逻辑都在存储过程,避免代码编译发布
缺点:
1.Sql语句过多;
2.数据库压力大;(因为业务逻辑都在数据库,这就是现在用的少的原因)
3.学习成本高
六、视图
1:通过系统自带的视图查询所有包含某个字段的表
select * from INFORMATION_SCHEMA.COLUMNS where COLUMN_NAME='字段' AND TABLE_CATALOG='MYPETSHOP'
2:查看存储过程代码
select * from SYS.SQL_MODULES where OBJECT_ID=object_id('存储过程名字')
--格式化存储过程输出 :sp_helptext 存储过程名字
一、索引
表扫描
1:表存储的方式:8K为一个数据页存储 DBCC ind(ctrip,Person,-1) 可以查询table存储的形式
2:一个数据存储形式:表头,data,data的引用地址 常说的表扫描就是扫描data的引用地址
聚集索引
使用B树结构,把所有的表按物理顺序建立索引,并且放索引的叶子节点也存放着数据
B树的优点,就是为了优化磁盘存取 完全是为数据库索引量身定做的一种数据结构 与二叉树对比就能明白其索引为什么使用B树结构了
为什么聚集索引只能有一个:因为在B树结构中,因为按照顺序给物理规定好了,再多一个虽然可以但是完全没必要还浪费内存空间
非聚集索引
和聚集索引有着一样的B树结构,存放索引的叶子节点 其实是存放数据页的索引
别对单一字段和大字段加非聚集索引 并且如果 select * from 查询的话最终sql的执行计划会根据实际情况来走聚集索引进行扫描
因为当获取所有列字段的时候 会去B树一个列去扫描一次,扫描次数多了,sql执行计划会优化成走聚集索引
六:数据库-简单权限设计
需求:用户一进首页访问不同的菜单,普通设计估计就一个用户表 菜单表,但是如果批量操作的话会很不方便
核心设计理念就是:表有多对多关系的 尽量mapiing一个中间表 来解除依赖
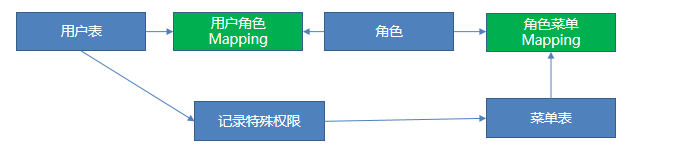
像这种关联复杂的表,查询起来可能会很费劲,那么在我们查询的时候 可以用缓存,第一次进来查到用户有哪些菜单权限就存到缓存里面
也可以用视图 把关联关系建立在视图中便于查询
七:数据库工作流表设计
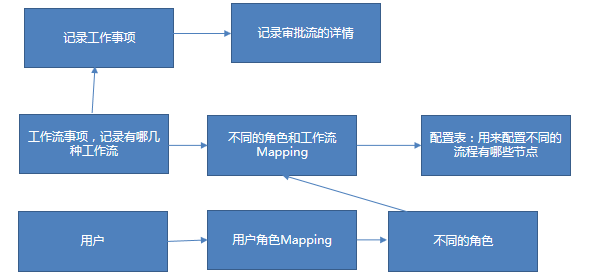
八:多层级菜单表
新增ParentID字段 做成一个树形结构 MenuLevel记录层级 存一个PAth路径字段 查询的时候可以通过 Like ‘%path’