学习CentOS7下使用ceph-deploy搭建Ceph
Ceph 独一无二地在一个统一的系统中同时提供了对象、块、和文件存储功能。
Ceph 简介 http://docs.ceph.org.cn/start/intro/
不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。
- Ceph OSDs: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
- Monitors: Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDSs: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
Ceph 把客户端数据保存为存储池内的对象。通过使用 CRUSH 算法, Ceph 可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个 OSD 守护进程持有该归置组。 CRUSH 算法使得 Ceph 存储集群能够动态地伸缩、再均衡和修复。
部署实验准备。
使用ceph-deploy 管理安装。
使用了VMware Workstation 创建了4个CentOS7虚拟机,作为实验主机。
设置主机名 主机IP
ceph-admin 192.168.199.80
ceph-1 192.168.199.81
ceph-2 192.168.199.82
ceph-3 192.168.199.83
一个 ceph-deploy 管理节点和一个三节点的Ceph 存储集群。
虚拟机基础设置
1.设置 hosts 文件。
四个主机都编辑 /etc/hosts 文件
vi /etc/hosts
末尾 添加。
192.168.199.80 ceph-admin
192.168.199.81 ceph-1
192.168.199.82 ceph-2
192.168.199.83 ceph-3
2.设置selinux。
即时生效。
setenforce 0
永久生效。便捷selinux/config 设置文件
vi /etc/selinux/config
设置
SELINUX=permissive
设置配置文件后需要重启后才会生效。可以 setenforce 0 即时生效。
3.设置防火墙
Ceph Monitors 之间默认使用 6789 端口通信, OSD 之间默认用 6800:7300 这个范围内的端口通信。 Ceph OSD 能利用多个网络连接进行与客户端、monitors、其他 OSD 间的复制和心跳的通信。
要设置firewalld允许相应的入站请求。
开放6789 端口
firewall-cmd --zone=public --add-port=6789/tcp --permanent
开放6800-7300 端口
firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
重启加载防火墙 策略 才能让设置生效
firewall-cmd --reload
4.设置 时间同步。可以连通网络的情况下。使用chronyd进行时间同步。
编辑 chronyd 配置文件。
vim /etc/chrony.conf
将原来默认的ntp服务器注释掉,设置为阿里的ntp服务器
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
重启 chronyd 服务。
systemctl restart chronyd
5.安装 epel-release
yum -y install epel*
6.设置ceph 安装源。安装版本luminous
vim /etc/yum.repos.d/ceph.repo
使用的阿里源
[ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/$basearch
enabled=1
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/noarch
enabled=1
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/SRPMS
enabled=0
priority=2
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
安装 ceph-deploy
** Ceph-Deploy不再被积极维护。它没有在比Nautilus更新的版本上进行测试。它不支持RHEL 8、CentOS 8或更新的操作系统。**
但是 CentOS7 上部署 luminous 版本还是可以的。
只在 ceph-admin 节点执行
在ceph-admin 节点安装ceph-deploy
1.确认打开了插件支持
yum install yum-plugin-priorities
cat /etc/yum/pluginconf.d/priorities.conf
确保
[main]
enabled = 1
2.安装pip 执行ceph-deploy 一下命令 需要使用。
yum -y install python2-pip
3.设置ceph-admin 可以免密 ssh 连接 ceph-1 ceph-2 ceph-3
设置密钥 按三次 Enter
ssh-keygen
将密钥拷贝到三个ceph节点
ssh-copy-id ceph-1
需要 yes 并且输入 ceph-1 的 root密码
ssh-copy-id ceph-2
ssh-copy-id ceph-3
可以测试一下 是否可以免密连接
ssh ceph-1
退出 ssh 连接
exit
4.安装ceph-deploy
yum -y install ceph-deploy
ceph-deploy 是ceph 集群 部署 工具。
创建ceph 集群。并进行基本设置。
按照官方文档进行试验
http://docs.ceph.org.cn/start/quick-ceph-deploy/
ceph集群由 ceph-1 ceph-2 ceph-3 构成。
1.在ceph-1 ceph-2 ceph-3 节点安装 ceph 软件。
可以使用 ceph-admin上的ceph-deploy 自动安装
ceph-deploy install ceph-1 ceph-2 ceph-3
或者各个 节点 手动安装。
安装依赖软件包
sudo yum install snappy leveldb gdisk python-argparse gperftools-libs
安装 ceph
yum -y install ceph ceph-radosgw
2.ceph-admin上创建一个目录。建立创建ceph集群。指定初始化的 Ceph Monitor 节点。
mkdir my-cluster
cd my-cluster
ceph-deploy new ceph-1
ceph-1 节点作为集群的 mon 节点。稍后再添加其他的mon。在当前目录可以看到ceph的 配置文件。编辑 一下保证 可以只设置两个osd就让ceph集群达到 active+clean状态。
vim ceph.conf
在 gloabal 模块下添加。(当前应该只有一个模块)
osd_pool_default_size = 2
public_network = 192.168.199.0/24
public network = {ip-address}/{netmask} 一行保证在添加额外的的mon时不出错。
3.初始化ceph集群(管理节点ceph-1执行)
配置初始 monitor(s)、并收集所有密钥:
ceph-deploy mon create-initial
完成上述操作后,当前目录里应该会出现这些密钥环:
{cluster-name}.client.admin.keyring
{cluster-name}.bootstrap-osd.keyring
{cluster-name}.bootstrap-mds.keyring
{cluster-name}.bootstrap-rgw.keyring
4.查看ceph集群状态
ceph -s
此时在 ceph-1 或者 ceph-2 ceph-3中。执行ceph -s 是无法成功地,因为在指定位置没有相应的配置文件或密钥。

配置文件和密钥在ceph-admin 的mycluster 目录中。。。
ceph-admin 在该目录执行相应命令可将配置文件添加到ceph集群中。
ceph-deploy admin ceph-1 ceph-2 ceph-3
执行完毕 再次查看 ceph 状态。。要在ceph集群中的一个主机执行。ceph-admin 只负责ceph集群中ceph 安装搭建。如在ceph-1 执行
ceph -s

可以看到services 中mgr 显示 no daemons active。
在安装有mon的节点上安装mgr。这是luminous版本中新增组件。该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好地管理ceph存储系统。 本来是可选安装,现版本如12.2.13 是必须安装
ceph-deploy mgr create ceph-1
ceph-admin执行完成后再次查看 ceph状态
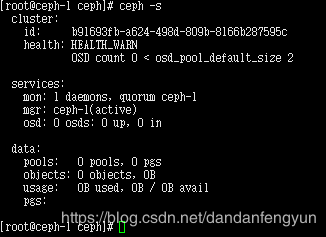
可以看到集群状态是 HEALTH_WARN。 osd 的数量小于默认的2.因为现在还未添加osd。
另一个查看ceph 集群健康状态的方法 是 命令 ceph health
detail 表示显示详情。
ceph health
ceph health detail
5.添加osd 模块。
luminous 似乎不支持 直接将一个目录设置成 osd。需要一个硬盘 或者硬盘分区。 ceph集群各个主机添加一块新硬盘。。。添加后映射为 /dev/sdb
先添加 两个 osd 。因为设置了两个osd即可达到 active+clean
格式化 硬盘。
ceph-deploy disk zap ceph-1 /dev/sdb
ceph-deploy disk zap ceph-2 /dev/sdb
ceph-deploy disk zap ceph-3 /dev/sdb
先添加两个 osd
ceph-deploy osd create --data /dev/sdb ceph-1
ceph-deploy osd create --data /dev/sdb ceph-2
只添加一个时 ceph状态

添加两个osd 后状态变为HEATTH_OK
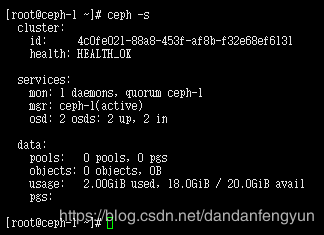
添加额外的 osd 和 mon。
添加扩充的的 osd 没什么区别
ceph-deploy osd create --data /dev/sdb ceph-3
新增 mon.
添加 Monitors
Ceph 存储集群需要至少一个 Monitor 才能运行。为达到高可用,典型的 Ceph 存储集群会运行多个 Monitors,这样在单个 Monitor 失败时不会影响 Ceph 存储集群的可用性。Ceph 使用 PASOX 算法,此算法要求有多半 monitors(即 1 、 2:3 、 3:4 、 3:5 、 4:6 等 )形成法定人数。
使用 add 命令。一次只可以添加一个主机。
ceph-deploy mon add ceph-2
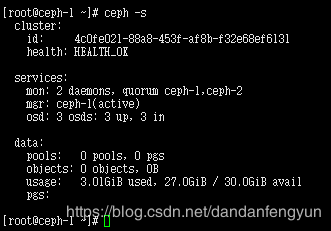
前面说过 每个运行了mon的节点上都需要安装mgr 组件
ceph-deploy mgr create ceph-2
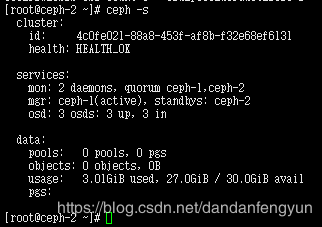
使用create 命令,一次可以创建多个 mon
ceph-deploy mon create ceph-3
ceph-deploy mgr create ceph-3
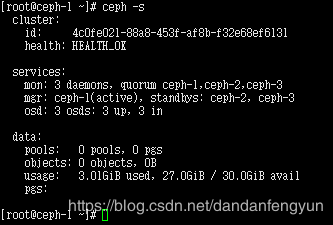
测试ceph 文件系统使用。
ceph 文件系统使用依赖 元数据服务器。 在ceph-1 节点安装
ceph-deploy mds create ceph-1
安装完成使用 ceph -s 是看不到mds 服务状态的。(因为不处于活动状态)。在ceph集群某一节点 查看
ceph mds stat
查看 ceph 文件系统
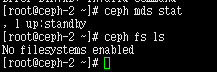
虽然已创建了元数据服务器(存储集群快速入门),但如果你没有创建存储池和文件系统,它是不会变为活动状态的。
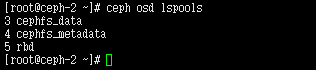
先查看当前存储池
ceph osd lspools
看其它文档。。。一般来说有一个默认存储池rbd的。可能是新版本的原因,默认已经没有任何存储池了。
![]()
创建pool,pool是ceph存储数据时的逻辑分区,它起到namespace的作用。
创建两个存储池。存储池设置涉及到了归置组的设置。
归置组。。。个人还不是特别明白归置组的数量设置具体意义。
官方建议
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
•少于 5 个 OSD 时可把 pg_num 设置为 128
•OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
•OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
•OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
其结果汇总后应该接近 2 的幂。汇总并非强制的,如果你想确保所有归置组内的对象数大致相等,最好检查下。
比如,一个配置了 200 个 OSD 且副本数为 3 的集群,你可以这样估算归置组数量:
(200 * 100)
----------- = 6667. Nearest power of 2: 8192
3
注,这是单个存储池的计算方法。。。
当用了多个数据存储池来存储数据时,你得确保均衡每个存储池的归置组数量、且归置组数量分摊到每个 OSD ,这样才能达到较合理的归置组总量,并因此使得每个 OSD 无需耗费过多系统资源或拖慢连接进程就能实现较小变迁。
这个不是很懂。也就只把官方文档内容抄下来了。有一点注意。可以根据设置的归置组数量和池数量计算出每个osd上归置组的大约数量。。。比如三个存储池,存储池默认副本数为2(osd_pool_default_size = 2)。设置存储池是每个存储池pg_num 都是 128。这时每个osd 上归置组数量大约是 128 * 3 * 2 / 3 = 256 。。。
官方建议 每个OSD上大约100个归置组。。。这个建议可以帮助我们计算。默认的每个osd上最大归置组数量是250 当然是可以修改的。
mon_max_pg_per_osd 250
这样 设置多个存储池时,我们可以做一下数学题。把归置组数量作为要求的值?。尽量保证每个osd上归置组数量在50-250 之间。尽量往100靠近(最好大于100)。。。最后选择一个接近2的幂的值。
**比如。三个osds 副本数量是3(默认为3),准备设置三个存储池。
50 * 3(3个osd) 约 27< ? < 84
选择一个 2的幂。。。那就是32 或者64。然后算一下哪个值 下osd上归置组数量更接近 100
32 的话 32 * 3 * 3 / 3 = 96
64 的话 64 * 3 * 3 / 3 = 192
尽管 96 更接近 100 但是 感觉应该 归置组数量是32和64 都可以。。。另,单个节点osd数量少的情况下mon_max_pg_per_osd 建议可以调大一点。
**
附,如果一个节点上有许多osd 那么每个osd上的归置组数量尽量少一点。
说了好多归置组。重新回到 ceph 文件系统
一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
•为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
•为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_metadata 128
查看当前存储池
ceph osd lspools
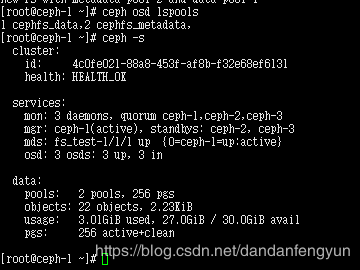
创建的ceph文件系统名 是fs_test
ceph fs new fs_test cephfs_metadata cephfs_data
查看 mds 服务,和 ceph 文件系统
ceph mds stat
ceph fs ls

似乎只能设置一个文件系统名或者 一个元数据存储池只能供一个文件系统使用。
因此 ceph fs new fs_test2 cephfs_metadata cephfs_data会失败
![]()
接下来 使用一个ceph-client 主机测试ceph文件系统的使用。。。可以新建一个主机 ceph-client。将其加入 ceph-admin的hosts中。或者直接使用 ceph集群中 某一主机。。。
新建 一主机 IP 192.168.199.85 由于只是测试ceph文件系统使用,不参与ceph集群部署,因此不用设置 时间同步。但是 selinux和ceph安装源要设置。
ceph-admin 的 /etc/hosts 文件加入 ceph-client
设置ceph-admin ssh 免密登录 ceph-client
ssh-copy-id ceph-client
ceph-client安装 ceph 软件,依然在ceph-admin上执行
ceph-deploy install ceph-client
创建密钥文件
1.在密钥环文件中找到与某用户对应的密钥例如:
cat ceph.client.admin.keyring
当前也没有创建其它用户也只有这一个默认的。
2.找到用于挂载 Ceph 文件系统的用户,复制其密钥。大概看起来如下所示:
[client.admin]
key = AQCTUctes9x1NBAALpsftppssFdsDeFscvQZjA==
3.复制密钥到一个文本中 该文本文件名 admin.secret
文本内容。
AQCTUctes9x1NBAALpsftppssFdsDeFscvQZjA==
4.复制该文本文件到 ceph-client 的某一个目录中。比如root用户根目录。并确保该文件可读
chmod +r admin.secret
ceph fs文件系统可用两种方式。内核驱动和用户空间文件系统( FUSE )
内核驱动
创建挂载点
mkdir /mnt/test_cephfs
执行挂载指令,要在admin.secret 所在的目录下执行,或者输入admin.secret 的绝对路径
mount -t ceph 192.168.199.81:6789:/ /mnt/test_cephfs -o name=admin,secretfile=admin.secret
192.168.199.81 可以是81 82 83。只要是mon所在节点即可。
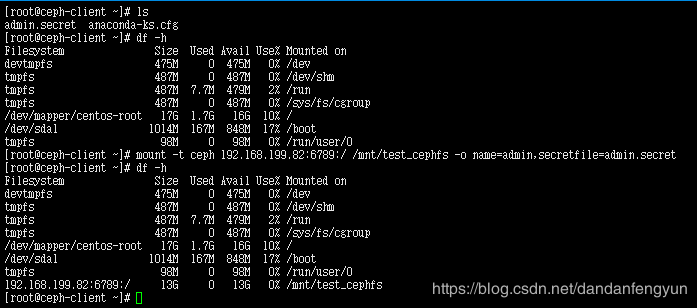
为什么容量是 13 这个我也不太清楚。。。理论上三个硬盘,每个都是10G。那一共是30G。然后备份数是2,那应该是15G吧。好吧,其实差不多。
取消挂载
umount -l /mnt/test_cephfs/
用户空间文件系统( FUSE )
将ceph.client.admin.keyring 密钥环复制到 ceph-client 中,假定还放在root目录。
![]()
ceph-client 上安装ceph-fuse ceph-client 执行
yum -y install ceph-fuse
创建挂载点
mkdir /mnt/test_fuse
测试挂载
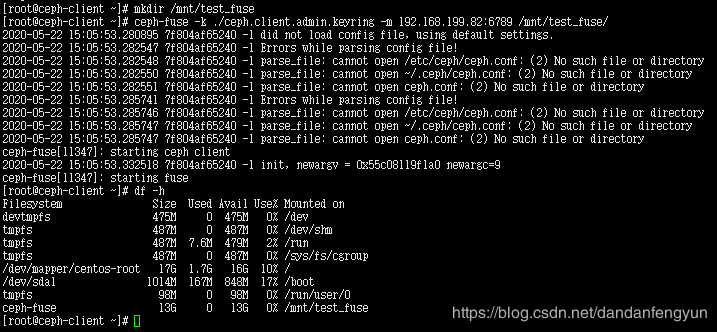
取消挂载
fusermount -u /mnt/test_fuse
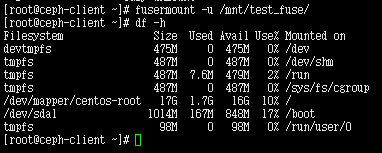
或者 直接 umount也是可以的
存储池创建 和 配置文件修改应用
准备测试 ceph 块设备使用。。。发现需要先创建一个存储池。。。
ceph osd pool create rbd 128

因为之前为ceph 文件系统已经创建过 两个存储池。且 pg_num为128。再创建一个 pg_num 为128的存储池的话。。。根据备份数量为2 总的归置组 是 768 超过的 mon_max_pg_per_osd(默认250)* 3(3个osd)。
解决办法 一个是 修改ceph 配置文件,将mon_max_pg_per_osd 设置的更大一点。
还有一个 重新设置几个存储池的pg_num 设置的更小一点。(基本上不会这样设置,因为pg_num变更时只能设置的更大,不能设置的更小)要想实现,只能删除原来的存储池再重新创建。
方式一更简单一点。。但是这里采用的方式二。因为是测试使用。。。
1.删除ceph文件系统
停止mds服务
systemctl stop ceph-mds.target
删除ceph 文件系统
ceph fs rm fs_test --yes-i-really-mean-it
删除 mds 服务 mds的id默认从0开始,指定不存在的id并不会报错
ceph mds rm 0
2.删除掉原来两个存储池
编辑 配置文件 ceph.conf
在 ceph-admin 主机的 /root/mycluster 目录下 编辑
vim ceph.conf
新增
mon_allow_pool_delete = true
把新增的设置配置到ceph集群。
ceph-deploy --overwrite-conf config push ceph-1 ceph-2 ceph-3
重启 mon 服务
systemctl restart ceph-mon.target
删除两个存储池
ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it
ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
3.假设只有三个存储池,副本数目为2 根据建议每个osd上有大约100个归置组 且小于250 大约计算出 每个存储池的的pg_num 应是 64。
查看现有存储池。发现为空
ceph osd lspools
设置三个 存储池。
ceph osd pool create cephfs_data 64
ceph osd pool create cephfs_metadata 64
ceph osd pool create rbd 64
其实现在只用设置一个 rbd 存储池 就够了。因为现在测试块存储使用
只有一个存储池的话 pg_num 又可以设置为128
ceph osd pool create rbd 128
有时候你可能要为新创建的 rbd 存储池设置相应的的application
大约分为 块存储 文件系统 网关
enable use of an application [cephfs,rbd,rgw] on pool
ceph osd pool application enable rbd rbd --yes-i-really-mean-it
理所当然的设置为 rbd
测试块设备使用。
现在已经创建了rbd 的存储池。可以测试块设备的使用了。
简单来说,块设备可以虚拟出一块硬盘,挂载到本地。或者供cloudstack等云平台使用。
在管理节点上,用 ceph-deploy 把 Ceph 配置文件和 ceph.client.admin.keyring 拷贝到 ceph-client 。
ceph-deploy admin ceph-client
ceph-deploy 工具会把密钥环复制到 /etc/ceph 目录,要确保此密钥环文件有读权限(如 sudo chmod +r /etc/ceph/ceph.client.admin.keyring )。
在 ceph-client 节点上创建一个块设备 image 。单位是M名称 foo
rbd create --size 4096 foo
可以指定存储池。
rbd create --size 4096 rbd/foo
一般不指定存储池 会选择存储池 rbd
查看 新创建的块设备
rbd ls
指定 存储池
rbd ls rbd
查看块设备详细信息
rbd info foo
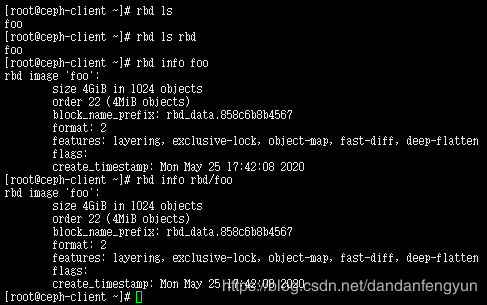
调整块设备映像大小
Ceph 块设备映像是精简配置,只有在你开始写入数据时它们才会占用物理空间。然而,它们都有最大容量,就是你设置的 --size 选项。如果你想增加(或减小) Ceph 块设备映像的最大尺寸,执行下列命令:
rbd resize --size 2048 foo (to increase)
rbd resize --size 2048 foo --allow-shrink (to decrease)
要挂载块设备映像,先罗列出所有的映像。
rbd list
映射块设备
用 rbd 把映像名映射为内核模块。必须指定映像名、存储池名、和用户名
sudo rbd map {pool-name}/{image-name} --id {user-name}
如
sudo rbd map rbd/foo --id admin
或者
sudo rbd map foo --name client.admin
可能报错
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable foo object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
按提示 执行
rbd feature disable foo object-map fast-diff deep-flatten
后再进行映射即可
sudo rbd map rbd/foo --id admin
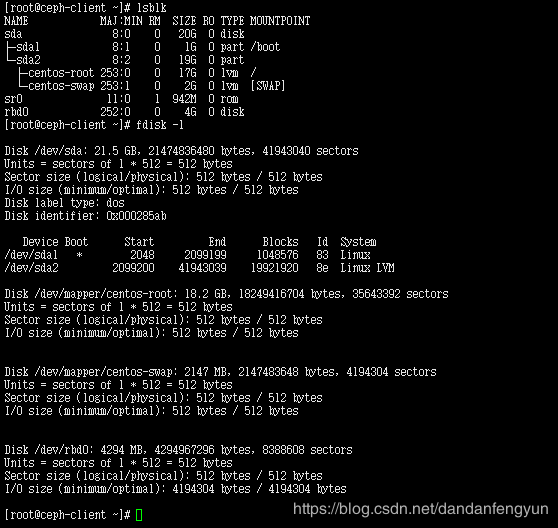
映射前查看 磁盘信息
lsblk
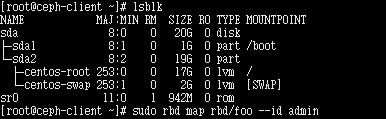
映射后磁盘信息
lsblk
fdisk -l
查看已映射块设备
rbd showmapped
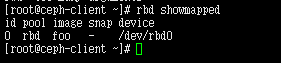
可以看到 块设备映像 名 foo 存储池 pool 映射到设备 /dev/rbd0
测试挂载本 设备 映像。
首先 设置 设备 文件格式 设置成 ext4
mkfs.ext4 /dev/rbd0
或者
mkfs.ext4 /dev/rbd/rbd/foo
设置 挂载点 开始挂载
mkdir /mnt/test_image
mount /dev/rbd0 /mnt/test_image/
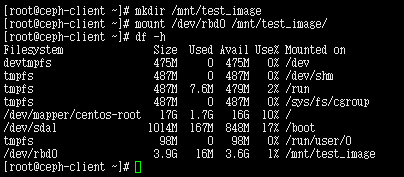
/dev/rbd0 和 /dev/rbd/rbd/foo 是同一块设备

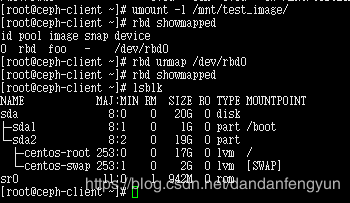
取消 模块映射。
rbd unmap /dev/rbd0
或者
rbd unmap /dev/rbd/rbd/foo
删除设备映像
rbd rm {image-name}
指定存储池
rbd rm {pool-name}/{image-name}
rbd rm rbd/foo
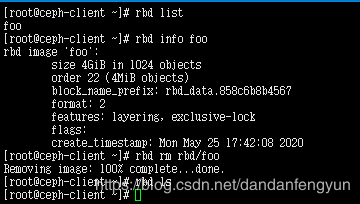
**可以设置容量超过 可存储量的映像设备。比如只有3个osd,每个硬盘10G 不算副本最多30G。。但是可以创建一个 50G的映像设备。**只有当真正向其中写入数据才会占用真实硬盘空间。
测试使用块设备当作cloudstack的主存储。
当搭建好一个ceph 集群后,可以用来做cloudstack的主存储。
ceph初始搭建完成。上面没有任何存储池。
创建存储池 cloudstack
ceph osd pool create cloudstack 128
创建用户 cloudstack
ceph auth get-or-create client.cloudstack mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=cloudstack'
记下生成的 密钥
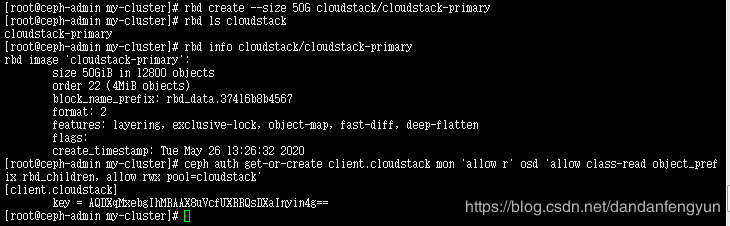
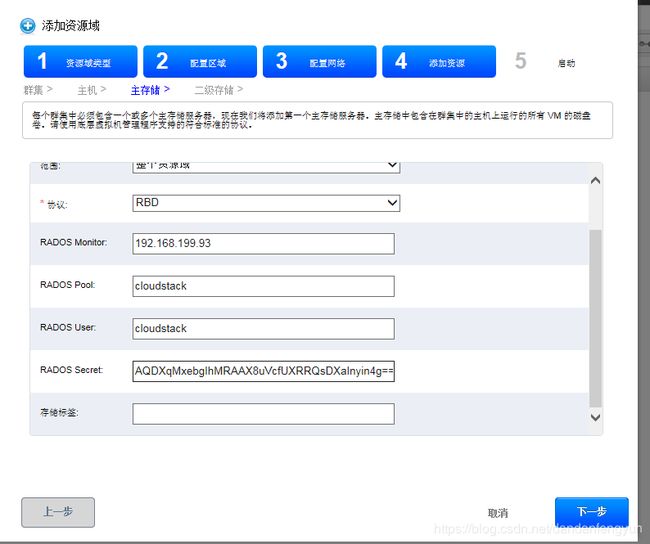
cloudstack在添加主存储时 可以 设置成ceph
主存储 协议 选择 rbd
RADOS Monitor 填写ceph集群运行 mon 服务的节点 其中一个,根据建议(你可以在多个 monitors 上创建一个轮询域名服务)。
RADOS Pool 填写 准备当作 cloudstack主存储使用的存储池 就是刚才创建的 cloudstack
RADOS Pool 填写 创建的用户 cloudstack
RADOS Secret 填写cloudstack 用户的密钥
AQDXqMxebgIhMRAAX8uVcfUXRRQsDXaInyin4g==