ISBN 978-7-302-45375-8
简介
Hadoop
大数据存储与处理平台
HDFS(Hadoop Distributed File System)
批处理,而非实时互动处理。提高存取大量数据的能力,牺牲响应时间。
文件存储架构:
- 文件分割
- 区块(block)副本
- 机架(rack)感知
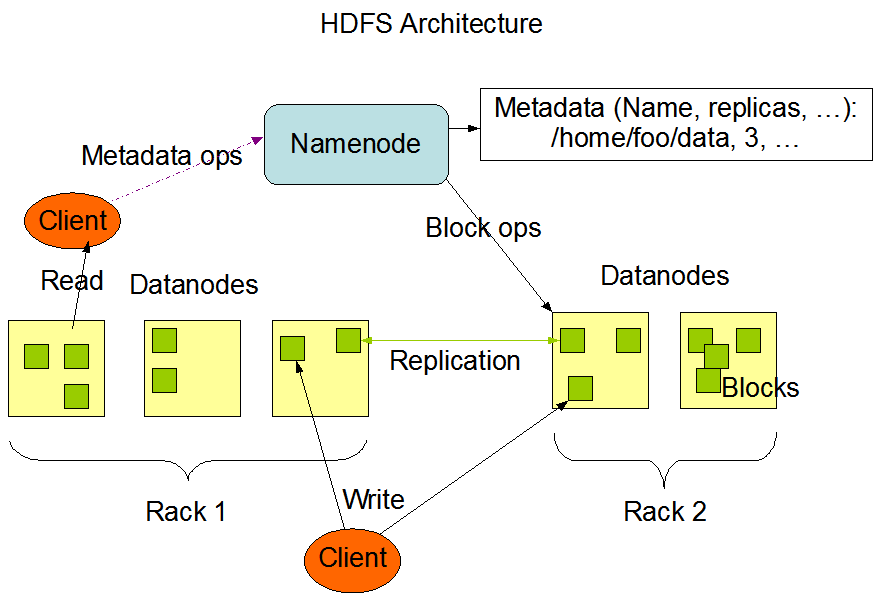
NameNode:管理和维护HDFS目录系统并控制文件的读写操作
DataNode:存储数据
Hadoop MapReduce
Map:将任务分割成更小任务,由每台服务器分别运行
Reduce:将所有服务器的运算结果汇总整理,返回最后结果
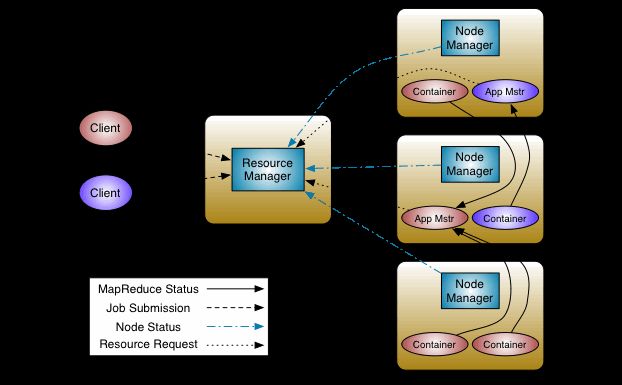
MapReduce2:YARN(Yet Another Resource Negotiator)
Spark
集群运算框架(基于内存)
MapReduce在运算时,需要将中间数据存储在硬盘中,导致磁盘I/O成为性能瓶颈,出现读写数据延迟的问题。
in-memory计算框架:
HDFS读取 -> 内存写入 -> 内存读取 -> 内存写入 -> 内存读取 -> HDFS写入
MapReduce:
HDFS读取 -> HDFS写入 -> HDFS读取 -> HDFS写入 -> HDFS读取 -> HDFS写入
弹性:
- streaming数据流处理
- SQL互动分析
- MLlib机器学习
- 图表计算
安装
test on Debian 9.9 Linux 4.9.0-8-amd64
Hadoop single node cluster
JDK
Hadoop是Java开发的,首先安装JDK。
java -version系统中已经有OpenJDK 1.8了,考虑到实验(分布式大规模数据函数依赖发现)要求,后面编译时需要兼容JDK 1.7。
查看安装路径,一般为/usr/lib/jvm/java-8-openjdk-amd64。
update-alternatives --display javaSSH
NameNode远程连接DataNode进行管理,安装SSH并设置为无需手动输入密码。
sudo apt-get install ssh
sudo apt-get install rsync产生SSH Key
ssh-keygen -t rsa -C "youremail@example.com"公钥加入许可证文件,从而无密码登录本机。
cat .ssh/id_rsa.pub >> .ssh/authorized_keysHadoop
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
sudo tar -zxvf hadoop-2.7.3.tar.gz
sudo mv hadoop-2.7.3 /usr/local/hadoop在.bashrc中设置环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH修改Hadoop配置文件
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
必须显式给出。
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/usr/local/hadoop/etc/hadoop/core-site.xml
fs.default.name
hdfs://localhost:9000
/usr/local/hadoop/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
设置监控Map与Reduce程序的JobTracker任务分配情况以及JobTracker任务运行情况。
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop/hadoop_data/hdfs/namenode
dfs.datanode.data.dir
file:/usr/local/hadoop/hadoop_data/hdfs/datanode
创建并格式化HDFS目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo chown username:groupname -R /usr/local/hadoop
hadoop namenode -format启动
start-dfs.sh
start-yarn.sh查看
Java Virtual Machine Process Status Tool:jps
Web:
- Hadoop ResourceManager:
http://localhost:8088/ - HDFS:
http://localhost:50070/
Hadoop Multi Node Cluster
通过复制Single Node Cluster创建多个虚拟主机代替实体服务器的方法可以作为演练,但是不能享受并行处理的优势。
下面不采用书上多个虚拟机的方法,而是实现一个本机作为master,在docker上建立多个slave的架构。

Docker
- 安装
- 设置sudo权限
- 使用国内仓库镜像站:在
/etc/default/docker文件最后加一行DOCKER_OPTS="--registry-mirror=https://registry.docker-cn.com" - 制作docker容器镜像,也可以去docker hub下载。
制作Single Node Cluster镜像
启动一个ubuntu容器:docker container run -it ubuntu bash
按Ctrl-d退出,查看容器id:docker container ls --all
复制Hadoop安装包:docker cp hadoop-2.7.3.tar.gz id:/root/
回到容器:docker container start -i id
一些辅助工作,然后重复Single Node Cluster的步骤:
apt-get update
apt-get install openjdk-8-jdk
apt-get install vim
apt-get install net-tools
apt-get install inetutils-ping
mkdir /run/sshd
echo /usr/sbin/sshd >> ~/.bashrc保存为新镜像:docker commit -a "author" -m "hadoop single node cluster on ubuntu" id hadoop
制作slave服务器镜像
启动:docker container run -it hadoop
修改/usr/local/hadoop/etc/hadoop/core-site.xml:
fs.default.name
hdfs://master:9000
修改/usr/local/hadoop/etc/hadoop/yarn-site.xml:
yarn.resourcemanager.resource-tracker.address
master:8025
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.address
master:8050
修改/usr/local/hadoop/etc/hadoop/mapred-site.xml:
mapred.job.tracker
master:54311
修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml:
把host的SSH Key写入~/.ssh/authorized_keys。
保存镜像:docker commit -a "author" -m "hadoop slave on ubuntu" id hadoop-slave
实例化三个镜像容器:
docker container run -it -h slave1 --name slave1 hadoop-slave
docker container run -it -h slave2 --name slave2 hadoop-slave
docker container run -it -h slave3 --name slave3 hadoop-slave分别在三个容器中使用ifconfig查看ip,然后设置/etc/hosts。
设置master服务器
网络配置:
172.17.0.1 master
172.17.0.2 slave1
172.17.0.3 slave2
172.17.0.4 slave3修改下列文件同slave服务器:
/usr/local/hadoop/etc/hadoop/core-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml
/usr/local/hadoop/etc/hadoop/mapred-site.xml
修改/usr/local/hadoop/etc/hadoop/hdfs-site.xml:
设置/usr/local/hadoop/etc/hadoop/slaves文件。
设置~/.ssh/config默认登录用户名为root。
启动
在每个服务器上删除并重建namenode和datanode目录后,在master上格式化并启动。
问题:当master直接在host os上时,遇到了8088显示3 nodes,而50070显示0 live nodes的问题,把master也放到docker上就没有问题。试了很多解决方案都不行,看来只能先在docker中的master上继续了。
Hadoop HDFS 命令
hadoop fs -*Hadoop MapReduce
WordCount
计算文件中每一个英文单词出现的次数,包含如下几步:
- Map:将文字转换为(key,value),其中key是word,value是其出现次数
- Shuffle:将相同的key排列在一起
- Reduce:将相同key的value相加
编辑WordCount.java
设置环境变量
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar编译(书上第一条命令有误,javac的j不大写)
hadoop com.sun.tools.javac.Main WordCount.java
jar cf wc.jar WordCount*.class创建测试文本
cp /usr/local/hadoop/LICENSE.txt input/
cd input
hadoop fs -mkdir -p /user/root/wordcount/input
hadoop fs -copyFromLocal LICENSE.txt /user/root/wordcount/input
hadoop fs -ls -R /运行并查看
hadoop jar wc.jar WordCount /user/root/wordcount/input/LICENSE.txt /user/root/wordcount/output
hadoop fs -ls /user/root/wordcount/output
hadoop fs -cat /user/root/wordcount/output/part-r-00000 | more缺点
- 设计模式不易用,API较低级,开发效率低
- 中间数据保存到硬盘,运行效率低
- 不支持实时处理,原始设计以批处理为主
Spark
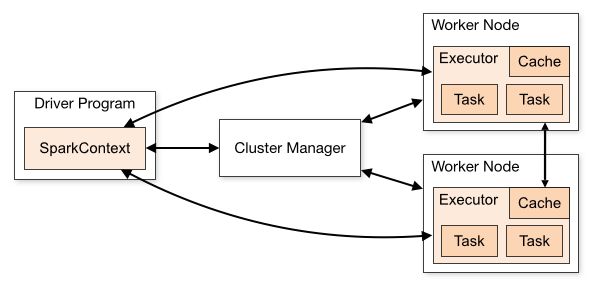
Cluster Manager运行模式:
- Local Machine
- Spark Standalone Cluster
- Hadoop YARN
- 云端(例如AWS的EC2平台)
安装Scala
wget https://www.scala-lang.org/files/archive/scala-2.10.4.tgz
tar xvf scala-2.10.4.tgz
sudo mv scala-2.10.4 /usr/local/scala
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin安装Spark
wget https://archive.apache.org/dist/spark/spark-2.1.3/spark-2.1.3-bin-hadoop2.7.tgz
tar zxf spark-2.1.3-bin-hadoop2.7.tgz
sudo mv spark-2.1.3-bin-hadoop2.7 /usr/local/spark
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin使用spark-shell启动可以看到Spark和Scala的版本,由于Spark内置Scala的原因,显示的Scala版本可能与之前安装的不同。
配置spark-shell显示信息:
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties把log4j.rootCategory的值由INFO改为WARN。
Local Machine
启动Hadoop之后执行spark-shell --master local[4]。
读取本地文件:
var textFile=sc.textFile("file:/usr/local/spark/README.md")
textFile.count读取HDFS文件:
var textFile=sc.textFile("hdfs://master:9000/user/root/wordcount/input/LICENSE.txt")
textFile.countHadoop YARN
书上的Spark版本较旧,已经不再适用。
Spark Standalone Cluster
配置/usr/local/spark/conf/spark-env.sh:
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=800m
export SPARK_WORKER_INSTANCES=2把spark目录复制到slave结点:
ssh slave1
mdkir /usr/local/spark
exit
scp -r /usr/local/spark/ root@slave1:/usr/local配置/usr/local/spark/conf/slaves同/usr/local/hadoop/etc/hadoop/slaves。
启动/usr/local/spark/sbin/start-all.sh,可以看到服务器数*worker实例数(3*2)共6个worker。
在Spark Standalone运行spark-shell:spark-shell --master spark://master:7077。
在Spark Standalone Web UIhttp://master:8080可以看到启动的worker和当前运行的程序spark-shell。
停止:/usr/local/spark/sbin/stop-all.sh。
Spark WordCount
mkdir -p /root/projects/wordcount/data
cd /root/projects/wordcount/data
vim test.txtApple Apple Orange
Banana Grape Grapespark-shellval textFile=sc.textFile("file:/root/projects/wordcount/data/test.txt")
val stringRDD=textFile.flatMap(line => line.split(" "))
val countsRDD=stringRDD.map(word => (word, 1)).reduceByKey(_ + _)
countsRDD.saveAsTextFile("file:/root/projects/wordcount/data/output")