作为NASNet的同期论文,BlockQNN同样地将目光从整体网络转换到了block-wise,整体思路大概是MetaQNN的block版,增加了一些细节地小修改。配合Early Stop Strategy,计算资源十分少,但性能较同期的NASNet差点
来源:晓飞的算法工程笔记 公众号
论文: Practical Block-wise Neural Network Architecture Generation

- 论文地址:https://arxiv.org/abs/1708.05552v2
Introduction
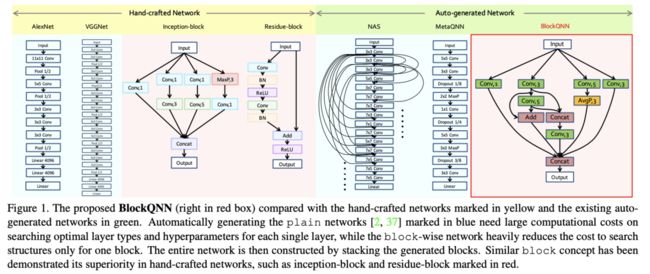
为了让网络搜索更高效,论文提出block-wise网络生成方法BlockQNN,整体的思想跟同期的NasNet十分类似,不同点在于这篇论文是基于Q-learning进行学习的,可以认为是MetaQNN的block版。BlockQNN以block为单位进行搜索,每个block包含多层,然后再将block按预设的框架堆叠成完整的网络,这样不仅能提高搜索的效率,还可以提高搜索结果的泛化能力。
BlockQNN主要有以下有点:
- Effective,自动生成的网络的性能与人工设计的网络相当。
- Efficient,首个考虑block-wise的自动网络生成方法,配合Early Stop Strategy仅需要32GPU3天。
- Transferable,CIFAR上搜索到的架构仅添加些许修改就能迁移到ImageNet上。
Methodology
Convolutional Neural Network Blocks
现代卷积网络大都可以看成是多个相似block的堆叠,只是每个block的超参数不同。因此,针对block的精心设计不仅可以达到更高的准确率,还可以有更好的泛化能力。为此,论文主要针对block结构的自动生成。
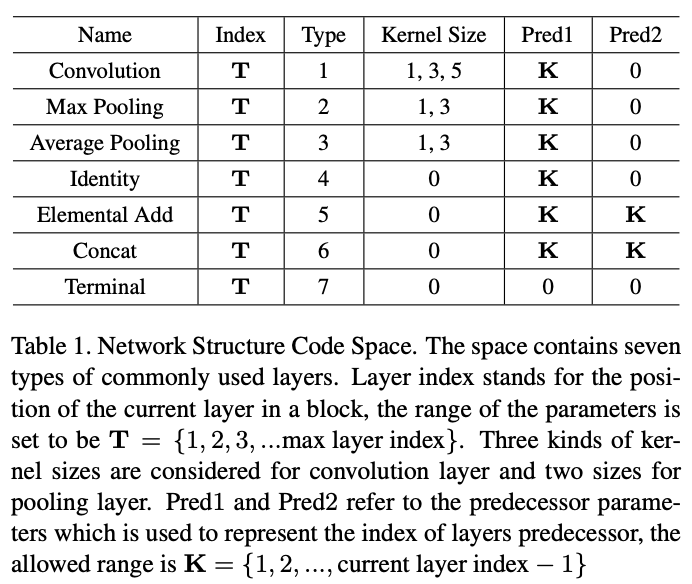

CNN网络的前向推理可以看成一个有向无环图,为了统一,使用网络结构编码(Network Structure Code,NSC)进行表示,如图2。每个block由一组5-D NSC向量表示,前3个值分别表示层序号,操作类型,核大小,后两个值表示输入对应的层序号,如层包含单个输入,则第二个输入序号为0。如果层的输出没有作为其它层的输入,则conate成最终的输出。这里的卷积操作指的是预激活卷积单元(a Pre-activation Convolutional Cell, PCC),包含ReLU、卷积以及BN,这样的设定能减少搜索空间并保持较好的性能。

基于以上搜索到的block,将普通的网络转换成对应的block版本,CIFAR-10和ImageNet数据机的堆叠网络如图3所示,block内没有下采样模块,下采样直接使用池化层,每个block会重复N遍来满足不同的要求。如果特征图大小下降了一半,则权重增加两倍。
Designing Network Blocks With Q-Learning
论文使用Q-learning加速搜索,Q-learning是强化学习的其中一种,目的是选择合适的action来最大化累计奖励,包含agent,states和actions。state $s\in S$代表当前层结构NSC,action $a\in A$为后续层结构NSC的选择,由于NSC合集是有限的,state和action空间也是有限且离散的,保证了搜索空间相对较小。

状态转移过程$(s_t, a(s_t)) \to (s_{t+1})$如图4a所示,$t$代表当前层,而图4b则是图4a的状态转移构建的实际网络。agent的主要任务是选择block的NSC结构,block的结构可以认为是action的选择轨迹$\tau_{a_{1:T}}$,比如一连串NSCs。论文将层选择过程视为马尔科夫决策,假定在某个block中表现好的层在别的block中也可以表现得不错。

为了找到最好的结构,agent需要最大化所有可能路径的回报期望$R_{\tau}$,$\mathbb{R}$为累计回报。

通常使用公式2的Bellman’s Equation进行公式1的优化,给予状态$s_t \in S$以及后续的操作$a \in A(s_t)$,定义最大的总期望回报为$Q^*(s_t, a)$,即state-action对的Q-value。

由于期望很难直接求得,所以一般采取迭代式Bellman’s Equation,以经验假设的方式解决公式2。$\alpha$为学习率,决定新旧状态的占比,$\gamma$为折扣率,决定后续回报的权重,$r_t$为当前状态$s_t$得到的中间回报,$s_T$代表最终状态,$r_T$为对应网络收敛后的验证准确率。

由于$r_t$不能显示地计算,这里采用reward shaping的方法加速训练,之前的方法比如MetaQNN都直接将中间奖励设为零,这会导致RL耗时,因为在刚开始的阶段,$s_T$的Q-value会明显高于其它状态(终止层Q-value无折扣率,直接是准确率?),导致网络偏向于构建很少层的小block(倾向于选择终止层)。

这里对reward shaping进行了实验,可以看到使用后能显著提高收敛速度。
完整的学习过程如图4c,agent首先采用一系列结构编码来构建block并构建完整的网络,然后训练生成的网络,将验证准确率作为reward来更新Q-value,最后,agent选择另外的结构编码来获得更好block结构。
Early Stop Strategy

尽管block-wise的生成方式能增加搜索速度,但仍然十分耗时,这里采用early stop strategy来进一步加速。early stop strategy可能带来较低的准确率,如图6所示,early stop strategy的准确率明显低于最终的准确率,意味着early stop strategy没有完全体现block的效果。同时,论文注意到FLOPs以及block的density与最终准确率为负相关的

基于上面的发现,论文重新定义了reward函数,$\mu$和$\rho$为平衡因子,新的reward函数能更好地关联最终准确率。基于early stop strategy和较小的搜索空间,仅需要32卡搜索3天。
Framework and Training Details
Distributed Asynchronous Framework

论文使用分布式异步框架进行搜索,如图7所示,包含三部分:
- master node: 采样batch block结构。
- controller node: 使用block构建完整网络结构,分配给compute node。
- compute node: 训练并返回网络的验证准确率。
Training Details

- Epsilon-greedy Strategy,有$\epsilon$概率进行随机action选取,$1- \epsilon$概率选择最优action,$\epsilon$随训练逐步下降,有助于agent平滑地从探索模式转换为榨取模式。
- Experience Replay,与MetaQNN一样,保存结构和对应准确率,在一定区间内直接采样存储的结构进行agent训练。
Results
Block Searching Analysis

这里展示了Epsilon-greedy Strategy的效果,在开始榨取模式后,准确率极速提升。

这里验证PCC的作用,可以看到,PCC的效果十分明显。
Results on CIFAR


Transfer to ImageNet

CONCLUSION
作为NASNet的同期论文,BlockQNN同样地将目光从整体网络转换到了block-wise,整体思路大概是MetaQNN的block版,增加了一些细节地小修改。配合Early Stop Strategy,计算资源十分少,但性能较同期的NASNet差点。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
