模型元选项
- 每个model都可以定义一个Meta类,使用内部的class Meta 定义模型的元数据,这个类中可以定义一些关于你的配置,Meta是一个model内部的类
- 模型元数据是“任何不是字段的数据”,比如排序选项(ordering),数据库表名(db_table)或者人类可读的单复数名称(verbose_name 和verbose_name_plural)。在模型中添加class Meta是完全可选的,所有选项都不是必须的。
class Meta:
db_table = "topic"
managed = True
ordering = ['-id']
verbose_name = u"主题"
verbose_name_plural = u"主题列表"
db_table:string,在数据库中的表名,否则Django自动生成为app名字_类名
managed: bool, 默认值为True,这意味着Django可以使用syncdb和reset命令来创建或移除对应的数据库。
ordering: 数组, 默认排序规则,每个字符串是一个字段名,前面带有可选的“-”前缀表示倒序。前面没有“-”的字段表示正序。使用"?"来表示随机排序。
verbose_name: string model对象的描述
verbose_name_plural: string 复数时的描述
模型字段
 image.png
image.png
模型字段常用的参数
 image.png
image.png
null与blank:
- blank 是针对表单的,如果 blank=True,表示你的表单填写该字段的时候可以不填,比如 admin 界面下增加 model 一条记录的时候。直观的看到就是该字段不是粗体,设置为False时,字段是必须填写的。字符型字段CharField和TextField是用空字符串来存储空值的。默认不允许为空。
- null 是针对数据库而言,如果 null=True, 表示数据库的该字段可以为空。默认不允许。日期型、时间型和数字型字段不接受空字符串。所以设置IntegerField,DateTimeField型字段可以为空时,需要将blank,null均设为True。
总之:
blank,只是在form表单验证时可以为空,而在数据库上存储的是一个空字符串;null是在数据库上表现NULL,而不是一个空字符串;
需要注意的是,日期型(DateField、TimeField、DateTimeField)和数字型(IntegerField、DecimalField、FloatField)不能接受空字符串,如要想要在填写表单的时候这两种类型的字段为空的话,则需要同时设置null=True、blank=True;
auto_now 与auto_now_add区别:
auto_now_add: 只有第一次才会生效,比如可以用于文章创建时间
auto_now: 每一次修改保存对象时都会将当前时间更新进去,只有调用Model.save()时更新,在以其他方式(例如 QuerySet.update())更新其他字段时,不会更新该字段,但您可以在此类更新中为字段指定自定义值。可用于文章修改时间;
模型中的关系
一对一:一本书籍有一个编号;
多对一:一本书籍有多个评论;--注意Django只有多对一关系,站在多的角度去看待;
多对多:一本书籍有多个作者,一个作者可以写多本书籍;
class Author(models.Model):
name = models.CharField(u'姓名', max_length=200)
email = models.EmailField(u'邮箱')
class Number(models.Model):
number = models.CharField(u'编号', max_length=200)
class Book(models.Model):
headline = models.CharField(u'大标题', max_length=255)
pub_date = models.DateTimeField(u'出版时间')
authors = models.ManyToManyField(Author)
number = models.OneToOneField(Number)
class Reply(models.Model):
book = models.ForeignKey(Book) #外键字段
content = models.CharField(u'内容', max_length=255)
- ForeignKey外键
多对一关系,关联模型关联的类,定义在多的类中,如上Reply类中;
属性:
db_constraint:bool 是否建立外键约束
to_field:string 关联到的关联对象的字段名称。默认地,Django 使用关联对象的主键。
related_name: string 关联对象反向引用描述符。.如果你不想让Django 自动创建一个反向关联(Django自动是以子表_set命名的),则可以自己定义。
on_delete: string 可以取如下值
CASCADE:级联删除,如果删除,相关联的那个也会删除
PROTECT:保护类型。如果删除,将会抛出一个ProtectedError错误
SET_NULL:如果删除了本条数据,外键的那条数据将会设置为null,这个只有在外键null为True的情况下才可以使用
SET_DEFAULT:如果删除了本条数据,外键那条数据将会职位默认值,这个只有在外键那个字段设置了default参数才可以使用 - ManyToManyField
多对多关系,定义在哪个类中都可以,如上Book类中;
属性:
related_name: string 与ForeignKey相同
db_table:string 需要建立关联表的表名
db_constraint: 同上 - OneToOneField
一对一关系,定义在哪个类中都可以,如书籍和编号;
属性:
on_delete 同ForeignKey
to_field 同ForeignKey
持久操作
Model.save()
这个方法可以用来插入一条新的数据,也可以用来更新一条数据。如果这个数据在之前数据库中存在了,就只是调用sql的update语句。如果这条数据是新的,就会调用sql的insert语句。示例代码如下:
class UpdateArticle(View):
def get(self,request):
# 批量修改
# UPDATE hello_article SET status=3 WHERE status=2
# Article.objects.filter(status=2).update(status=3)
# 单个修改
# 实际上save方法如果当前实例已经存在于数据库中,它就会当作一个update操作
# Article.objects.filter(id=7).update(status=4)
article = Article.objects.get(pk=8) #取出pk=7的对象,然后修改其状态,再保存
article.status = 0
article.save()
#更新之后在查询
articleAll = Article.objects.all()
return render(request, 'displayArticle.html', locals())
注意:save操作不止是更新修改的字段,而是会将所有的字段全部更新一遍,不管有没有修改。当你的所有操作都是串行,没有什么并发同时操作同一个model的时候,这样的处理方式,一般不会给你带来任何麻烦。但是并行的时候可能会有影响。
Django后面在save方法里面新增加了一个update_fields参数。这样就可以只修改特定字段了:
user.name = name
user.save(update_fields=['name'])
这样便有效避免了并行save产生的数据冲突。
检索对象
- get(**kwargs)方法:查询单个数据,只会返回一个对象,如果所有条件都不满足或者是满足条件的有多个,将抛出一个异常。
article = Article.objects.get(pk=1) #在django 的ORM查询中,数据库的主键可以用PK代替, 官方推荐使用pk
article = Article.objects.get(id=1)#等同于select * from hello_article where id=1;
- all() 获取所有
articleAll = Article.objects.all()
- filter(**kwargs)方法:根据参数提供的提取条件,获取一个过滤后的QuerySet。
Article.objects.filter(status = 0)
- exclude(**kwargs)方法:根据参数提供的条件,排除符合条件的数据,返回一个QuerySet对象。
Article.objects.exclude(status = 0)
- order_by(*args):根据给定的参数进行排序.
#正序:
Book .objects.filter(headline=u'标题').order_by('pub_date')
#倒序,字段前面加-
Book .objects.filter(headline=u'标题').order_by('-pub_date')
- values()方法:将返回来的QuerySet中的Model转换为字典
#, ]>
cgrade = Classesgrade.objects.all()
#), 'create_time': datetime.datetime(2018, 4, 7, 4, 44, 56, 181269,
cninfo=), u'number_id': 1L, u'id': 1L, 'name': u'django\u6846\u67b6\u73ed'},
{'update_time': datetime.datetime(2018, 4, 7, 4, 44, 56, 405850, cninfo=),
'create_time': datetime.datetime(2018, 4, 7, 4, 44, 56, 405816, cninfo=),
u'number_id': 2L, u'id': 2L, 'name': u'django\u6846\u67b6\u73ed'}]>
cgrade.values()
- count()方法:将返回当前查询到的数据的总数,这个比length方法更有效
Book .objects.count()
- latest(field_name=None)方法:根据提供的参数field_name来进行排序,field_name这个参数必须是时间字段,然后提取离现在最近的一条数据
Book .objects.latest('pub_date')
- earliest()方法:用法和latest一样,只是这个是获取最久远的一个。
Book .objects.latest('pub_date')
- first()方法:获取查询到的数据的第一条数据。如果用了order_by,那么将获取排序后的第一条。如果没有用order_by,那么将根据id进行默认排序。
Book .objects.first()
- last()方法:用法和first一样,只不过是获取的是最后一条的数据。
Book .objects.last()
- update(**kwargs):更新数据方法,这个方法可以对查询出来的QuerySet里面的所有元素进行更新,并且更新参数的个数也是不限的。另外要注意的是,因为get方法返回的不是QuerySet对象,因此使用get方法提取出来的数据不能使用update方法。出于这种情况,建议应该使用filter(pk=xx)来替代get(pk=xxx)方法。并且,使用get出来的模型,修改数据后再save,会更新所有的数据,比update的效率更低。
Book .objects.filter(id=1).update(headline="大标题")
- delete()方法:删除QuerySet中的模型。
Book .objects.filter(id=1).delete()
查找对象的条件
查找对象的条件的意思是传给以上方法的一些参数。比如name__contains=’abc’这个就代表name这个字段包含了abc的意思,相当于是SQL语句中的where语句后面的条件,语法为字段名__规则,以下将对这些规则进行说明:
- exact:相当于等于号
Book .objects.filter(headline__exact=u'大标题')
或
Book .objects.filter(headline=u'大标题')
- iexact:跟exact,只是忽略大小写的匹配。
Book .objects.filter(headline__iexact=u'大标题')
- contains:字符数据中包含等号后面的数据。
Book .objects.filter(headline__contains=u'标题')
- icontains:跟contains,唯一不同是忽略大小写。
Book .objects.filter(headline__icontains=u'标题')
- in:判断字符的数据是否处在一个给定的列表中,如果在,则提取出来。
Book .objects.filter(id__in=[1, 2, 3])
- gt:大于。
Book .objects.filter(id__gt=1)
- gte:大于等于。
Book .objects.filter(id__gte=1)
- lt:小于。
Book .objects.filter(id__lt=10)
- lte:小于等于。
Book.objects.filter(id__lte=10)
- startswith:以什么开始。
Book .objects.filter(headline__startswith='title')
- istartswith:同startswith,忽略大小写。
Book .objects.filter(headline__istartswith='title')
- endswith:同startswith,以什么结尾。
Book .objects.filter(headline__iendswith='le')
- iendswith:同istartswith,以什么结尾忽略大小写。
Book .objects.filter(headline__iendswith='le')
- range:区间查询。
import datetime
start_date = datetime.date(2005, 1, 1)
end_date = datetime.date(2018, 1, 1)
Book .objects.filter(pub_date__range=(start_date, end_date))
- isnull:判断是否是空。
Book .objects.filter(pub_date__isnull=True) zz ..,. MJ HM
- 切片:对查找出来的数据进行切片,跟用数组是一样的。
Book.objects.all()[:2]
*ps:负值的操作,是无法进行。切片可以用来实现翻页显示内容,比如每一页显示10条内容可以利用切片,第page页
cnumber = Classesnumber.objects.all() #获取Classesnumber的Queryset集
cn_counts = cnumber.count() #总记录数
page_count = 4 #每页显示记录
#求出分多少页
for page in range((cn_counts / page_count + cn_counts % page_count)):
#利用for遍历出每一页的记录数据
for pagenum in (cnumber[page*page_count:page*page_count + page_count]):
print(pagenum.classgrade_number)
外键操作
一对一
- 访问
在建立关联属性的类里面直接.关联属性即可
book = Book.objects.get(pk=1) #先获取从表的对象,Book为从表
book.number #得到book主键为1的对应Number对象主表
- 增加
book = Book.objects.get(pk=1)
book.number = number #获取Number主类的对象,再赋给book中的关联属性
book.save() #再save保存
- 反查
number = Number.objects.get(pk=1) #Number为主类,Book为从类
number.book #查询编号对应的书籍
多对一
- 访问
访问外键:Reply(多)的对象要访问他所持有的book(一)对象
reply = Reply.objects.get(pk=1) #先获取多类(子表)对象
reply.book # 字表
反查(一查多,主查从)
外键反向访问:如果Book对象想要访问所有引用了他的Reply对象,因为没有外键属性,不能采用“.”方式访问,可以通过“模型名_set“进行访问。如果模型I有一个ForeignKey,那么该ForeignKey 所指的模型II实例可以通过一个管理器回前面有ForeignKey的模型I的所有实例。默认情况下,这个管理器的名字为foo_set,其中foo 是源模型的小写名称。默认是以
子表小写名称_set()来表示(上面默认以b_set访问),
可以在从表定义时设置related_name 参数来覆盖foo_set 的名称。通过主表来查询子表信息用到反向查询(返回的是管理器,需要all之类返回QuerySet),
# 本身Number对象是没有book属性,django提供的一个反查机制
# 如果设置related_name, 我们就通过related_name反查
# 如果没有设置, django默认设置的是反查class的小写名字
# related_name 可以当成反查所用的别名
book = Book.objects.get(pk=1)
book.reply_set.all()
#还可以进行查询
book = Book.objects.get(pk=1)
book.reply_set.filter(content__contains=’I love’).all()
- 添加
# 多对一创建的对象,它是默认没有加载外键的,只有当你引用时,它才会加载
reply = Reply.objects.get(pk=1) #首先主表要有数据,从表才能与之相对应
reply.book = book #book是从主类获取的对象,此处省略
reply.save() #再保存
# 反向操作
多对多
- 访问
多对多访问:跟外键访问一样,“模型名_set“进行反向访问。
Book .authors 等于同Book .objects.filter(reply_id=Reply.id).all()
book = Book.objects.get(pk=1)
book.authors
反查
“模型名_set“进行反向访问。与多对一类似添加
多对多数据添加需要先保存子表对象,然后再add进行添加主类对象
book = Book(headline="标题",number=number)
book.save()
book.authors.add(author)
book.authors.add(author1)
book.save()
- 删除
book.authors.remove(author)
book.save()
处理关联对象方法
add(obj1, obj2, ...) 添加的已经存在数据库的数据
添加一指定的模型对象到关联的对象集中。
d = Department.objects.get(pk=1)
s = Student.objects.get(pk=1)
d.student_set.add(s) # 学院d添加学生s
create(**kwargs) 添加不存在的数据 ,将数据直接存入数据库
创建一个新的对象,将它保存并放在关联的对象集返回新创建的对象。
d.student_set.create(name='小明') # 创建一个叫小明的学生,并将他添加到学院d中
remove(obj1, obj2, ...)
从关联的对象集中删除指定的模型对象。删除的是关系表中的数据
d.student_set.remove(s) # 从学院d中删除学生s
clear() 从关联的对象集中删除所有的对象
d.student_set.clear() # 清除学院d中所有学生
注意对于所有类型的关联字段,add()、create()、remove()和clear()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法
多表查询
跨关联关系的查询
Django 提供一种强大而又直观的方式来“处理”查询中的关联关系,它在后台自动帮你处理JOIN。 若要跨越关联关系,只需使用关联的模型字段的名称,并使用双下划线分隔,直至你想要的字段:
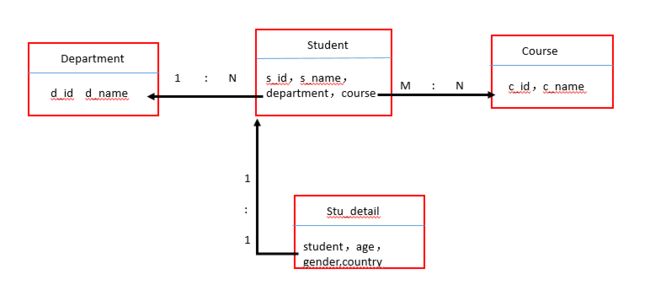
举例:
# 查询学院名字为‘软件’的学生的信息
Student.objects.filter(department__d_name='软件')
#这种跨越可以是任意的深度。
#查询学生名字中包含‘xiao’的学生的学院信息
Department.objects.filter(student__s_name__contains='xiao')
# 查询学号为1的学生所有的课程
Course.objects.filter(student__s_id=1)
# 查询报了课程1的所有的学生
Student.objects.filter(course__c_id=1)
# 查询报了'python'课程的的学生的所属学院的信息
Department.objects.filter(student__course__c_name='python') #三个表关联查询
总结:
- Object对象获取某一列值(或者说是获取某个属性)的时候,使用点来获取。我们跨表查询时,也是使用点来获取。或者用_set反查询,_set:提供了对象访问相关联表数据的方法。但这种方法只能是相关类访问定义了关系的类(主键类访问外键类)。
- QuerySet查询集做跨表查询时,使用双下划线"",:两个下划线可以生成连接查询,查询关联的字段信息,可以跨表关联查询,只要一层接一层,可以从头查到尾。
聚合操作
使用aggregate方法进行数据库的聚合操作, 使用QuerySet.aggregate 代表需要使用聚合操作,它返回的是一个字典:
- 引入对应的聚合函数
from django.db.models import Avg, Max, Min, Count, Sum - Avg, 平均数
#查询当前作者的平均年龄
Author.objects.aggregate(Avg("age"))
- Max 最大数
#取最大年龄的作者
Author.objects.aggregate(Max("age"))
- Min 最小数
#取最小年龄的作业
Author.objects.aggregate(Max("age"))
- Count 统计行数
#统计有多少个作者
Author.objects.aggregate(Count("id"))
#如果需要去重
Author.objects.aggregate(Count("age", distinct=True))
- Sum 统计和
#获取所有作者的年龄总和
Author.objects.aggregate(Sum("age"))
- 多个聚合结果
Author.objects.aggregate(Sum("age"),Min("age"), Max("age"))
- 自定义名称聚合字段别名, 你的参数名就是你需要自定义的聚合结果名称
Author.objects.aggregate(avg_age=Avg("age")) >>>{avg_age:平均年龄值}
- 使用annotate进行聚合查询
1 它与aggregate类似,但是aggregate的结果一定只有一个值,且aggregate执行后就是最终结果。
2 aggregate返回的是一个字典,annotate返回的是一个QuerySet,可以继续进行查询。
3 annotate的聚合结果是针对每行数据的,而不是整个查询结果。
在博客常见侧边栏有分类列表,显示博客已有的全部文章分类。现在想在分类名后显示该分类下有多少篇文章,该怎么做呢?这个就可以用到annotate函数,先按类名进行分组,然后再统计每个组分别为多少数量即可。 - 使用annotate进行集合查询
#统计每本书的作者有多少
Book.objects.annotate(Count("anthors"))
#统计每个年龄分别有多少人
# values 就等同于group by,返回的是一个字典
# values_list 就等同于group by,, 返回的是一个元祖
Author.objects.values("age").annotate(Count("id"))
事务
如果需要支持事务,mysql引擎必须是InnoDB类型。
- 引入django处理事务的包
from django.db import transaction
- 使用装饰器事务控制
ps: 使用装饰器的事务必须是view视图函数
ps: 通用视图类还未提供装饰器事务控制器
# 这个装饰器不能在通用View视图中使用
# 现在django还只提供了在view函数中使用的装饰器
@transaction.atomic
def model_study(request):
# 使用事务装饰器以后
# 整个view函数里面的数据库操作
# 要么全部成功
# 要么全部失败
# 下面的代码在一个事务中执行,一但出现异常,整个函数中所有的数据库操作全部都会回滚
book = Book.objects.create(headline="事务操作1")
author = Author.objects.create(name="kevin", email="[email protected]", age=28)
book.authors.add(author)
book.save()
# assert not book.headline.find("操作") >= 0, "这是敏感关键字"
return render(request, "model_study/model_study.html")
- 使用上下文管理器的方式
from django.db import transaction
class ViewClass(View)
def get(self, request)
# 下面的代码在自动提交模式下执行(Django的默认模式)
with transaction.atomic(): # with中的代码,全部都会保持原子性
# 下面的代码在一个事务中执行,一但出现异常,整个with函数内部的数据库操作都会回滚
book = Book.objects.create(headline="事务操作3")
author = Author.objects.create(name="kevin", email="[email protected]", age=28)
book.authors.add(author)
book.save()
assert 1==1
# raise Exception, "这里出现了一个bug"
ps: with 内部最好不要使用try...catch...模块,否则可能会影响django的事务异常判断。
课后练习
1、创建一个班级的模型(名称、班号(一对一外键),创建时间(自动添加),修改时间(自动更新))
2、创建一个班号的模型(号码)
3、创建一个学生的模型(名称、班级(多对一外键 ),老师(多对多),年龄,性别)
4、创建一个老师的模型( 名称,年龄,性别,班级(多对一外键))
- app应用models.py中建立模型类
#班号模型
class Classesnumber(models.Model): #类名代表了数据库表名,且继承了models.Model,类里面的字段代表数据表中的字段(name)
# 属性=models.字段类型(选项)
# 如果没有添加主键,django会默认添加一个ID的主键
classgrade_number = models.CharField(u'号码',max_length=20) #备注也可用verbose_name
class Meta: #模型元选项
db_table = u'classnumber' #在数据库中的表名,否则Django自动生成为app名字_类名
managed = True
# 数据的默认排序, 如果需要倒序,则添加"-"号即可,这里可以按多个排序
# 多个排序会按你的数组列表顺序进行排序
ordering = ['id','classgrade_number']
# 描述,当查询结果是一条记录时,它的描叙
verbose_name = u'班号' #对象的描述
# 如果查询结果为多个记录,则返回verbose_name_plural的描叙
verbose_name_plural = u'班号集' #复数时的描述
#班级模型
class Classesgrade(models.Model):
name = models.CharField(u'名称',max_length=20)
create_time = models.DateTimeField(u'创建时间',auto_now_add=True) #auto_now_add只有第一次才会生效
update_time = models.DateTimeField(verbose_name= u'修改时间',auto_now=True)#auto_now每一次修改的动作,都会更新一个时间
#与班级一对一关系,关联属性,Django会自动建立个属性_id字段
number = models.OneToOneField(Classesnumber)
class Meta:
db_table = 'classesgrade'
managed = True
#老师模型
class Teacher(models.Model):
name = models.CharField(u'姓名',max_length=20)
age = models.IntegerField(u'年龄')
sex = models.CharField(u'性别',max_length=2)
#老师与班级多对一,关联属性在多方定义
#db_constraint:bool 是否建立外键约束,
#to_field:string 关联到的关联对象的字段名称。默认地,Django 使用关联对象的主键。
#CASCADE:级联删除,如果删除,相关联的那个也会删除
classesno = models.ForeignKey(Classesgrade,db_constraint = True,to_field='id',on_delete = models.CASCADE)
class Meta:
db_table = 'teacher'
managed = True
#学生
class Student(models.Model):
name = models.CharField(u'姓名',max_length=20)
age = models.IntegerField(u'年龄')
sex = models.CharField(u'性别',max_length=2)
classesno = models.ForeignKey(Classesgrade,db_constraint = True,to_field='id',on_delete = models.CASCADE)
# 多对多,Django会自动创建中间表
teacher = models.ManyToManyField(Teacher,related_name = 'teacher_set')
class Meta:
db_table = 'student'
managed = True
- 添加数据
班号(“001”,“002“)
老师 ("k", “28”, "男",“django框架班001”)
老师 ("山", “28”, "男",“django框架班001” )
老师 ("不", “28”, "男",“django框架班002” )
班级(“django框架班” ,“班号(001) ”,“自动创建”, “自动更新”)
班级(“django框架班” ,“班号(002) ”,“自动创建”, “自动更新”)
学生(“学生1”,20,“男”,“001 ”,[“k老师”,“山”])
学生(“学生2”,22,“女”,“002 ”,["山", “不”])
学生(“学生3”,21,“男”,“001 ”, ["k", “不”])
class AddInfor(View):
def get(self,request):
#添加班号数据
#可以用save和create方式
cnumber1 = Classesnumber.objects.create(classgrade_number = '001')
cnumber2 = Classesnumber.objects.create(classgrade_number = '002')
#添加班级数据:
#如果存在外键关联,主表必须首先得先有数据,一对一关系的添加数据
#一对一赋值必须保持一个对象只对应一个外键
cnumber3 = Classesnumber.objects.get(pk=1) #1对1,先取出主表的pk=1对象
Classesgrade.objects.create(name = u'django框架班',number = cnumber3 ) #再赋给外键
cnumber4 = Classesnumber.objects.get(pk=2)
cgrade = Classesgrade(name = u'django框架班',number = cnumber4)
cgrade.save()
# 添加老师数据:
#获取班级对象
cgrade1 = Classesgrade.objects.get(pk=1) #1对多,先取出主表的pk=1对象
cgrade2 = Classesgrade.objects.get(pk=2) #1对多,先取出主表的pk=2对象
# # 通过获取一端对象,则这里要用类属性而不是表字段的名字
Teacher.objects.create(name = u'k',age = 28,sex = u'男',classesno = cgrade1)
Teacher.objects.create(name = u'山',age = 28,sex = u'男',classesno = cgrade1)
Teacher(name = u'不',age = 28,sex = u'男',classesno = cgrade2).save()
#添加学生数据views.py中:
#与班级,多对一外键
stu1 = Student()
stu1.name = u'学生1'
stu1.age = 20
stu1.sex = u'男'
stu1.classesno = cgrade1
stu1.save()
stu2 = Student(name = u'学生2',age = 22,sex = u'女',classesno = cgrade2)
stu2.save()
stu3 = Student.objects.create(name = u'学生3',age = 21,sex = u'男',classesno = cgrade1)
#与老师多对多
#多对多的添加,需要使用add方法
#多对多的添加,必须主类必须在数据库已经存在
tch1 = Teacher.objects.get(name__exact= u'k')
tch2 = Teacher.objects.get(name__exact= u'山')
tch3 = Teacher.objects.get(name__exact= u'不')
stu1.teacher.add(tch1)
stu1.teacher.add(tch2)
stu1.save()
stu2.teacher.add(tch2,tch3)
stu2.save()
stu3.teacher.add(tch1,tch3)
stu3.save()
return render(request,'result.html',locals())
- 查询数据views.py中
#app应用urls.py中
urlpatterns = [
url(r'^register/$', views.Register.as_view(),name='register'),
url(r'^login/$', views.Login.as_view(),name = 'login'),
url(r'^index/$', views.Index.as_view(),name='index'),
url(r'^logout/$', views.Logout.as_view(),name='logout')
]
class QueryInfor(View):
def get(self,request):
#查询性别为男的学生
stu_boys = Student.objects.filter(sex__exact = u'男')
#查询年龄大于20岁的学生
stu_20 = Student.objects.filter(age__gt = 20)
#获取所有学生、并按年龄排序
stu_all = Student.objects.all().order_by('age')
#获取所有学生并排除性别为女的学生
stu_nogirls = Student.objects.exclude(sex = u'女')
#获取学生总数
stu_sum = Student.objects.count()
#获取最后创建的班级
last_grade = Classesgrade.objects.latest('create_time')
cgrade1 = Classesgrade.objects.get(pk = 1)
cgrade2 = Classesgrade.objects.get(pk = 2)
#查询班级下老师
#本身班级对象是没有老师属性,django提供的一个反查机制
# 如果设置related_name, 我们就通过related_name反查
# 如果没有设置, django默认设置的是反查class的小写名字
# related_name 可以当成反查所用的别名
tchs1 = cgrade1.teacher_set.all() #xxx_set 实际返回的是一个空值,如需访问它们,则要进行一个查询QuerySet操作
tchs2 = cgrade2.teacher_set.all()
#查询班级下学生
stu1 = cgrade1.student_set.all()
stu2 = cgrade2.student_set.all()
#查询一个班级的编号,1对1 反查
cgradeno1 =cgrade1.number #cgrade1.number是个
cgradeno2 = cgrade2.number
#查询年龄最大的学生
sage = Student.objects.aggregate(max_age = Max('age')) #以字典形式返回年龄最大值,{'age__max': 22}
maxage_stu = Student.objects.filter(age = sage['max_age'])
#filter(**kwargs)方法:根据参数提供的提取条件,获取一个过滤后的QuerySet。所以在前端不能直接获取对象的方式来,需要遍历来获取,即使只有一个;
#查询年龄最小的学生
sage = Student.objects.aggregate(Min('age')) #以字典形式返回年龄最大值,{'age__max': 22}
minage_stu = Student.objects.filter(age = sage[sage.keys()[0]]) #sage.keys()[0]获取字典的键
#avgage_stu查询学生的平均年龄
sage = Student.objects.aggregate(Avg('age'))
for key,value in sage.items():
keys = key
age = value
#查询每个年龄的学生数量,按年龄进行分组,然后统计数量select age,count(age) from student group by age;
agestucount = Student.objects.values('age').annotate(Count('id')) #annotate返回的是一个QuerySet,可以继续进行查询
return render(request,'queryInfor.html',locals())
页面效果
查询信息
1.查询性别为男的学生:
{%for stu_boy in stu_boys%}
姓名:{{stu_boy.name}}
性别:{{stu_boy.sex}}
年龄:{{stu_boy.age}}
班级:{{stu_boy.classesno_id}}
{%endfor%}
2.查询年龄大于20岁的学生:
{%for stu in stu_20%}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{%endfor%}
3.获取所有学生、并按年龄排序:
{%for stu in stu_all%}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{%endfor%}
4.获取所有学生并排除性别为女的学生:
{%for stu in stu_nogirls%}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{%endfor%}
5.获取学生总数:
{{stu_sum}}
6.获取最后创建的班级:
名称:{{last_grade.name}}
创建时间:{{last_grade.create_time}}
更新时间:{{last_grade.update_time}}
对应班号:{{last_grade.number_id}}
11.查询一个班级下有那些老师:
{{cgrade1.name}}第{{cgrade1.number.id}}个班老师:
{%for tch in tchs1%}
姓名:{{tch.name}}
性别:{{tch.sex}}
年龄:{{tch.age}}
班级:{{tch.classesno_id}}
{%endfor%}
{{cgrade2.name}}第{{cgrade2.number_id}}个班老师:
{%for tch in tchs2%}
姓名:{{tch.name}}
性别:{{tch.sex}}
年龄:{{tch.age}}
班级:{{tch.classesno.id}}
{%endfor%}
22.查询一个班级下有那些学生:
{{cgrade1.name}}第{{cgrade1.number.id}}个班学生:
{%for stu in stu1%}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{%endfor%}
{{cgrade2.name}}第{{cgrade2.number_id}}个班学生:
{%for stu in stu2%}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{%endfor%}
33.查询一个班级的编号:
第{{cgrade1.number_id}}个班编号:{{cgradeno1.classgrade_number}}
第{{cgrade2.number_id}}个班编号:{{cgrade2.number.classgrade_number}}
44、查询年纪最大的学生
{% for stu in maxage_stu %}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{% endfor %}
55、查询年纪最小的学生
{% for stu in minage_stu %}
姓名:{{stu.name}}
性别:{{stu.sex}}
年龄:{{stu.age}}
班级:{{stu.classesno_id}}
{% endfor %}
66、查询学生的平均年龄
平均{{keys}}:{{value}}z
77、查询每个年龄的学生数量
{% for dic in agestucount%}
{% for age,countstu in dic.items %}
{{age}}:{{countstu}}
{% endfor %}
;
{% endfor %}