- JVM、JRE和 JDK:理解Java开发的三大核心组件
Y雨何时停T
Javajava
Java是一门跨平台的编程语言,它的成功离不开背后强大的运行环境与开发工具的支持。在Java的生态中,JVM(Java虚拟机)、JRE(Java运行时环境)和JDK(Java开发工具包)是三个至关重要的核心组件。本文将探讨JVM、JDK和JRE的区别,帮助你更好地理解Java的运行机制。1.JVM:Java虚拟机(JavaVirtualMachine)什么是JVM?JVM,即Java虚拟机,是Ja
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
- hbase介绍
CrazyL-
云计算+大数据hbase
hbase是一个分布式的、多版本的、面向列的开源数据库hbase利用hadoophdfs作为其文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写、适用于非结构化数据存储的数据库系统hbase利用hadoopmapreduce来处理hbase、中的海量数据hbase利用zookeeper作为分布式系统服务特点:数据量大:一个表可以有上亿行,上百万列(列多时,插入变慢)面向列:面向列(族)的
- Spark集群的三种模式
MelodyYN
#Sparksparkhadoopbigdata
文章目录1、Spark的由来1.1Hadoop的发展1.2MapReduce与Spark对比2、Spark内置模块3、Spark运行模式3.1Standalone模式部署配置历史服务器配置高可用运行模式3.2Yarn模式安装部署配置历史服务器运行模式4、WordCount案例1、Spark的由来定义:Hadoop主要解决,海量数据的存储和海量数据的分析计算。Spark是一种基于内存的快速、通用、可
- HBase介绍
mingyu1016
数据库
概述HBase是一个分布式的、面向列的开源数据库,源于google的一篇论文《bigtable:一个结构化数据的分布式存储系统》。HBase是GoogleBigtable的开源实现,它利用HadoopHDFS作为其文件存储系统,利用HadoopMapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务。HBase的表结构HBase以表的形式存储数据。表有行和列组成。列划分为
- webpack 之 tapable 学习
weixin_34008784
webpackjavascriptViewUI
前言webpack大家应该都耳熟能详了。个人感觉,webpack的本质就是让一堆的Loader和Plugin在webpack的可支配范围内,有序可控的执行,最终生成一堆可在浏览器中执行的code和一些状态信息。而这些Loader和Plugin,有用户自定义的,也有webpack自己内部定义的。Loader的运行机制,不是这篇文章讲述的内容,有需要的朋友,可以看下我之前的这篇文章:webpack之l
- Hadoop windows intelij 跑 MR WordCount
piziyang12138
一、软件环境我使用的软件版本如下:IntellijIdea2017.1Maven3.3.9Hadoop分布式环境二、创建maven工程打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建java工程即可,不用勾选Creatfromarchetype,如果想创建web工程或者使用骨架可以勾选)image.png设置GroupId和Artif
- ArcGIS地图切片原理与算法
数智侠
GIS
ArcGIS地图切图系列之(一)切片原理解析点击打开链接ArcGIS地图切图系列之(二)JAVA实现点击打开链接ArcGIS地图切图系列之(三)MapReduce实现点击打开链接
- 设计模式-分离接口(Separated Interface)
workflower
设计方法设计模式课程设计设计规范开发语言软件需求
在一个包中定义接口,而在另一个包中实现这个接口,两个包是分离的。背景为了减少部件之间的耦合程度改进设计质量,可以将类分组并组织成包,并限定包之间的依赖关系。但有时可能需要调用与包之间一般性依赖关系有冲突的方法,此时可以在一个包中定义接口,在另一个包中实现它。运行机制核心思想利用了:实现类对接口存在依赖关系,反之不然。其他包可以只依赖于接口包,而与实现包没有依赖关系。可以采用独立的包将接口与实现链接
- 第 2-2 课:深入探究底层原理,应用更加得心应手
Java大联盟
案例上手Spring全家桶SpringSpringBootSpringCloudSpringMVCSpringSpringBootSpring
前言上一讲我们学习了SpringMVC框架的使用,为了更好地理解这个框架,本讲来仿写一个SpringMVC框架,用到的技术比较简单,只需要XML解析+反射就可以完成,不需要JDK动态代理。自己手写框架的前提是必须理解框架的底层原理和运行机制,因此我们还是先来回顾一下SpringMVC的实现原理。SpringMVC实现原理SpringMVC的核心组件和工作流程的内容具体可以参考第2-1讲的内容,通过
- Android 性能优化实战:打造流畅体验
斯陀含
android性能优化
Android性能优化实战:打造流畅体验导言:Android应用的性能直接影响用户体验,流畅、快速、高效的应用才能吸引用户并留住用户。优化代码性能是提升用户体验的关键,而这需要我们深入理解Android系统的运行机制和性能瓶颈,并采取针对性的优化策略。本教程将带领你深入学习Android性能优化,涵盖代码优化、布局优化、渲染优化、内存优化、网络优化等多个方面,并提供丰富的实例和代码示例,帮助你快速
- android之ActivityThread
追梦的鱼儿
androidActivityThread
目录主要职责关键组件工作流程ActivityThread是Android框架中的一个核心类,负责管理应用程序的主线程(UI线程)以及应用程序的生命周期事件。了解它的工作原理对于理解Android应用程序的运行机制是非常有帮助的。主要职责管理主线程:ActivityThread是应用程序的主线程,负责处理所有的UI操作。生命周期管理:处理Activity、Service、BroadcastRecei
- 数据中台建设方案-基于大数据平台(下)
FRDATA1550333
大数据数据库架构数据库开发数据库
数据中台建设方案-基于大数据平台(下)1数据中台建设方案1.1总体建设方案1.2大数据集成平台1.3大数据计算平台1.3.1数据计算层建设计算层技术含量最高,最为活跃,发展也最为迅速。计算层主要实现各类数据的加工、处理和计算,为上层应用提供良好和充分的数据支持。大数据基础平台技术能力的高低,主要依赖于该层组件的发展。本建设方案满足甲方对于数据计算层建设的基本要求:利用了MapReduce、Spar
- MIT6.824 课程-MapReduce
余为民同志
6.824mapreduce分布式6.824
MapReduce:在大型集群上简化数据处理概要MapReduce是一种编程模型,它是一种用于处理和生成大型数据集的实现。用户通过指定一个用来处理键值对(Key/Value)的map函数来生成一个中间键值对集合。然后,再指定一个reduce函数,它用来合并所有的具有相同中间key的中间value。现实生活中有许多任务可以通过该模型进行表达,具体案例会在论文中展现出来。以这种函数式风格编写的程序能够
- 加入原力元宇宙就一定能获得静态收益吗
口碑信息传播者
在数字经济的浪潮中,原力元宇宙以其独特的魅力吸引了众多投资者的目光。然而,关于加入原力元宇宙是否就能获得静态收益的问题,却是一个值得深入探讨的话题。本文将详细分析原力元宇宙的运行机制,以及投资者如何正确理解并参与其中,以期为读者提供一个全面而深入的认识。13分钟视频内容讲明白原力元宇宙创富项目,中国区运营服务对接微信:ForceZen一、原力元宇宙简介原力元宇宙作为一个去中心化的平台,旨在为用户提
- Fiddler 笔记
Queenie的学习笔记
1.Fiddler的原理终端设备(如WEB、APP)发出请求,Fiddler作为中间代理,传给服务器;服务器返回数据,Fiddler拦截后,再传给终端设备核心:代理服务运行机制:本机上监听8888端口的HTTP代理(代理地址是127.0.0.1,端口号8888)2.第一次使用Fiddler,如何配置(1)抓取https请求时,先导入证书:①Fiddler设置:Tools>Options>HTTPS
- Hadoop之mapreduce -- WrodCount案例以及各种概念
lzhlizihang
hadoopmapreduce大数据
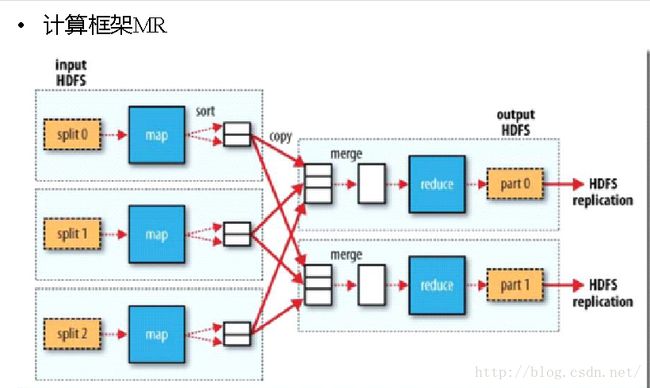
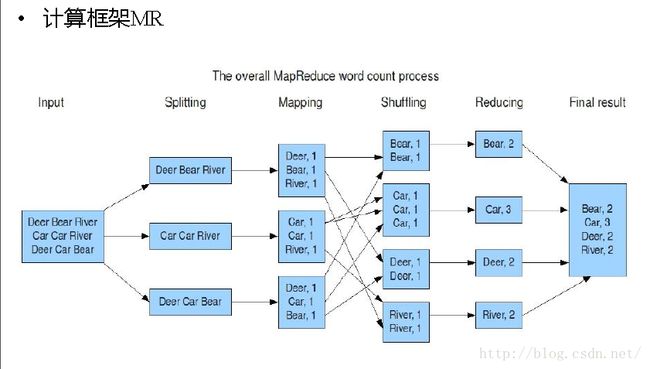
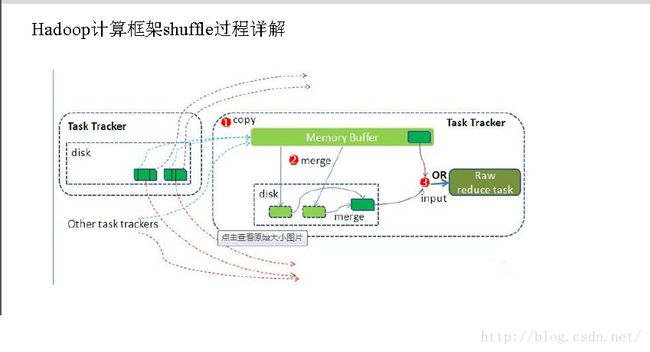
文章目录一、MapReduce的优缺点二、MapReduce案例--WordCount1、导包2、Mapper方法3、Partitioner方法(自定义分区器)4、reducer方法5、driver(main方法)6、Writable(手机流量统计案例的实体类)三、关于片和块1、什么是片,什么是块?2、mapreduce启动多少个MapTask任务?四、MapReduce的原理五、Shuffle过
- Yarn介绍 - 大数据框架
why do not
大数据hadoop
YARN的概述YARN是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序YARN是Hadoop2.x版本中的一个新特性。它的出现其实是为了解决第一代MapReduce编程框架的不足,提高集群环境下的资源利用率,这些资源包括内存,磁盘,网络,IO等。Hadoop2.X版本中重新设计的这个YARN集群
- 浅析大数据Hadoop之YARN架构
haotian1685
python数据清洗人工智能大数据大数据学习深度学习大数据大数据学习YARNhadoop
1.YARN本质上是资源管理系统。YARN提供了资源管理和资源调度等机制1.1原HadoopMapReduce框架对于业界的大数据存储及分布式处理系统来说,Hadoop是耳熟能详的卓越开源分布式文件存储及处理框架,对于Hadoop框架的介绍在此不再累述,读者可参考Hadoop官方简介。使用和学习过老Hadoop框架(0.20.0及之前版本)的同仁应该很熟悉如下的原MapReduce框架图:1.2H
- Hive的优势与使用场景
傲雪凌霜,松柏长青
后端大数据hivehadoop数据仓库
Hive的优势Hive作为一个构建在Hadoop上的数据仓库工具,具有许多优势,特别是在处理大规模数据分析任务时。以下是Hive的主要优势:1.与Hadoop生态系统的紧密集成Hive构建在Hadoop分布式文件系统(HDFS)之上,能够处理海量数据并进行分布式计算。它利用Hadoop的MapReduce或Spark来执行查询,具备高度扩展性,适合大数据处理。2.支持SQL-like查询语言(Hi
- Spark概念知识笔记
kuntoria
最近总结了个人的各项能力,发现在大数据这方面几乎没有涉及,因此想补充这方面的知识,丰富自己的知识体系,大数据生态主要包含:Hadoop和Spark两个部分,Spark作用相当于MapReduceMapReduce和Spark对比如下磁盘由于其物理特性现在,速度提升非常困难,远远跟不上CPU和内存的发展速度。近几十年来,内存的发展一直遵循摩尔定律,价格在下降,内存在增加。现在主流的服务器,几百GB或
- 【Hadoop】- MapReduce & YARN 初体验[9]
星星法术嗲人
hadoophadoopmapreduce
目录提交MapReduce程序至YARN运行1、提交wordcount示例程序1.1、先准备words.txt文件上传到hdfs,文件内容如下:1.2、在hdfs中创建两个文件夹,分别为/input、/output1.3、将创建好的words.txt文件上传到hdfs中/input1.4、提交MapReduce程序至YARN1.5、可通过node1:8088查看1.6、返回我们的服务器,检查输出文
- DAG (directed acyclic graph) 作为大数据执行引擎的优点
joeywen
分布式计算StormSparkStorm杂谈StormsparkDAG
TL;DR-ConceptuallyDAGmodelisastrictgeneralizationofMapReducemodel.DAG-basedsystemslikeSparkandTezthatareawareofthewholeDAGofoperationscandobetterglobaloptimizationsthansystemslikeHadoopMapReducewhicha
- Hadoop组件
静听山水
Hadoophadoop
这张图片展示了Hadoop生态系统的一些主要组件。Hadoop是一个开源的大数据处理框架,由Apache基金会维护。以下是每个组件的简短介绍:HBase:一个分布式、面向列的NoSQL数据库,基于GoogleBigTable的设计理念构建。HBase提供了实时读写访问大量结构化和半结构化数据的能力,非常适合大规模数据存储。Pig:一种高级数据流语言和执行引擎,用于编写MapReduce任务。Pig
- Hadoop-MapReduce机制原理
H.S.T不想卷
大数据hadoopmapreduce大数据
MapReduce机制原理1、MapReduce概述2、MapReduce特点3、MapReduce局限性4、MapTask5、Map阶段步骤:6、Reduce阶段步骤:7、MapReduce阶段图1、MapReduce概述 HadoopMapReduce是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)
- EMR组件部署指南
ivwdcwso
运维EMR大数据开源运维
EMR(ElasticMapReduce)是一个大数据处理和分析平台,包含了多个开源组件。本文将详细介绍如何部署EMR的主要组件,包括:JDK1.8ElasticsearchKafkaFlinkZookeeperHBaseHadoopPhoenixScalaSparkHive准备工作所有操作都在/data目录下进行。首先安装JDK1.8:yuminstalljava-1.8.0-openjdk部署
- hive学习记录
2302_80695227
hive学习hadoop
一、Hive的基本概念定义:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。Hive将HQL(HiveQueryLanguage)转化成MapReduce程序或其他分布式计算引擎(如Tez、Spark)的任务进行计算。数据存储:Hive处理的数据存储在HDFS(HadoopDistributedFileSystem)上。执行引擎:Hive的
- 在MFC中添加用户自定义消息
luckyone906
MFC
消息机制是windows的典型运行机制,在MFC中有很多的消息如WM_BTN**等。但是在有些情况下我们需要自定义一些消息去做一些我们需要的功能,MFC的向导不能帮助我们做到这一点,我们可以通过添加相应的代码去完成这个功能。添加自定义消息操作如下:1.建立MFC工程,如基于对话框的应用程序,Test。2.在资源中添加要处理的消息的值,即在CTestDlg.h中添加如下代码。(因为很多MFC的消息是
- 微信小程序 ---- 生命周期
她说她一如既往的爱我
微信小程序小程序
1.小程序运行机制冷启动与热启动:小程序启动可以分为两种情况,一种是冷启动,一种是热启动冷启动:如果用户首次打开,或小程序销毁后被用户再次打开,此时小程序需要重新加载启动热启动:如果用户已经打开过某小程序,然后在一定时间内再次打开该小程序,此时小程序并未被销毁,只是从后台状态进入前台状态前台以及后台状态:小程序启动后,界面被展示给用户,此时小程序处于「前台」状态。当用户「关闭」小程序时,小程序并没
- 解读Servlet原理篇二---GenericServlet与HttpServlet
周凡杨
javaHttpServlet源理GenericService源码
在上一篇《解读Servlet原理篇一》中提到,要实现javax.servlet.Servlet接口(即写自己的Servlet应用),你可以写一个继承自javax.servlet.GenericServletr的generic Servlet ,也可以写一个继承自java.servlet.http.HttpServlet的HTTP Servlet(这就是为什么我们自定义的Servlet通常是exte
- MySQL性能优化
bijian1013
数据库mysql
性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有:
a.优化查询
b.优化数据库结构
- ThreadPool定时重试
dai_lm
javaThreadPoolthreadtimertimertask
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
- Oracle 查看数据库的连接情况
周凡杨
sqloracle 连接
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
- 类的继承
朱辉辉33
java
类的继承可以提高代码的重用行,减少冗余代码;还能提高代码的扩展性。Java继承的关键字是extends
格式:public class 类名(子类)extends 类名(父类){ }
子类可以继承到父类所有的属性和普通方法,但不能继承构造方法。且子类可以直接使用父类的public和
protected属性,但要使用private属性仍需通过调用。
子类的方法可以重写,但必须和父类的返回值类
- android 悬浮窗特效
肆无忌惮_
android
最近在开发项目的时候需要做一个悬浮层的动画,类似于支付宝掉钱动画。但是区别在于,需求是浮出一个窗口,之后边缩放边位移至屏幕右下角标签处。效果图如下:
一开始考虑用自定义View来做。后来发现开线程让其移动很卡,ListView+动画也没法精确定位到目标点。
后来想利用Dialog的dismiss动画来完成。
自定义一个Dialog后,在styl
- hadoop伪分布式搭建
林鹤霄
hadoop
要修改4个文件 1: vim hadoop-env.sh 第九行 2: vim core-site.xml <configuration> &n
- gdb调试命令
aigo
gdb
原文:http://blog.csdn.net/hanchaoman/article/details/5517362
一、GDB常用命令简介
r run 运行.程序还没有运行前使用 c cuntinue
- Socket编程的HelloWorld实例
alleni123
socket
public class Client
{
public static void main(String[] args)
{
Client c=new Client();
c.receiveMessage();
}
public void receiveMessage(){
Socket s=null;
BufferedRea
- 线程同步和异步
百合不是茶
线程同步异步
多线程和同步 : 如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法
多线程和异步:多线程可以做不同的事情,涉及到线程通知
&
- JSP中文乱码分析
bijian1013
javajsp中文乱码
在JSP的开发过程中,经常出现中文乱码的问题。
首先了解一下Java中文问题的由来:
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,
- js实现页面跳转重定向的几种方式
bijian1013
JavaScript重定向
js实现页面跳转重定向有如下几种方式:
一.window.location.href
<script language="javascript"type="text/javascript">
window.location.href="http://www.baidu.c
- 【Struts2三】Struts2 Action转发类型
bit1129
struts2
在【Struts2一】 Struts Hello World http://bit1129.iteye.com/blog/2109365中配置了一个简单的Action,配置如下
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configurat
- 【HBase十一】Java API操作HBase
bit1129
hbase
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
- nginx gzip
ronin47
nginx gzip
Nginx GZip 压缩
Nginx GZip 模块文档详见:http://wiki.nginx.org/HttpGzipModule
常用配置片段如下:
gzip on; gzip_comp_level 2; # 压缩比例,比例越大,压缩时间越长。默认是1 gzip_types text/css text/javascript; # 哪些文件可以被压缩 gzip_disable &q
- java-7.微软亚院之编程判断俩个链表是否相交 给出俩个单向链表的头指针,比如 h1 , h2 ,判断这俩个链表是否相交
bylijinnan
java
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
- Spring源码学习-JdbcTemplate batchUpdate批量操作
bylijinnan
javaspring
Spring JdbcTemplate的batch操作最后还是利用了JDBC提供的方法,Spring只是做了一下改造和封装
JDBC的batch操作:
String sql = "INSERT INTO CUSTOMER " +
"(CUST_ID, NAME, AGE) VALUES (?, ?, ?)";
- [JWFD开源工作流]大规模拓扑矩阵存储结构最新进展
comsci
工作流
生成和创建类已经完成,构造一个100万个元素的矩阵模型,存储空间只有11M大,请大家参考我在博客园上面的文档"构造下一代工作流存储结构的尝试",更加相信的设计和代码将陆续推出.........
竞争对手的能力也很强.......,我相信..你们一定能够先于我们推出大规模拓扑扫描和分析系统的....
- base64编码和url编码
cuityang
base64url
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
- web应用集群Session保持
dalan_123
session
关于使用 memcached 或redis 存储 session ,以及使用 terracotta 服务器共享。建议使用 redis,不仅仅因为它可以将缓存的内容持久化,还因为它支持的单个对象比较大,而且数据类型丰富,不只是缓存 session,还可以做其他用途,一举几得啊。1、使用 filter 方法存储这种方法比较推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简
- Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR模式']
dcj3sjt126com
数据库
public function getMinLimit () { $sql = "..."; $result = yii::app()->db->createCo
- solr StatsComponent(聚合统计)
eksliang
solr聚合查询solr stats
StatsComponent
转载请出自出处:http://eksliang.iteye.com/blog/2169134
http://eksliang.iteye.com/ 一、概述
Solr可以利用StatsComponent 实现数据库的聚合统计查询,也就是min、max、avg、count、sum的功能
二、参数
- 百度一道面试题
greemranqq
位运算百度面试寻找奇数算法bitmap 算法
那天看朋友提了一个百度面试的题目:怎么找出{1,1,2,3,3,4,4,4,5,5,5,5} 找出出现次数为奇数的数字.
我这里复制的是原话,当然顺序是不一定的,很多拿到题目第一反应就是用map,当然可以解决,但是效率不高。
还有人觉得应该用算法xxx,我是没想到用啥算法好...!
还有觉得应该先排序...
还有觉
- Spring之在开发中使用SpringJDBC
ihuning
spring
在实际开发中使用SpringJDBC有两种方式:
1. 在Dao中添加属性JdbcTemplate并用Spring注入;
JdbcTemplate类被设计成为线程安全的,所以可以在IOC 容器中声明它的单个实例,并将这个实例注入到所有的 DAO 实例中。JdbcTemplate也利用了Java 1.5 的特定(自动装箱,泛型,可变长度
- JSON API 1.0 核心开发者自述 | 你所不知道的那些技术细节
justjavac
json
2013年5月,Yehuda Katz 完成了JSON API(英文,中文) 技术规范的初稿。事情就发生在 RailsConf 之后,在那次会议上他和 Steve Klabnik 就 JSON 雏形的技术细节相聊甚欢。在沟通单一 Rails 服务器库—— ActiveModel::Serializers 和单一 JavaScript 客户端库——&
- 网站项目建设流程概述
macroli
工作
一.概念
网站项目管理就是根据特定的规范、在预算范围内、按时完成的网站开发任务。
二.需求分析
项目立项
我们接到客户的业务咨询,经过双方不断的接洽和了解,并通过基本的可行性讨论够,初步达成制作协议,这时就需要将项目立项。较好的做法是成立一个专门的项目小组,小组成员包括:项目经理,网页设计,程序员,测试员,编辑/文档等必须人员。项目实行项目经理制。
客户的需求说明书
第一步是需
- AngularJs 三目运算 表达式判断
qiaolevip
每天进步一点点学习永无止境众观千象AngularJS
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {
- Spark算子:统计RDD分区中的元素及数量
superlxw1234
sparkspark算子Spark RDD分区元素
关键字:Spark算子、Spark RDD分区、Spark RDD分区元素数量
Spark RDD是被分区的,在生成RDD时候,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时候,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。
可以利用RDD的mapPartitionsWithInd
- Spring 3.2.x将于2016年12月31日停止支持
wiselyman
Spring 3
Spring 团队公布在2016年12月31日停止对Spring Framework 3.2.x(包含tomcat 6.x)的支持。在此之前spring团队将持续发布3.2.x的维护版本。
请大家及时准备及时升级到Spring
- fis纯前端解决方案fis-pure
zccst
JavaScript
作者:zccst
FIS通过插件扩展可以完美的支持模块化的前端开发方案,我们通过FIS的二次封装能力,封装了一个功能完备的纯前端模块化方案pure。
1,fis-pure的安装
$ fis install -g fis-pure
$ pure -v
0.1.4
2,下载demo到本地
git clone https://github.com/hefangshi/f