二、Kubernetes快速入门
(1)Kubernetes集群的部署方法及部署要点
(2)部署Kubernetes分布式集群
(3)kubectl使用基础
1、简介
kubectl就是API service的客户端程序,通过连接master节点上的API service实现k8s对象、资源的增删改查操作。
对象:node、pod、service、controller(replicaset,deployment,statefulet,daemonset,job,cronjob)
2、子命令
分类
#基本命令
Basic Commands (Beginner:初级):
create :Create a resource from a file or from stdin.
expose :Take a replication controller, service, deployment or pod and expose it as a new Kubernetes Service
run :Run a particular image on the cluster
set :Set specific features on objects
Basic Commands (Intermediate:中级):
explain :Documentation of resources
get :Display one or many resources
edit :Edit a resource on the server
delete :Delete resources by filenames, stdin, resources and names, or by resources and label selector
Deploy Commands(部署命令):
rollout :Manage the rollout of a resource #回滚
scale :Set a new size for a Deployment, ReplicaSet, Replication Controller, or Job #手动改变应用程序的规模
autoscale :Auto-scale a Deployment, ReplicaSet, or ReplicationController #自动改变
Cluster Management Commands(集群管理命令):
certificate :Modify certificate resources. #证书
cluster-info :Display cluster info #集群信息
top :Display Resource (CPU/Memory/Storage) usage.
cordon :Mark node as unschedulable #标记节点不可被调用
uncordon :Mark node as schedulable
drain :Drain node in preparation for maintenance #排干节点
taint :Update the taints on one or more nodes #给节点增加污点
Troubleshooting and Debugging Commands(故障排除和调试命令):
describe :Show details of a specific resource or group of resources #描述资源的详细信息
logs :Print the logs for a container in a pod
attach :Attach to a running container
exec :Execute a command in a container
port-forward :Forward one or more local ports to a pod #端口转发
proxy :Run a proxy to the Kubernetes API server
cp :Copy files and directories to and from containers.
auth :Inspect authorization
Advanced Commands(高级命令):
apply :Apply a configuration to a resource by filename or stdin
patch :Update field(s) of a resource using strategic merge patch
replace :Replace a resource by filename or stdin
wait :Experimental: Wait for a specific condition on one or many resources.
convert :Convert config files between different API versions
Settings Commands(设置命令):
label :Update the labels on a resource #标签,有长度限制
annotate :Update the annotations on a resource #注解
completion :Output shell completion code for the specified shell (bash or zsh) #命令补全
Other Commands:
alpha :Commands for features in alpha
api-resources :Print the supported API resources on the server
api-versions :Print the supported API versions on the server, in the form of "group/version"
config :Modify kubeconfig files
plugin :Provides utilities for interacting with plugins.
version :Print the client and server version information
Usage:
kubectl [flags] [options]
3、创建Pod
创建一个控制器名为nginx-deploy,镜像版本为nginx:1.14-alpine的Pod,暴露端口80,副本为1
[root@master ~]# kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=1
![]()
如下图,此时可以看出创建成功了,而且在node02节点上,网段是10.244.2.0/24,而node01节点的网段是10.244.1.0/24。

可通过node01节点进行访问试试,而10.244.2.2是pod地址,只能在k8s集群中内部才能访问。
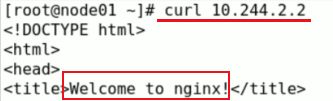
Pod的客户端有两类:其他Pod和集群外的客户端。
现在我们把nginx-deploy-5b595999-2q6j5删除,然后控制器会自动创建一个新的Pod,如下图:

而此时Pod的ip为10.244.1.2,因此需要给Pod一个固定端点来进行访问,而这个固定端点是有servcie创建的
![]()
service的类型有:ClusterIP、NodePort、LoadBalancer、ExternalName。默认是ClusterIP,意思是这个service只有一个service IP,只能在集群内被各Pod客户端访问,而不能被集群外部的客户端访问。
创建service命令:kubectl expose deployment(控制器类型)nginx-deploy(控制器名称) --name 服务名 --port=service端口 --target-port=Pod的端口(即容器端口)
![]()
这样就可以通过固定的service的IP(10.98.39.54)来访问nginx了

不仅可以通过访问service的ip来访问Pod,也可以通过service的服务名来访问,前提是Pod客户端需要能解析这个服务名,解析时需要依赖Core-dns服务。而物理机上的解析文件/etc/resolv.conf中的解析的IP不是Core-dns,可以通过master节点查看,命令为:kubectl get pods -n kube-system -o wide。如下图:

而coredns也有服务名,叫kube-dns,如下图:

如果从master节点上创建一个Pod客户端来访问其他Pod,它的dns服务直接指定到kube-dns的IP上。

因此在各个Pod客户端之外解析的时候要加上搜索域,例如,在clinet这个Pod之外的master节点上解析就需要加上搜索域:

此时可以将这个nginx的Pod删除,当控制器再次自动创建时,Pod的ip已经变为10.244.1.3,然后再次访问servic的ip和服务名都可以访问得到。

通过service的ip和服务名访问Pod,不管Pod是如何变化,它都是根据service的标签选择器来判断的

如何验证,我们可以在master节点查看各Pod的标签选择器

同理,service的ip也动态生成的,当你删除service,再创建相同的service的话,ip已经是另外一个。
同理,Pod是根据标签选择器归为一类,而控制器,例如deployment也是根据标签选择器归为一类。

4、集群外部访问Pod
修改service中spec的type即可,将其改为NodePort

此时就可以在集群外部,通过节点ip:30020来访问Pod了。
(4)命令式应用部署、扩缩容、服务暴露
1、扩、缩容Pod
创建一类名为myapp的Pod,副本为2个,可以kubectl get deployment -w进行实时监控创建情况

同时也创建一个service,服务名为myapp

通过Pod客户端来访问进行验证,访问服务名myapp是可以看到Hell MyApp,然后也可以访问hostname.html查看Pod名称

通过循环语句来验证是随机访问这两个Pod的

在副本为2的基础上,进行扩容为5个
![]()
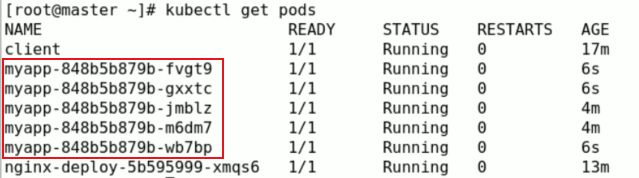
2、升级Pod
kubectl set image 控制器名称 Pod名 容器名=镜像:版本
注:容器名可以指多个,是指Pod内中的各层容器

将myapp版本更新为v2
kubectl set image deployment myapp myapp=ikubernetes/myapp:v2
![]()
通过rollout进行查看更新状态

3、回滚
![]()
三、资源配置清单及Pod资源
(1)Kubernetes API中的资源配置格式
Restful定义:representational state transfer(表象性状态转变)或者表述性状态转移,详解见:https://blog.csdn.net/hzy38324/article/details/78360525?utm_source=gold_browser_extension
Restful中的状态get、put、delete、post通过kubectl run,get,edit等命令展现出来
(2)资源类型、API群组及其版本介绍
1、资源类型
k8s中所有内容抽象为资源,资源实例化后称为对象。
workload(工作负载):Pod,ReplicaSet,Deployment,StatefulSet,DaemonSet,Job,Cronjob等
服务发现及均衡:Service,Ingress等
配置与存储:Volume,CSI等
ConfigMap,Secret
DownwardAPI
集群级资源:Namespace,Node,Role,ClusterRole,RoleBinding,ClusterRoleBinding
元数据型资源:HPA,PodTemplate,LimitRange
(3)Pod资源及其配置格式
1、yaml格式
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,api版本号(或者组名+版本号:group/version。而group省略,则表示core(核心组)的意思),例如v1就是核心组
kind: Pod #必选,资源类别,例如:Pod
metadata: #必选,元数据(内部需要嵌套二级、三级字段)
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,规格即定义创建的资源对象应该要满足什么样的规范。Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
(4)使用配置清单创建自主式Pod资源
创建资源的方法:
apiserver仅接收JSON格式的资源定义;
yaml格式提供配置清单,apiserver可自动将其转为json格式,而后再提交;
命令:kubectl api-versions可以查看所有API 群组/版本
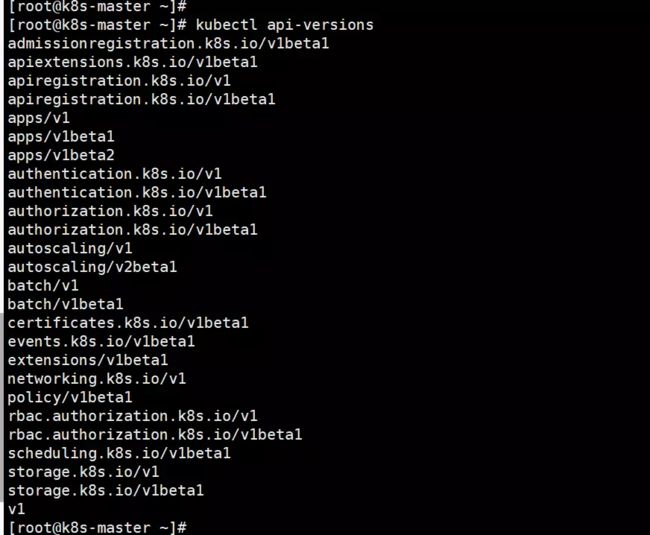
其中Pod是最核心资源因此属于核心组即v1,像控制器属于应用程序管理核心资源因此他们是apps组,即apps/v1。
大部分资源的配置清单格式都由5个一级字段组成:
apiVersion:api版本号
kind:资源类别
metadata:元数据
name:同一类别下的name是唯一的
namespace:对应的对象属于哪个名称空间
labels:标签,每一个资源都可以有标签,标签是一种键值数据
annotations:资源注解
每个的资源引用方式(selflink):
/api/GROUP/VERSION/namespace/NAMESPACE/TYPE/NAME
spec:用户定义一个资源对象应该所处的目标状态,也叫期望状态(可自定义)(disired state)
status:显示资源的当前状态(只读),本字段由kubernetes进行维护(current state)
K8s存在内嵌的文档格式说明,可以使用kubectl explain 进行查看,如查看Pod这个资源需要怎么定义:
[root@k8s-master ~]# kubectl explain pods KIND: Pod VERSION: v1 DESCRIPTION: Pod is a collection of containers that can run on a host. This resource is created by clients and scheduled onto hosts. FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#resources kind <string> Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#types-kinds metadata <Object> Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata spec <Object> Specification of the desired behavior of the pod. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status status <Object> Most recently observed status of the pod. This data may not be up to date. Populated by the system. Read-only. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
从上面可以看到apiVersion,kind等定义的键值都是
[root@k8s-master ~]# kubectl explain pods.metadata
[root@k8s-master ~]# kubectl explain pods.spec
二级字段下,每一种字段都有对应的键值类型,常用类型大致如下:
<[]string>:表示是一个字串列表,也就是字串类型的数组
表示是可以嵌套的字段
<[]Object>:表示是一个对象列表
<[]Object> -required-:required表示该字段是一个必选的字段
使用配置清单创建自主式Pod资源
[root@k8s-master ~]# mkdir mainfests
[root@k8s-master ~]# cd mainfrests
[root@k8s-master mainfrests]# vim pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name:myapp
image: ikubernetes/myapp:v1
- name: busybox
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "sleep 3600"
[root@k8s-master mainfrests]# kubectl create -f pod-demo.yaml
[root@k8s-master mainfrests]# kubectl get pods
[root@k8s-master mainfrests]# kubectl describe pods pod-demo #获取pod详细信息
[root@k8s-master mainfrests]# kubectl logs pod-demo myapp #kubectl logs pod名称 容器名称 可以具体查看某个pod中某个容器的日志
[root@k8s-master mainfrests]# kubectl exec -it pod-demo -c myapp -- /bin/sh
[root@k8s-master mainfrests]# kubectl delete -f xxxxx.yaml #删除这个yaml文件创建的资源
使用yaml清单创建资源,可以创建裸控制器Pod,无控制器管理,一删除就没有了。
事实上使用kubectl命令管理资源有三种用法:
- 命令式用法;
- 命令式资源清单用法;
- 声明式资源清单。使用声明式资源清单,可以确保资源尽可能的向我们声明的状态改变,而且可以随时改变声明,并随时应用。
Pod资源下spec的containers必需字段解析
自主式Pod资源(不受控制器控制)
[root@k8s-master ~]# kubectl explain pods.spec.containers name <string> -required- #containers 的名字 image <string> #镜像地址 imagePullPolicy <string> #如果标签是latest,默认就是Always(总是下载镜像) IfNotPresent(先看本地是否有此镜像,如果没有就下载) Never (就是使用本地镜像,如果没有就从不下载) #这个字段是不允许被更改的 ports <[]Object> #是个对象列表;可以暴露多个端口;可以对每个端口的属性定义 例如:(名称(可后期调用)、端口号、协议、暴露在的地址上) 暴露端口只是提供额外信息的,不能限制系统是否真的暴露 - containerPort 容器端口 hostIP 节点地址(基本不会使用) hostPort 节点端口 name 名称 protocol (默认是TCP) #修改镜像中的默认应用 args <[]string> 传递参数给command 相当于docker中的CMD command <[]string> 相当于docker中的ENTRYPOINT;如果不提供命令,就运行镜像中的ENTRYPOINT。
官方文档对于command和args有个详细的介绍:
https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/
表示docker中的entrypoint、cmd分别相当于kubernetes中的command和args。
如果Pod不提供command或args使用Container,则使用Docker镜像中的cmd或者ENTRYPOINT。
如果Pod提供command但不提供args,则仅使用提供 command的。将忽略Docker镜像中定义EntryPoint和Cmd。
如果Pod中仅提供args,则args将作为参数提供给Docker镜像中EntryPoint。
如果提供了command和args,则Docker镜像中的ENTRYPOINT和CMD都将不会生效,Pod中的args将作为参数给command运行。
(5)标签及标签选择器
标签既可以在对象创建时指定,也可以在创建之后使用命令来管理
1、标签
key=value
- key:只能使用字母、数字 、_ 、- 、. (只能以字母数字开头,不能超过63给字符)
- value: 可以为空,只能使用字母、数字开头及结尾,中间可以使用字母、数字 、_ 、- 、.(不能超过63给字符)
[root@k8s-master mainfests]# kubectl get pods --show-labels #查看所有资源的pod标签
NAME READY STATUS RESTARTS AGE LABELS
pod-demo 2/2 Running 0 25s app=myapp,tier=frontend
[root@k8s-master mainfests]# kubectl get pods -l app #只显示包含app的标签
NAME READY STATUS RESTARTS AGE
pod-demo 2/2 Running 0 1m
[root@k8s-master mainfests]# kubectl get pods -L app #显示app字段的标签值的pod的资源
NAME READY STATUS RESTARTS AGE APP
pod-demo 2/2 Running 0 1m myapp
[root@k8s-master mainfests]# kubectl label pods pod-demo release=canary #给pod-demo打上标签
pod/pod-demo labeled
[root@k8s-master mainfests]# kubectl get pods -l app --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-demo 2/2 Running 0 1m app=myapp,release=canary,tier=frontend
[root@k8s-master mainfests]# kubectl label pods pod-demo release=stable --overwrite #修改标签
pod/pod-demo labeled
[root@k8s-master mainfests]# kubectl get pods -l release
NAME READY STATUS RESTARTS AGE
pod-demo 2/2 Running 0 2m
[root@k8s-master mainfests]# kubectl get pods -l release,app
NAME READY STATUS RESTARTS AGE
pod-demo 2/2 Running 0 2m
2、标签选择器类别
- 等值关系标签选择器:=, == , != (kubectl get pods -l app=test,app=dev)
- 集合关系标签选择器: KEY in (value1,value2,value3);KEY notin (value1,value2,value3); !KEY (例如:kubectl get pods -l "app in (test,dev)")
许多资源支持内嵌字段定义其使用的标签选择器
- matchLabels: 直接给定键值
- matchExpressions: 基于给定的表达式来定义使用标签选择器,{key:"KEY",operator:"OPERATOR",values:[V1,V2,....]}
- 操作符(即OPERATOR):in、notin(前两个Values字段的值必须为非空列表)、Exists、NotExists(后两个Values字段的值必须为空列表)
(6)Pod的节点选择器
[root@k8s-master mainfests]# kubectl get nodes --show-labels #查看node节点的标签
如上图beta.kubernetes.io是标签前缀,标签前缀必须是DNS名称,DNS域名或者子域名,最长长度不能超过254个字符
[root@k8s-master mainfests]# kubectl explain pod.spec
nodeName <string> #直接指定node节点名称 NodeName is a request to schedule this pod onto a specific node. If it is non-empty, the scheduler simply schedules this pod onto that node, assuming that it fits resource requirements. nodeSelector <map[string]string> NodeSelector is a selector which must be true for the pod to fit on a node. Selector which must match a node's labels for the pod to be scheduled on that node. More info: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
nodeSelector可以限定pod创建或者运行在哪个或哪类节点上,举个例子,给节点k8s-node01打上标签disktype=ssd,让pod-demo指定创建在k8s-node01上
(1)给k8s-node01节点打标签 [root@k8s-master mainfests]# kubectl label nodes k8s-node01 disktype=ssd node/k8s-node01 labeled [root@k8s-master mainfests]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS k8s-master Ready master 10d v1.11.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=k8s-master,node-role.kubernetes.io/master= k8s-node01 Ready <none> 10d v1.11.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/hostname=k8s-node01 k8s-node02 Ready <none> 9d v1.11.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/hostname=k8s-node02 (2)修改yaml文件,增加标签选择器 [root@k8s-master mainfests]# cat pod-demo.yaml apiVersion: v1 kind: Pod metadata: name: pod-demo namespace: default labels: app: myapp tier: frontend spec: containers: - name: myapp image: ikubernetes/myapp:v1 - name: busybox image: busybox:latest command: - "/bin/sh" - "-c" - "sleep 3600" nodeSeletor: disktype: ssd (3)重新创建pod-demo,可以看到固定调度在k8s-node01节点上 [root@k8s-master mainfests]# kubectl delete -f pod-demo.yaml pod "pod-demo" deleted [root@k8s-master mainfests]# kubectl create -f pod-demo.yaml pod/pod-demo created [root@k8s-master mainfests]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-demo 2/2 Running 0 20s 10.244.1.13 k8s-node01 [root@k8s-master mainfests]# kubectl describe pod pod-demo ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 42s default-scheduler Successfully assigned default/pod-demo to k8s-node01 ......
annotations:
与label不同的地方在于,annotations不能用于挑选资源对象,仅用于为对象提供"元数据",没有键值长度限制。在声明式配置构建大型镜像相关信息时,通常都会添加annotations,用来标记对应的资源对象的元数据或者属性信息,同样想查看annotations的信息可以使用kubectl describe pod pod-demo
(7)容器存活状态探测及就绪状态探测
1、Pod生命周期
在pod生命周期中需要经历以下几个阶段。主容器(main container)在运行前需要做一些环境设定,因此在启动之前可以运行另一个容器,为主容器做一些环境初始化,这类容器被称为init容器(init container)。初始化容器可以有多个,他们是串行执行的,执行完成后就退出了。在主容器刚刚启动之后,可以嵌入一个post start命令执行一些操作,在主容器结束前也可以指定一个 pre stop命令执行一些操作,作为开场的预设,结束时的清理。在整个主容器执行过程中,还可以做两类对Pod的检测 liveness probe 和 readness probe。如下图:
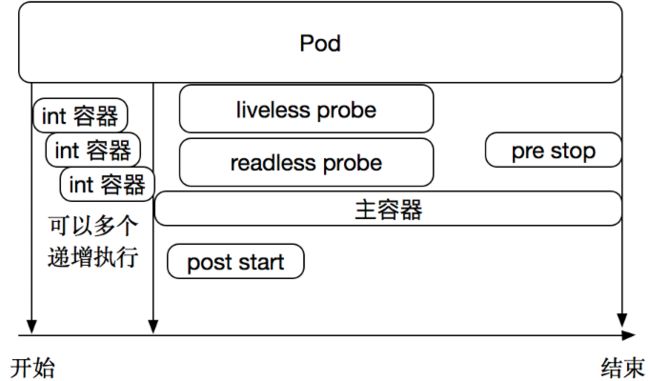
Kubelet 可以选择是否执行在容器上运行的两种探针执行和做出反应:
livenessProbe:存活状态检测。指容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器不提供存活探针,则默认状态为Success。readinessProbe:就绪状态检测。指容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
2、常见的Pod状态
Pod 的 status 在信息保存在 PodStatus 中定义,其中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的 phase值。
下面是 phase 可能的值:
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
下图是Pod的生命周期示意图,从图中可以看到Pod状态的变化。

3、总结
Pod生命周期中的重要行为
1、初始化容器
2、容器探测:livenessProbe和readinessProbe
livenessProbe:存活状态检测(判定主容器是否处于运行状态)
readinessProbe:就绪状态检测(判定容器中的主进程,是否已经准备就绪并可以对外提供服务)
#kubernetes把容器探测分为这两种形式,而docker只需探测第一种,如果容器不存活,这个docker就结束了;相对于kubernetes而言,一个Pod里可以存在多个容器。
容器探测的三种行为:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
容器重启策略
[root@k8s-master mainfests]# kubectl explain pod.spec
Spec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。
Always:一旦Pod中的容器挂了,总是重启
OnFailure:状态错误时才重启,正常关掉不重启
Never: 状态错误和正常关掉也从不重启
其中默认值是Always,如果一直重启对服务器是有压力的,所以它重启策略是,第一次为立即重启;接下来第二次重启则需要延时,比如延时10s在进行重启;第三次延时20s;第四次延时40s;往下80s、160s、300s,300s是最长的延时时间(即5分钟)。pod一旦绑定到一个节点,Pod 将永远不会重新绑定到另一个节点,除非删除Pod重新创建。
4、livenessProbe解析
[root@k8s-master ~]# kubectl explain pod.spec.containers.livenessProbe KIND: Pod VERSION: v1 RESOURCE: livenessProbe <Object> exec #command 的方式探测。例如:ps一个进程 failureThreshold #探测几次失败才算失败,默认是连续三次 periodSeconds #每次多长时间探测一次,默认10s timeoutSeconds #探测超时的秒数 默认1s initialDelaySeconds #初始化延迟探测。第一次探测的时候延迟探测,因为主程序未必启动完成 tcpSocket #检测端口的探测 httpGet #http请求探测
举个例子:定义一个liveness的pod资源类型,基础镜像为busybox,在busybox这个容器启动后会执行创建/tmp/test的文件啊,并删除,然后等待3600秒。随后定义了存活性探测,方式是以exec的方式执行命令判断/tmp/test是否存在,存在即表示存活,不存在则表示容器已经挂了。
[root@master manifests]# cat liveness.exec.ymal
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox:latest
imagePullPolicy: IfNotPresent #如果存在就不要下载了
command: ["/bin/sh","-c","touch /tmp/healthy;sleep 60;rm -f /tmp/healthy;sleep 3600"]
livenessProbe: #存活性探测
exec:
command: ["test","-e","/tmp/healthy"] #-e表示探测文件是否存在
initialDelaySeconds: 1 #表示容器启动后多长时间开始探测
periodSeconds: 3 #表示每隔3s钟探测一次
[root@master manifests]# kubectl create -f liveness.exec.ymal
pod/liveness-exec-pod created
[root@master manifests]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 2 4m
[root@master manifests]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 4 6m
[root@master manifests]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
client 1/1 Running 0 3d
liveness-exec-pod 1/1 Running 5 9m
[root@master manifests]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
client 1/1 Running 0 3d
liveness-exec-pod 1/1 Running 9 23m
可以看到restart此时在随着时间增长。
上面的例子是用exec执行命令进行探测的。
下面我们看看基于tcp和httpget探测的选项。
[root@master manifests]kubectl explain pods.spec.containers.livenessProbe.tcpSocket
[root@master manifests]# kubectl explain pods.spec.containers.livenessProbe.httpGet
下面举个例子
[root@master manifests]# cat liveness.httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: nginx:latest
imagePullPolicy: IfNotPresent #如果存在就不要下载了
ports:
- name: http
containerPort: 80
livenessProbe: #存活性探测
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3 #表示每隔3s钟探测一次
[root@master manifests]# kubectl create -f liveness.httpget.yaml
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 0 4m
[root@master manifests]# kubectl exec -it liveness-httpget-pod -- /bin/sh
# rm -rf /usr/share/nginx/html/index.html
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 1 27m
上面可以看到,当删除pod里面的/usr/share/nginx/html/index.html,liveness监测到index.html文件被删除了,所以restarts次数为1,但是只重启一次,不会再重启了。这是因为重启一次后,nginx容器就重新初始化了,里面就会又生成index.html文件。所以里面就会有新的index.html文件了。
readlinessProbe(准备就绪型探针)
[root@master manifests]# cat readiness-httpget.ymal
apiVersion: v1
kind: Pod
metadata:
name: readdliness-httpget-pod
namespace: default
spec:
containers:
- name: readliness-httpget-container
image: nginx:latest
imagePullPolicy: IfNotPresent #如果存在就不要下载了
ports:
- name: http
containerPort: 80
readinessProbe: #准备型探针
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3 #表示每隔3s钟探测一次
[root@master manifests]# kubectl create -f readiness-httpget.ymal
pod/readdliness-httpget-pod created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readdliness-httpget-pod 1/1 Running 0 16h
[root@master ~]# kubectl exec -it readdliness-httpget-pod -- /bin/sh
# rm -rf /usr/share/nginx/html/index.html
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readdliness-httpget-pod 0/1 Running 0 16h
上面可以看到,ready变成0/1了,但是status是runing的,这就是说nginx进程是在的,只是index.html不见了,可以判定nginx没有就绪。
postStart(启动后钩子)
[root@master ~]# kubectl explain pods.spec.containers.lifecycle.postStart
postStart是指容器在启动之后立即执行的操作,如果执行操作失败了,容器将被终止并且重启。而重启与否是由重启策略。
[root@master manifests]# cat poststart-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: poststart-pod
namespace: default
spec:
containers:
- name: busybox-httpd
image: busybox:latest
imagePullPolicy: IfNotPresent
lifecycle: #生命周期事件
postStart:
exec:
command: ["mkdir", "-p","/data/web/html"] #这个command是定义postStart后的需要执行的命令
command: ["/bin/sh","-c","sleep 3600"] #这是定义容器里面执行的命令,不过这个命令要先于postStart里面的command
#args: ["-f","-h /data/web/html"] #-f是前台,-h是家目录
[root@master manifests]# kubectl create -f poststart-pod.yaml
pod/posttart-pod created
说明:删除的方法
[root@master manifests]# kubectl delete -f poststart-pod.yaml
pod "posttart-pod" deleted
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
poststart-pod 1/1 Running 0 3m
[root@master manifests]# kubectl exec -it poststart-pod -- /bin/sh
/ # ls /data
web
/ # ls /data/web/html/
上面看到在容器启动后,建立了/data/web/html目录。这就是postStart的用法。
preStop(终止之前钩子)
[root@master ~]# kubectl explain pods.spec.containers.lifecycle.preStop
preStop是指容器在终止前要立即执行的命令,等这些命令执行完了,容器才能终止。
容器的重启策略-restartPolicy
一旦pod中的容器挂了,我们就把容器重启。
策略包括如下:
Always:表示容器挂了总是重启,这是默认策略
OnFailures:表容器状态为错误时才重启,也就是容器正常终止时才重启
Never:表示容器挂了不予重启
对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启...... 依次类推
容器的终止策略
k8s会给容器30s的时间进行终止,如果30s后还没终止,就会强制终止。
总结
pod:
apiVersion
kind
metadata
spec
status(只读)
spec:
containers
nodeSelector
nodeName
restartPolicy: Always,Never,OnFailure
containers:
name
image
imagePullPolicy: Always、Never、IfNotPresent
ports:
name
containerPort
livenessProbe
readinessProbe
liftcycle
ExecAction: exec
TCPSocketAction: tcpSocket
HTTPGetAction: httpGet
四、Pod控制器
(1)Pod控制器及其功用
(2)通过配置清单管理ReplicaSet控制器,包括扩缩容及更新机制
(3)Deployment控制器基础应用及滚动更新:灰度部署、金丝雀部署、蓝绿部署的实现;
(4)DaemonSet控制器基础应用及使用案例
上一节,我们创建的pod,是通过资源配置清单定义的,如果手工把这样的pod删除后,不会自己重新创建,这样创建的pod叫自主式Pod。
在生产中,我们很少使用自主式pod。
下面我们学习另外一种pod,叫控制器管理的Pod,控制器会按照定义的策略严格控制pod的数量,一旦发现pod数量少了,会立即自动建立出来新的pod;一旦发现pod多了,也会自动杀死多余的Pod。
pod控制器:ReplicaSet控制器、Deployment控制器(必须掌握)、DaenibSet控制器、Job控制器
ReplicaSet控制器 :替用户创建指定数量Pod的副本,并保证pod副本满足用户期望的数量;而且更新自动扩缩容机制。
replicat主要由三个组件组成:1、用户期望的pod副本数量;2、标签选择器(控制管理pod副本);3、pod资源模板(如果pod数量少于期望的,就根据pod模板来新建一定数量的pod)。
Deployment控制器 :Deployment通过控制replicaset来控制Pod。用于管理无状态应用,目前来说最好的控制器。Deployment支持滚动更新和回滚,声明式配置的功能。Deployment只关注群体,而不关注个体。
DaemonSet控制器 :用于确保集群中的每一个节点只运行一个特定的pod副本(画外音,如果没有DaemonSet,一个节点可以运行多个pod副本)。如果在集群中新加一个节点,那么这个新节点也会自动生成一个Pod副本。
特性:服务是无状态的;服务必须是守护进程
Job控制器 :对于那些 只做一次,只要完成就正常退出,没完成才重构pod ,叫job控制器。
Cronjob:周期性任务控制,不需要持续后台运行
StatefulSet控制器: 管理有状态应用,每一个pod副本都是被单独管理的。它拥有着自己独有的标识。
K8s在1.2+至1.7开始,支持TPR(third party resources 第三方资源)。在k8s 1.8+以后,支持CDR(Custom Defined Reources,用户自定义资源)。
Operator是CoreOS推出的旨在简化复杂有状态应用管理的框架,它是一个感知应用状态的控制器,通过扩展Kubernetes API来自动创建、管理和配置应用实例。
ReplicaSet控制器
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。
在新版本的Kubernetes中建议使用ReplicaSet来取代ReplicationController。ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector。
虽然ReplicaSet可以独立使用,但一般还是建议使用 Deployment 来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update但Deployment支持)。
[root@master manifests]# kubectl explain replicaset
[root@master manifests]# kubectl explain rs (replicaset的简写)
[root@master manifests]# kubectl explain rs.spec.template
[root@master manifests]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
myapp 2 2 2 0 10d
mytomcat 3 3 3 3 10d
nginx-deploy 1 1 1 1 13d
[root@master manifests]# kubectl delete deploy myapp
deployment.extensions "myapp" deleted
[root@master manifests]# kubectl delete deploy nginx-deploy
deployment.extensions "nginx-deploy" deleted
[root@master manifests]# cat rs-demo.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp
namespace: default
spec: #这是控制器的spec
replicas: 2 #几个副本
selector: #查看帮助:,标签选择器。 kubectl explain rs.spec.selector
matchLabels:
app: myapp
release: canary
template: # 查看帮助:模板 kubectl explain rs.spec.template
metadata: # kubectl explain rs.spec.template.metadata
name: myapp-pod
labels: #必须符合上面定义的标签选择器selector里面的内容
app: myapp
release: canary
environment: qa
spec: #这是pod的spec
containers:
- name: myapp-container
image: ikubernetes/nginx:latest
ports:
- name: http
containerPort: 80
[root@master manifests]# kubectl create -f rs-demo.yaml
replicaset.apps/myapp created
[root@master manifests]# kubectl get rs
NAME DESIRED CURRENT READY AGE
myapp 2 2 2 3m
看到上面的ready是2,表示两个replcatset控制器都在正常运行。
[root@master manifests]# kubectl get pods --show-labels
myapp-6kncv 1/1 Running 0 15m app=myapp,environment=qa,release=canary
myapp-rbqjz 1/1 Running 0 15m app=myapp,environment=qa,release=canary 5m
pod-demo 0/2 CrashLoopBackOff 2552 9d app=myapp,tier=frontend
[root@master manifests]# kubectl describe pods myapp-6kncv
IP: 10.244.2.44
[root@master manifests]# curl 10.244.2.44 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Namea>
编辑replicatset的配置文件(这个文件不是我们手工创建的,而是apiserver维护的)
[root@master manifests]# kubectl edit rs myapp
把里面的replicas改成5,保存后就立即生效。
[root@master manifests]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS client 0/1 Error 0 11d run=client liveness-httpget-pod 1/1 Running 3 5d <none> myapp-6kncv 1/1 Running 0 31m app=myapp,environment=qa,release=canary myapp-c64mb 1/1 Running 0 3s app=myapp,environment=qa,release=canary myapp-fsrsg 1/1 Running 0 3s app=myapp,environment=qa,release=canary myapp-ljczj 0/1 ContainerCreating 0 3s app=myapp,environment=qa,release=canary myapp-rbqjz 1/1 Running 0 31m app=myapp,environment=qa,release=canary
同样,也可以用命令kubectl edit rs myapp升级版本,改里面的image: ikubernetes/myapp:v2,这样就变成v2版本了。
[root@master manifests]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
myapp 5 5 5 1h myapp-container ikubernetes/myapp:v2 app=myapp,release=canary
不过,只有pod重建后,比如增加、删除Pod,才会更新成v2版本。
Deployment控制器

我们可以通过Deployment控制器来动态更新pod的版本。
我们先建立replicatset v2版本,然后一个一个的删除replicatset v1版本中的Pod,这样自动新创建的pod就会变成v2版本了。当pod全部变成v2版本后,replicatset v1并不会删除,这样一旦发现v2版本有问题,还可以回退到v1版本。
通常deployment默认保留10版本的replicatset。
[root@master manifests]# kubectl explain deploy
[root@master manifests]# kubectl explain deploy.spec
[root@master manifests]# kubectl explain deploy.spec.strategy (更新策略)
[root@master ~]# kubectl delete rs myapp
[root@master manifests]# cat deploy-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 2
selector: #标签选择器
matchLabels: #匹配的标签为
app: myapp
release: canary
template:
metadata:
labels:
app: myapp #和上面的myapp要匹配
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
[root@master manifests]# kubectl apply -f deploy-demo.yaml
deployment.apps/myapp-deploy created
apply表示是声明式更新和创建。
[root@master manifests]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
myapp-deploy 2 2 2 2 1m
[root@master ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
myapp-deploy-69b47bc96d 2 2 2 17m
上面的rs式deployment自动创建的。
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy-69b47bc96d-7jnwx 1/1 Running 0 19m
myapp-deploy-69b47bc96d-btskk 1/1 Running 0 19m
修改配置文件deploy-demo.yaml,把replicas数字改成3,然后再执行kubectl apply -f deploy-demo.yaml 即可使配置文件里面的内容生效。
[root@master ~]# kubectl describe deploy myapp-deploy
[root@master ~]# kubectl get pods -l app=myapp -w
-l使标签过滤
-w是动态监控
[root@master ~]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
myapp-deploy-69b47bc96d 2 2 2 1h myapp ikubernetes/myapp:v1 app=myapp,pod-template-hash=2560367528,release=canary
看滚动更新的历史:
[root@master ~]# kubectl rollout history deployment myapp-deploy deployments "myapp-deploy" REVISION CHANGE-CAUSE 1 <none>
下面我们把deployment改成5个:我们可以使用vim deploy-demo.yaml方法,把里面的replicas改成5。当然,还可以使用另外一种方法,就patch方法,举例如下。
[root@master manifests]# kubectl patch deployment myapp-deploy -p '{"spec":{"replicas":5}}'
deployment.extensions/myapp-deploy patched
[root@master manifests]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
myapp-deploy 5 5 5 5 2h
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy-69b47bc96d-7jnwx 1/1 Running 0 2h
myapp-deploy-69b47bc96d-8gn7v 1/1 Running 0 59s
myapp-deploy-69b47bc96d-btskk 1/1 Running 0 2h
myapp-deploy-69b47bc96d-p5hpd 1/1 Running 0 59s
myapp-deploy-69b47bc96d-zjv4p 1/1 Running 0 59s
mytomcat-5f8c6fdcb-9krxn 1/1 Running 0 8h
下面修改策略:
[root@master manifests]# kubectl patch deployment myapp-deploy -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavaliable":0}}}}'
deployment.extensions/myapp-deploy patched
strategy:表示策略
maxSurge:表示最多几个控制器存在
maxUnavaliable:表示最多有几个控制器不可用
[root@master manifests]# kubectl describe deployment myapp-deploy
RollingUpdateStrategy: 0 max unavailable, 1 max surge
下面我们用set image命令,将镜像myapp升级为v3版本,并且将myapp-deploy控制器标记为暂停。被pause命令暂停的资源不会被控制器协调使用,可以使“kubectl rollout resume”命令恢复已暂停资源。
[root@master manifests]# kubectl set image deployment myapp-deploy myapp=ikubernetes/myapp:v3 &&
kubectl rollout pause deployment myapp-deploy
[root@master ~]# kubectl get pods -l app=myapp -w
停止暂停:
[root@master ~]# kubectl rollout resume deployment myapp-deploy
deployment.extensions/myapp-deploy resumed
看到继续更新了(即删一个更新一个,删一个更新一个):
[root@master manifests]# kubectl rollout status deployment myapp-deploy
Waiting for deployment "myapp-deploy" rollout to finish: 2 out of 5 new replicas have been updated...
Waiting for deployment spec update to be observed...
Waiting for deployment spec update to be observed...
Waiting for deployment "myapp-deploy" rollout to finish: 2 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 3 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 3 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 4 out of 5 new replicas have been updated...
Waiting for deployment "myapp-deploy" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "myapp-deploy" rollout to finish: 1 old replicas are pending termination...
deployment "myapp-deploy" successfully rolled out
[root@master manifests]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
myapp-deploy-69b47bc96d 0 0 0 6h myapp ikubernetes/myapp:v1 app=myapp,pod-template-hash=2560367528,release=canary
myapp-deploy-6bdcd6755d 5 5 5 3h myapp ikubernetes/myapp:v3 app=myapp,pod-template-hash=2687823118,release=canary
mytomcat-5f8c6fdcb 3 3 3 12h mytomcat tomcat pod-template-hash=194729876,run=mytomcat
上面可以看到myapp有v1和v3两个版本。
[root@master manifests]# kubectl rollout history deployment myapp-deploy deployments "myapp-deploy" REVISION CHANGE-CAUSE 1 <none> 2 <none>
上面可以看到有两个历史更新记录。
下面我们把v3回退到上一个版本(不指定就是上一个版本)。
[root@master manifests]# kubectl rollout undo deployment myapp-deploy --to-revision=1
deployment.extensions/myapp-deploy
可以看到第一版还原成第3版了:
[root@master manifests]# kubectl rollout history deployment myapp-deploy deployments "myapp-deploy" REVISION CHANGE-CAUSE 2 <none> 3 <none>
可以看到正在工作的是v1版,即回退到了v1版。
[root@master manifests]# kubectl get rs -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
myapp-deploy-69b47bc96d 5 5 5 6h myapp ikubernetes/myapp:v1 app=myapp,pod-template-hash=2560367528,release=canary
myapp-deploy-6bdcd6755d 0 0 0 3h myapp ikubernetes/myapp:v3 app=myapp,pod-template-hash=2687823118,release=canary
DaemonSet控制器
通过 https://hub.docker.com/r/ikubernetes/filebeat/tags/可以看到filebeat的版本有哪些:

[root@node1 manifests]# docker pull ikubernetes/filebeat:5.6.5-alpine
[root@node2 manifests]# docker pull ikubernetes/filebeat:5.6.5-alpine
node1和node2上都下载filebeat镜像。
[root@node1 ~]# docker image inspect ikubernetes/filebeat:5.6.5-alpine
[root@master manifests]# kubectl explain pods.spec.containers.env
[root@master manifests]# cat ds-demo.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: myapp-ds
namespace: default
spec:
selector: #标签选择器
matchLabels: #匹配的标签为
app: filebeat
release: stable
template:
metadata:
labels:
app: filebeat #和上面的myapp要匹配
release: stable
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
env:
- name: REDIS_HOST
value: redis.default.svc.cluster.local #随便取的名字
name: REDIS_LOG_LEVEL
value: info
[root@master manifests]# kubectl apply -f ds-demo.yaml
daemonset.apps/myapp-ds created
看到myapp-ds已经运行起来了,并且是两个myapp-ds,这是因为我们有两个Node节点。另外master节点上是不会运行myapp-ds控制器的,因为master有污点(除非你设置允许有污点,才可以在master上允许myapp-ds)
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-ds-5tmdd 1/1 Running 0 1m
myapp-ds-dkmjj 1/1 Running 0 1m
[root@master ~]# kubectl logs myapp-ds-dkmjj
[root@master manifests]# kubectl delete -f ds-demo.yaml
[root@master manifests]# cat ds-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: redis
role: logstor #日志存储角色
template:
metadata:
labels:
app: redis
role: logstor
spec: #这个是容器的spec
containers:
- name: redis
image: redis:4.0-alpine
ports:
- name: redis
containerPort: 6379
#用减号隔离资源定义清单
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
namespace: default
spec:
selector: #标签选择器
matchLabels: #匹配的标签为
app: filebeat
release: stable
template:
metadata:
labels:
app: filebeat #和上面的myapp要匹配
release: stable
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.6-alpine
env:
- name: REDIS_HOST #这是环境变量名,value是它的值
value: redis.default.svc.cluster.local #随便取的名字
- name: REDIS_LOG_LEVEL
value: info
[root@master manifests]# kubectl create -f ds-demo.yaml
deployment.apps/redis created
daemonset.apps/filebeat-ds created
[root@master manifests]# kubectl expose deployment redis --port=6379 ##这是在用expose方式创建service,其实还有一种方式是根据清单创建service
service/redis exposed
[root@master manifests]# kubectl get svc #service的简称 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE redis ClusterIP 10.106.138.181 <none> 6379/TCP 48s
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
filebeat-ds-hgbhr 1/1 Running 0 9h
filebeat-ds-xc7v7 1/1 Running 0 9h
redis-5b5d6fbbbd-khws2 1/1 Running 0 33m
[root@master manifests]# kubectl exec -it redis-5b5d6fbbbd-khws2 -- /bin/sh
/data # netstat -tnl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN
tcp 0 0 :::6379 :::* LISTEN
/data # nslookup redis.default.svc.cluster.local #看到DNS可以解析出来ip
nslookup: can't resolve '(null)': Name does not resolve
Name: redis.default.svc.cluster.local
Address 1: 10.106.138.181 redis.default.svc.cluster.local
/data # redis-cli -h redis.default.svc.cluster.local
redis.default.svc.cluster.local:6379> keys *
(empty list or set)
redis.default.svc.cluster.local:6379>
[root@master manifests]# kubectl exec -it filebeat-ds-pnk8b -- /bin/sh
/ # ps aux
PID USER TIME COMMAND
1 root 0:00 /usr/local/bin/filebeat -e -c /etc/filebeat/filebeat.yml
15 root 0:00 /bin/sh
22 root 0:00 ps aux
/ # cat /etc/filebeat/filebeat.yml
filebeat.registry_file: /var/log/containers/filebeat_registry
filebeat.idle_timeout: 5s
filebeat.spool_size: 2048
logging.level: info
filebeat.prospectors:
- input_type: log
paths:
- "/var/log/containers/*.log"
- "/var/log/docker/containers/*.log"
- "/var/log/startupscript.log"
- "/var/log/kubelet.log"
- "/var/log/kube-proxy.log"
- "/var/log/kube-apiserver.log"
- "/var/log/kube-controller-manager.log"
- "/var/log/kube-scheduler.log"
- "/var/log/rescheduler.log"
- "/var/log/glbc.log"
- "/var/log/cluster-autoscaler.log"
symlinks: true
json.message_key: log
json.keys_under_root: true
json.add_error_key: true
multiline.pattern: '^\s'
multiline.match: after
document_type: kube-logs
tail_files: true
fields_under_root: true
output.redis:
hosts: ${REDIS_HOST:?No Redis host configured. Use env var REDIS_HOST to set host.}
key: "filebeat"
/ # printenv
REDIS_HOST=redis.default.svc.cluster.local
/ # nslookup redis.default.svc.cluster.local
nslookup: can't resolve '(null)': Name does not resolve
Name: redis.default.svc.cluster.local
Address 1: 10.106.138.181 redis.default.svc.cluster.local
daemon-set也支持滚动更新。
[root@master manifests]# kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.5.7-alpine
说明: daemonsets filebeat-ds表示daemonsets名字叫filebeat-ds;
filebeat=ikubernetes/filebeat:5.5.7-alpine表示filebeat容器=ikubernetes/filebeat:5.5.7-alpine
五、Service资源对象
(1)Service及其实现模型
(2)Service的类型及其功用
(3)各Service类型的创建及应用方式
(4)Headless Service
(5)基于DNS的服务发现简介
(6)Ingress类型及实现方式
Ingress:就是能利用 Nginx(不常用)、Haproxy(不常用)、Traefik(常用)、Envoy(常用) 啥的负载均衡器暴露集群内服务的工具。
Ingress为您提供七层负载均衡能力,您可以通过 Ingress 配置提供外部可访问的 URL、负载均衡、SSL、基于名称的虚拟主机等。作为集群流量接入层,Ingress 的高可靠性显得尤为重要。
小知识:我们把k8s里面的pod服务发布到集群外部,可以用ingress,也可以用NodePort。
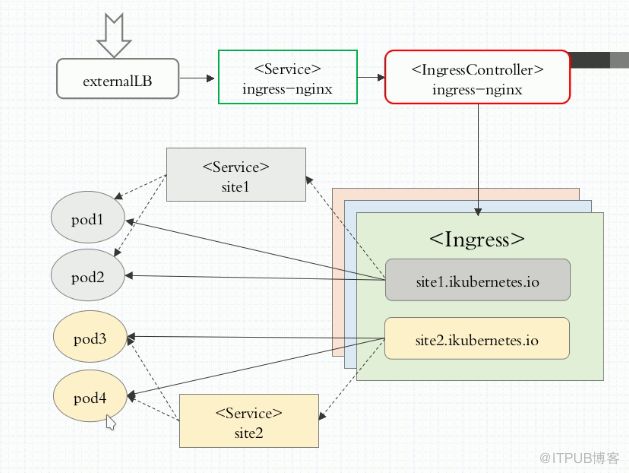
externalLB:外部的负载均衡器
service site:只是用来给pod分组归类的。
|
1
|
[root@master manifests]# kubectl explain ingress
|
创建名称空间:
|
1
2
3
4
5
6
7
8
|
[root@master manifests]# kubectl create namespace ingress-nginx
namespace/dev created
[root@master manifests]# kubectl get ns
NAME STATUS AGE
default
Active
17
d
ingress-nginx Active
8
s
kube-public Active
17
d
kube-system Active
17
d
|
访问 https://github.com/kubernetes/ingress-nginx,进入deploy目录,里面就有我们要用的yaml文件。
|
1
2
3
4
5
6
7
8
|
各文件的作用:
configmap.yaml:提供configmap可以在线更行nginx的配置
default-backend.yaml:提供一个缺省的后台错误页面
404
namespace.yaml:创建一个独立的命名空间 ingress-nginx
rbac.yaml:创建对应的role rolebinding 用于rbac
tcp-services-configmap.yaml:修改L
4
负载均衡配置的configmap
udp-services-configmap.yaml:修改L
4
负载均衡配置的configmap
with-rbac.yaml:有应用rbac的nginx-ingress-controller组件
|
访问https://kubernetes.github.io/ingress-nginx/deploy/#generice-deployment,里面是ingress的部署文档
|
1
2
|
[root@master ~]# mkdir ingress-nginx
[root@master ~]# cd ingress-nginx
|
部署ingress方法一(分步部署):
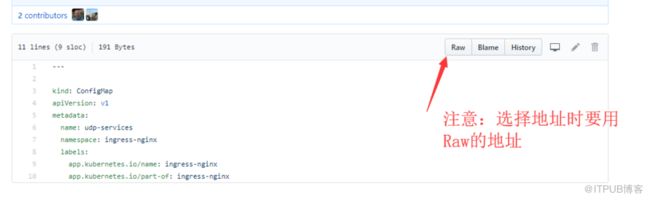
下载如下配置文件:
|
1
|
[root@master ingress-nginx]# for file in namespace.yaml configmap.yaml rbac.yaml tcp-services-configmap.yaml with-rbac.yaml udp-services-configmap.yaml; do wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/$file; done
|
|
1
2
|
[root@master ingress-nginx]# ls
configmap.yaml namespace.yaml rbac.yaml tcp-services-configmap.yaml udp-services-configmap.yaml with-rbac.yaml
|
1、创建名称空间:
|
1
2
|
[root@master ingress-nginx]# kubectl apply -f namespace.yaml
namespace/ingress-nginx configured
|
2、把剩下的ymal文件全应用
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@master ingress-nginx]# kubectl apply -f ./
configmap/nginx-configuration created
namespace/ingress-nginx configured
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k
8
s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k
8
s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k
8
s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k
8
s.io/nginx-ingress-clusterrole-nisa-binding created
configmap/tcp-services created
configmap/udp-services created
deployment.extensions/nginx-ingress-controller created
|
|
1
2
3
4
|
[root@master ingress-nginx]# kubectl get pods -n ingress-nginx -w
NAME READY STATUS RESTARTS AGE
default-http-backend
-6586
bc
58
b
6
-qd
9
fk
0
/
1
running
0
4
m
nginx-ingress-controller
-6
bd
7
c
597
cb-zcbbz
0
/
1
running
0
1
m
|
可以看到ingress-nginx名称空间里面有两个pod都处于running状态
部署ingress方法二(一键部署):
只下载mandatory.yaml文件,因为这个文件里面包含了上面所有yaml文件里面的内容。这是一键部署。
|
1
2
|
[root@master ingress-nginx]# wget
https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
|
|
1
|
[root@master ingress-nginx]#kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
|
|
1
2
3
4
|
[root@master ~]# kubectl get pods -n ingress-nginx -w -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
default-http-backend
-6586
bc
58
b
6
-qd
9
fk
1
/
1
Running
0
11
h
10.244
.
1.95
node
1
<
none
>
nginx-ingress-controller
-6
bd
7
c
597
cb-jlqzp
1
/
1
Running
3
11
h
10.244
.
1.96
node
1
<
none
>
|
可以看到ingress-nginx名称空间里面有两个pod都处于running状态
安装service-nodeport
上面我们把ingress-nginx部署到了1号node上。接下来我们还需要部署一个service-nodeport服务,才能实现把集群外部流量接入到集群中来。
|
1
|
[root@master ingress]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/provider/baremetal/service-nodeport.yaml
|
我们为了不让service nodeport自动分配端口,我们自己指定一下nodeport,修改文件中加两个nodePort参数,最终如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[root@master ingress]# cat service-nodeport.yaml
apiVersion: v
1
kind: Service
metadata:
name: ingress-nginx
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
type: NodePort
ports:
- name: http
port:
80
targetPort:
80
protocol: TCP
nodePort:
30080
- name: https
port:
443
targetPort:
443
protocol: TCP
nodePort:
30443
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
|
|
1
2
|
[root@master ingress]# kubectl apply -f service-nodeport.yaml
service/ingress-nginx created
|
|
1
2
3
4
|
[root@master ingress]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default-http-backend ClusterIP
10.110
.
74.183
<
none
>
80
/TCP
12
h
ingress-nginx NodePort
10.102
.
78.188
<
none
>
80:
30080
/TCP,
443:
30443
/TCP
2
m
|
上面我看到80对应30080,,43对应30443
我们直接通过node1节点的ip就可以访问到应用:
|
1
2
|
[root@master ingress]# curl http://
172.16
.
1.101:
30080
default
backend -
404
|
定义myapp service
|
1
|
[root@master manifests]# mkdir /root/manifests/ingress
|
|
1
|
[root@master ~]# kubectl explain service.spec.ports
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
[root@master ingress]# cat deploy-demo.yaml
apiVersion: v
1
kind: Service
#必须设置为无头service
metadata:
name: myapp
namespace:
default
spec:
selector:
app: myapp
release: canary
ports:
- name: http
targetPort:
80
#这是容器port
port:
80
#这是service port
---
apiVersion: apps/v
1
kind: Deployment
metadata:
name: myapp-deploy
namespace:
default
spec:
replicas:
2
selector: #标签选择器
matchLabels: #匹配的标签为
app: myapp
release: canary
template:
metadata:
labels:
app: myapp #和上面的myapp要匹配
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v
1
ports:
- name: http
containerPort:
80
|
|
1
2
3
|
[root@master ingress]# kubectl apply -f deploy-demo.yaml
service/myapp created
deployment.apps/myapp-deploy unchanged
|
|
1
2
3
4
|
[root@master ingress]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP
10.96
.
0.1
<
none
>
443
/TCP
17
d
myapp ClusterIP
10.108
.
177.62
<
none
>
80
/TCP
1
m
|
|
1
2
3
4
|
[root@master ingress]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy
-69
b
47
bc
96
d
-79
fqh
1
/
1
Running
0
1
d
myapp-deploy
-69
b
47
bc
96
d-tc
54
k
1
/
1
Running
0
1
d
|
把myapp service通过ingress发布出去
下面我们再定义一个清单文件,把myapp应用通过Ingress(相当于nginx的反向代理功能)发布出去:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@master ingress]# cat ingress-myapp.yaml
apiVersion: extensions/v
1
beta
1
kind: Ingress
metadata:
name: ingress-myapp
namespace:
default
#要和deployment和要发布的service处于同一个名称空间
annotations: #这个注解说明我们要用到的ingress-controller是nginx,而不是traefic,enjoy
kubernetes.io/ingress.class:
"nginx"
spec:
rules:
- host: myapp.zhixin.com #表示访问这个域名,就会转发到后端myapp管理的pod上的服务:
http:
paths:
- path:
backend:
serviceName: myapp
servicePort:
80
|
|
1
2
|
[root@master ingress]# kubectl apply -f ingress-myapp.yaml
ingress.extensions/ingress-myapp created
|
|
1
2
3
|
[root@master ingress]# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-myapp myapp.zhixin.com
80
8
m
|
|
1
|
[root@master ingress]# kubectl describe ingress
|
|
1
2
3
4
|
[root@master ingress]# kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
default-http-backend
-6586
bc
58
b
6
-qd
9
fk
1
/
1
Running
0
12
h
nginx-ingress-controller
-6
bd
7
c
597
cb-jlqzp
1
/
1
Running
3
12
h
|
进入ingress-controller交互式命令行里面,可以清晰的看到nginx是怎么反向代理我们myapp.zhixin.com的:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@master ingress]# kubectl exec -n ingress-nginx -it nginx-ingress-controller
-6
bd
7
c
597
cb-jlqzp -- /bin/sh
$ cat nginx.conf
## start server myapp.zhixin.com
server {
server_name myapp.zhixin.com ;
listen
80
;
set $proxy_upstream_name
"-"
;
location / {
set $namespace
"default"
;
set $ingress_name
"ingress-myapp"
;
set $service_name
"myapp"
;
set $service_port
"80"
;
........
|
测试,下面我们把myapp.zhixin.com域名解析到node1 ip 172.16.1.101上。
|
1
2
|
[root@master ingress]# curl myapp.zhixin.com:
30080
Hello MyApp | Version: v
1
| |
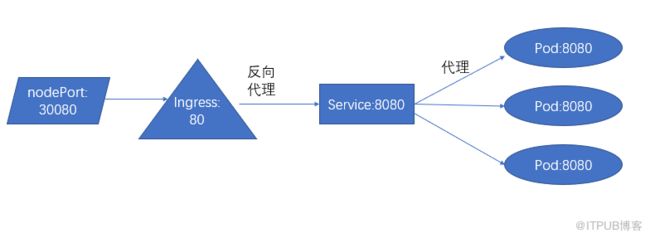
把tomcat service通过ingress发布出去(新例子)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
[root@master ingress]# cat tomcat-demo.yaml
apiVersion: v
1
kind: Service
#必须设置为无头service
metadata:
name: tomcat
namespace:
default
spec:
selector:
app: tomcat
release: canary
ports:
- name: http
targetPort:
8080
#这是容器port
port:
8080
#这是service port
- name: ajp
targetPort:
8009
port:
8009
---
apiVersion: apps/v
1
kind: Deployment
metadata:
name: tomcat-deploy
namespace:
default
spec:
replicas:
2
selector: #标签选择器
matchLabels: #匹配的标签为
app: tomcat
release: canary
template:
metadata:
labels:
app: tomcat #和上面的myapp要匹配
release: canary
spec:
containers:
- name: tomcat
image: tomcat:
8.5
.
34
-jre
8
-alpine #在https://hub.docker.com/r/library/tomcat/tags/上面找
ports:
- name: http
containerPort:
8080
- name: ajp
containerPort:
8009
|
|
1
2
3
|
[root@master ingress]# kubectl apply -f tomcat-demo.yaml
service/tomcat created
deployment.apps/tomcat-deploy created
|
|
1
2
3
4
|
[root@master ingress]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP
10.96
.
0.1
<
none
>
443
/TCP
17
d
tomcat ClusterIP
10.109
.
76.87
<
none
>
8080
/TCP,
8009
/TCP
1
m
|
|
1
2
3
4
|
[root@master ingress]# kubectl get pods
NAME READY STATUS RESTARTS AGE
tomcat-deploy
-64
c
4
d
54
df
4
-68
sk
8
1
/
1
Running
0
51
s
tomcat-deploy
-64
c
4
d
54
df
4
-7
b
58
g
1
/
1
Running
0
51
s
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@master ingress]# cat ingress-tomcat.yaml
apiVersion: extensions/v
1
beta
1
kind: Ingress
metadata:
name: ingress-tomcat
namespace:
default
#要和deployment和要发布的service处于同一个名称空间
annotations: #这个注解说明我们要用到的ingress-controller是nginx,而不是traefic,enjoy
kubernetes.io/ingress.class:
"nginx"
spec:
rules:
- host: tomcat.zhixin.com #表示访问这个域名,就会转发到后端myapp管理的pod上的服务:
http:
paths:
- path:
backend:
serviceName: tomcat
servicePort:
8080
|
|
1
2
|
[root@master ingress]# kubectl apply -f ingress-tomcat.yaml
ingress.extensions/ingress-myapp configured
|
|
1
2
3
|
[root@master ingress]# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-tomcat tomcat.zhixin.com
80
11
s
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[root@master ingress]# kubectl describe ingress ingress-tomcat
Name: ingress-tomcat
Namespace:
default
Address:
Default backend: default-http-backend:
80
(<
none
>)
Rules:
Host Path Backends
---- ---- --------
tomcat.zhixin.com
tomcat:
8080
(<
none
>)
Annotations:
kubernetes.io/ingress.class: nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE
1
m nginx-ingress-controller Ingress
default
/ingress-tomcat
|
把tomcat.zhixin.com解析到node1上节点物理ip(我的是172.16.1.101)
测试,可以看到tomcat欢迎界面:
|
1
|
[root@master ingress]# curl tomcat.zhixin.com:
30080
|
使用https访问(新例子)
1、先做个自签的证书(我们这里不演示CA的例子)
|
1
|
[root@master ingress]# openssl genrsa -out tls.key
2048
|
|
1
|
[root@master ingress]# openssl req -new -x
509
-key tls.key -out tls.crt -subj /C=CN/ST=Beijing/O=DevOps/CN=tomcat.zhixin.com
|
2、通过secret把证书注入到pod中。
|
1
2
|
[root@master ingress]# kubectl create secret tls tomcat-infress-secret --cert=tls.crt --key=tls.key
secret/tomcat-infress-secret created
|
|
1
2
3
4
|
[root@master ingress]# kubectl get secret
NAME TYPE DATA AGE
default-token
-5
r
85
r kubernetes.io/service-account-token
3
17
d
tomcat-ingress-secret kubernetes.io/tls
2
41
s
|
|
1
2
3
4
5
6
7
8
9
10
|
[root@master ingress]# kubectl describe secret tomcat-ingress-secret
Name: tomcat-ingress-secret
Namespace:
default
Labels: <
none
>
Annotations: <
none
>
Type: kubernetes.io/tls
Data
====
tls.crt:
1245
bytes
tls.key:
1679
bytes
|
3、配置ingress为tls方式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@master ingress]# cat ingress-tomcat-tls.yaml
apiVersion: extensions/v
1
beta
1
kind: Ingress
metadata:
name: ingress-tomcat-tls
namespace:
default
#要和deployment和要发布的service处于同一个名称空间
annotations: #这个注解说明我们要用到的ingress-controller是nginx,而不是traefic,enjoy
kubernetes.io/ingress.class:
"nginx"
spec:
tls:
- hosts:
- tomcat.zhixin.com
secretName: tomcat-ingress-secret #kubectl get secret命令查到的名字
rules:
- host: tomcat.zhixin.com #表示访问这个域名,就会转发到后端myapp管理的pod上的服务:
http:
paths:
- path:
backend:
serviceName: tomcat
servicePort:
8080
|
|
1
2
3
4
|
[root@master ingress]# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
ingress-tomcat tomcat.zhixin.com 80 2h
ingress-tomcat-tls tomcat.zhixin.com 80, 443 3m
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
[root@master ingress]# kubectl describe ingress ingress-tomcat-tls
Name: ingress-tomcat-tls
Namespace:
default
Address:
Default backend: default-http-backend:
80
(<
none
>)
TLS:
tomcat-ingress-secret terminates tomcat.zhixin.com
Rules:
Host Path Backends
---- ---- --------
tomcat.zhixin.com
tomcat:
8080
(<
none
>)
Annotations:
kubectl.kubernetes.io/last-applied-configuration: {
"apiVersion"
:
"extensions/v1beta1"
,
"kind"
:
"Ingress"
,
"metadata"
:{
"annotations"
:{
"kubernetes.io/ingress.class"
:
"nginx"
},
"name"
:
"ingress-tomcat-tls"
,
"namespace"
:
"default"
},
"spec"
:{
"rules"
:[{
"host"
:
"tomcat.zhixin.com"
,
"http"
:{
"paths"
:[{
"backend"
:{
"serviceName"
:
"tomcat"
,
"servicePort"
:
8080
},
"path"
:null}]}}],
"tls"
:[{
"hosts"
:[
"tomcat.zhixin.com"
],
"secretName"
:
"tomcat-ingress-secret"
}]}}
kubernetes.io/ingress.class: nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE
4
m nginx-ingress-controller Ingress
default
/ingress-tomcat-tls
|
4、连如ingress-controller查看nginx.conf的配置
|
1
2
3
4
|
[root@master ingress]# kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
default-http-backend
-6586
bc
58
b
6
-qd
9
fk
1
/
1
Running
0
16
h
nginx-ingress-controller
-6
bd
7
c
597
cb-jlqzp
1
/
1
Running
3
16
h
|
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@master ingress]# kubectl exec -n ingress-nginx -it nginx-ingress-controller
-6
bd
7
c
597
cb-jlqzp -- /bin/sh
$ $ cat nginx.conf
## start server tomcat.zhixin.com
server {
server_name tomcat.zhixin.com ;
listen
80
;
set $proxy_upstream_name
"-"
;
listen
443
ssl http
2
;
|
看到有listen 443了。
5、测试https
|
1
|
[root@master ingress]# curl https://tomcat.zhixin.com:
30443
|
部署方法三(利用ingress 的80端口)
前面两种部署方法,是用node ip + 非80端口,访问k8s集群内部的服务。可是,我们实际生产中更希望的是node ip + 80端口的方式,访问k8s集群内的服务。我感觉这个方法最好,下面就就介绍这个方法。
这部分内容参考的是博文http://blog.51cto.com/devingeng/2149377
下载地址
https://github.com/kubernetes/ingress-nginx/archive/nginx-0.11.0.tar.gz
|
1
2
3
4
5
6
7
8
|
ingress-nginx文件位于deploy目录下,各文件的作用:
configmap.yaml:提供configmap可以在线更行nginx的配置
default-backend.yaml:提供一个缺省的后台错误页面
404
namespace.yaml:创建一个独立的命名空间 ingress-nginx
rbac.yaml:创建对应的role rolebinding 用于rbac
tcp-services-configmap.yaml:修改L
4
负载均衡配置的configmap
udp-services-configmap.yaml:修改L
4
负载均衡配置的configmap
with-rbac.yaml:有应用rbac的nginx-ingress-controller组件
|
修改with-rbac.yaml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
apiVersion: extensions/v
1
beta
1
kind: Daemonset
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
spec:
selector:
matchLabels:
app: ingress-nginx
template:
metadata:
labels:
app: ingress-nginx
annotations:
prometheus.io/port:
'10254'
prometheus.io/scrape:
'true'
spec:
serviceAccountName: nginx-ingress-serviceaccount
hostNetwork: true
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:
0.11
.
0
args:
- /nginx-ingress-controller
- --default-backend-service=$(POD_NAMESPACE)/default-http-backend
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --annotations-prefix=nginx.ingress.kubernetes.io
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort:
80
- name: https
containerPort:
443
livenessProbe:
failureThreshold:
3
httpGet:
path: /healthz
port:
10254
scheme: HTTP
initialDelaySeconds:
10
periodSeconds:
10
successThreshold:
1
timeoutSeconds:
1
readinessProbe:
failureThreshold:
3
httpGet:
path: /healthz
port:
10254
scheme: HTTP
periodSeconds:
10
successThreshold:
1
timeoutSeconds:
1
nodeSelector:
custom/ingress-controller-ready:
"true"
|
需要修改的地方:
kind: DaemonSet:官方原始文件使用的是deployment,replicate 为 1,这样将会在某一台节点上启动对应的nginx-ingress-controller pod。外部流量访问至该节点,由该节点负载分担至内部的service。测试环境考虑防止单点故障,改为DaemonSet然后删掉replicate ,配合亲和性部署在制定节点上启动nginx-ingress-controller pod,确保有多个节点启动nginx-ingress-controller pod,后续将这些节点加入到外部硬件负载均衡组实现高可用性。
hostNetwork: true:添加该字段,暴露nginx-ingress-controller pod的服务端口(80)
nodeSelector: 增加亲和性部署,有custom/ingress-controller-ready 标签的节点才会部署该DaemonSet
为需要部署nginx-ingress-controller的节点设置lable
|
1
2
3
|
kubectl label nodes vmnode
2
custom/ingress-controller-ready=true
kubectl label nodes vmnode
3
custom/ingress-controller-ready=true
kubectl label nodes vmnode
4
custom/ingress-controller-ready=true
|
加载yaml文件
|
1
2
3
4
5
6
7
|
kubectl apply -f namespace.yaml
kubectl apply -f default-backend.yaml
kubectl apply -f configmap.yaml
kubectl apply -f tcp-services-configmap.yaml
kubectl apply -f udp-services-configmap.yaml
kubectl apply -f rbac.yaml
kubectl apply -f with-rbac.yaml
|
查看pod是否正常创建
##下载镜像可能会比较慢,等待一会所有pod都是Running状态,按Ctrl + c 退出
|
1
2
3
4
5
6
|
[root@vmnode
1
deploy]# kubectl get pods --namespace=ingress-nginx --watch
NAME READY STATUS RESTARTS AGEdefault-
http-backend
-6
c
59748
b
9
b-hc
8
q
9
1
/
1
Running
0
6
m
nginx-ingress-controller
-7
fmlp
1
/
1
Running
1
13
d
nginx-ingress-controller-j
95
fb
1
/
1
Running
1
13
d
nginx-ingress-controller-ld
2
jw
1
/
1
Running
1
13
d
|
测试ingress
创建一个tomcat的Service
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
[root@k
8
s-master
1
test]# cat mytomcat.yaml
apiVersion: extensions/v
1
beta
1
kind: Deployment
metadata:
name: mytomcat
spec:
replicas:
2
template:
metadata:
labels:
run: mytomcat
spec:
containers:
- name: mytomcat
image: tomcat
ports:
- containerPort:
8080
---
apiVersion: v
1
kind: Service
metadata:
name: mytomcat
labels:
run: mytomcat
spec:
type: NodePort
ports:
- port:
8080
targetPort:
8080
selector:
run: mytomcat
|
|
1
|
[root@k
8
s-master
1
test]# kubectl apply -f mytomcat.yaml
|
配置ingress转发文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@k
8
s-master
1
test]# cat test-ingress.yaml
apiVersion: extensions/v
1
beta
1
kind: Ingress
metadata:
name: test-ingress
namespace:
default
spec:
rules:
- host: test.zhixin.com
http:
paths:
- path: /
backend:
serviceName: mytomcat
servicePort:
8080
|
host: 对应的域名
path: url上下文
backend:后向转发 到对应的 serviceName: servicePort:
|
1
2
|
[root@k
8
s-master
1
test]# kubectl apply -f test-ingress.yaml
ingress.extensions/test-ingress created
|
nginx-ingress-controller运行在node1和nod2两个节点上。如果网络中有dns服务器,在dns中把这两个域名映射到nginx-ingress-controller运行的任意一个节点上,如果没有dns服务器只能修改host文件了。
正规的做法是在node1和node2这两个节点上安装keepalive,生成一个vip。在dns上把域名和vip做映射。
我这里直接在node1节点上操作了:
我这里node1节点的ip是172.16.22.201;node2节点的ip是172.16.22.202
|
1
2
|
[root@k
8
s-master
1
test]# echo
" 172.16.22.201 test.zhixin.com"
>> /etc/hosts
[root@k
8
s-master
1
test]# echo
"172.16.22.202 test.zhixin.com"
>> /etc/hosts
|
然后访问测试:

看到,我们把域名test.zhixin.com绑定到Node节点的ip补上,然后我们直接访问http://test.zhixin.com,就能访问到k8s集群里面的pod服务。
(7)Ingress Controller及部署
(8)Ingress使用案例:发布http及https的tomcat服务
六、K8S-存储卷
(1)存储卷及其功用
(2)常见的存储卷类型及应用:emptyDir、hostPath、nfs、glusterfs等
(3)PV及PVC
(4)StorageClass及PV的动态供给
(5)ConfigMap
(6)Secret
七、StatefulSet
(1)有状态及无状态应用对比
(2)有状态应用的容器难题
(3)StatefulSet及其应用
(4)案例
八、网络模型及网络策略
(1)flannel工作原理及host-gw等实现方式
(2)calico及其应用
(3)网络策略及其工作机制
(4)基于calico的网络策略的实现
九、认证、授权及准入控制
(1)Kubernetes的认证、授权及准入控制机制
(2)ServiceAccount
(3)令牌认证及证书认证
(4)RBAC及其实现机制
(5)Role和RoleBinding
(6)ClusterRole和ClusterRoleBinding
十、调度器
(1)资源需求、资源限额及其应用
(2)Pod优选级类别
(3)Pod调度器工作原理
(4)预选及预选策略
(5)优选及优选算法
(6)高级调度方法
十一、资源监控及HPA(陆续上传)
(1)HeapSter、InfluxDB及Grafana实现资源监控
(2)HPA v1
(3)Prometheus及Grafana实现资源监控
(4)Metrics-Server
(5)HPA v2
十二、helm及日志收集系统(陆续上传)
(1)helm工作原理
(2)helm部署及其应用
(3)部署efk日志收集系统
十三、基于Kubernetes的DevOps介绍 (陆续上传)