为elastic添加中文分词
添加中文分词
可以直接使用配置好的es中文版: https://github.com/medcl/elasticsearch-rtf
可以可以自己集成中文分词组件,medcl为es写了三个中文分词插件,一个是ik的,一个是mmseg的,一个是pinyin4j的。
下面介绍这三个插件与es的集成:
1.ik与es的集成
1.1下载
https://github.com/medcl/elasticsearch-analysis-ik
1.2编译
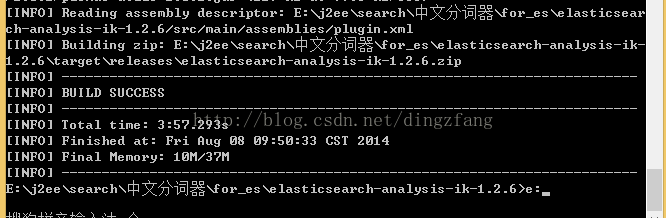
解压下载的elasticsearch-analysis-ik-1.2.6.zip
编译
在cmd下编译
Windows开始菜单---》运行-----》cmd-----》回车
e:
cd E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-ik-1.2.6
E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-ik-1.2.6>E:\j2ee\maven\apache-maven-3.1.1-bin\apache-maven-3.1.1\bin\mvn package


1.3配置
1.3.1在%ES_HOME%目录下新建目录/plugins/analysis-ik
mkdir -p /usr/local/search/elasticsearch-1.3.1/plugins/analysis-ik

1.3.2将elasticsearch-analysis-ik-1.2.6.jar拷贝到目录/usr/local/search/elasticsearch-1.3.1 /plugins/analysis-ik下

1.3.3将解压elasticsearch-analysis-ik-1.2.6.zip后的config/ik目录拷贝到/usr/local/search/elasticsearch-1.3.1 /config/目录下

1.3.4修改elasticsearch.yml
vi /usr/local/search/elasticsearch-1.3.1 /config/elasticsearch.yml
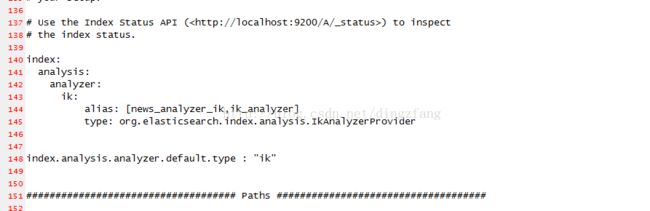
index:
analysis:
analyzer:
ik:
alias: [news_analyzer_ik,ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
index.analysis.analyzer.default.type : "ik"
1.3.5IKAnalyzer.cfg.xml
可以在/usr/local/search/elasticsearch-1.3.1/config/ik /IKAnalyzer.cfg.xml中配置一些扩展的词库字典,以及一些停用词词库字典
vi /usr/local/search/elasticsearch-1.3.1/config/ik /IKAnalyzer.cfg.xml
1.3.6
重启es
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch stop
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch start
1.4测试
1.4.1创建mapping,指定使用中文分词器
/**
* 创建类型映射关系,使用中文分词器
* 注意:在定义mapping之前,需要先创建一个index库
* @param client
* @throws IOException
*/
public static void mapping4CN(Client client) throws IOException{
XContentBuilder mapping=XContentFactory.jsonBuilder().startObject().startObject("fulltext")
.startObject("_all").field("indexAnalyzer","ik").field("searchAnalyzer","ik").field("term_vector","no").field("store","false").endObject()
.startObject("properties")
.startObject("content").field("type","string").field("store","no").field("term_vector","with_positions_offsets").field("indexAnalyzer","ik").field("searchAnalyzer","ik").field("include_in_all","true").field("boost",8).endObject()
.endObject()
.endObject().endObject();
System.out.println(mapping.string());
//注意:在定义mapping之前,需要先创建一个index库
//创建索引库
if(!indexExist(client,"cnindex")){
CreateIndexResponse ciresponse=client.admin().indices().prepareCreate("cnindex").execute().actionGet();
System.out.println("CreateIndexResponse---->"+ciresponse.isAcknowledged());
}
//创建Mapping(需要指定索引库名称)
PutMappingRequestBuilder pmrbuilder=client.admin().indices().preparePutMapping("cnindex").setType("fulltext").setSource(mapping);
PutMappingResponse pmResponse=pmrbuilder.execute().actionGet();
System.out.println("PutMappingResponse---->"+pmResponse.isAcknowledged());
}
1.4.2创建中文索引
/**
* 为中文内容创建索引
* @param client
* @throws IOException
*/
public static void createIndex4CN(Client client) throws IOException{
XContentBuilder doc1=XContentFactory.jsonBuilder().startObject()
.field("content", "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船")
.endObject();
XContentBuilder doc2=XContentFactory.jsonBuilder().startObject()
.field("content", "美国留给伊拉克的是个烂摊子吗")
.endObject();
XContentBuilder doc3=XContentFactory.jsonBuilder().startObject()
.field("content", "公安部:各地校车将享最高路权")
.endObject();
XContentBuilder doc4=XContentFactory.jsonBuilder().startObject()
.field("content", "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首")
.endObject();
/**
* 其中第一个参数productIndex为索引库名,一个es集群中可以有多个索引库。
* 第二个参数productIndexType为索引类型,是用来区分同索引库下不同类型的数据的,一个索引库下可以有多个索引类型。
* 第三个参数productIndexId为document的id
*/
IndexRequestBuilder irbuilder1= client.prepareIndex("cnindex", "cnindextype","cnindexid1").setRefresh(true).setSource(doc1);
IndexRequestBuilder irbuilder2= client.prepareIndex("cnindex", "cnindextype","cnindexid2").setRefresh(true).setSource(doc2);
IndexRequestBuilder irbuilder3= client.prepareIndex("cnindex", "cnindextype","cnindexid3").setRefresh(true).setSource(doc3);
IndexRequestBuilder irbuilder4= client.prepareIndex("cnindex", "cnindextype","cnindexid4").setRefresh(true).setSource(doc4);
BulkRequestBuilder brbuilder=client.prepareBulk();
brbuilder.add(irbuilder1);
brbuilder.add(irbuilder2);
brbuilder.add(irbuilder3);
brbuilder.add(irbuilder4);
BulkResponse response=brbuilder.execute().actionGet();
System.out.println(response);
}
1.4.3执行中文搜索
/**
* 执行中文搜索
* @param client
*/
public static void search4CN(Client client){
//构造查询条件
//TermQuery
QueryBuilder qb1=QueryBuilders.termQuery("content", "伊拉克");
/**
QueryBuilder qb2=QueryBuilders.boolQuery().must(QueryBuilders.termQuery("content", "中国"))
.must(QueryBuilders.termQuery("content", "中国"))
.mustNot(QueryBuilders.termQuery("onSale", false))
.should(QueryBuilders.termQuery("type", 1));
QueryBuilder db3=QueryBuilders.filteredQuery(QueryBuilders.termQuery("content", "中国"),
FilterBuilders.rangeFilter("price").from(30.0).to(500.0).includeLower(true).includeUpper(false));
*/
SearchResponse response= client.prepareSearch("cnindex").setTypes("cnindextype").setQuery(qb1).setFrom(0).setSize(15).addHighlightedField("content").setHighlighterPreTags("").setHighlighterPostTags("").setExplain(true).execute().actionGet();
SearchHits shits=response.getHits();
SearchHit[] shs= shits.hits();
for(SearchHit sh: shs ){
String content=(String) sh.getSource().get("content");
System.out.println("content="+content);
}
}
2.mmseg与es的集成
2.1下载
https://github.com/medcl/elasticsearch-analysis-mmseg
2.2编译
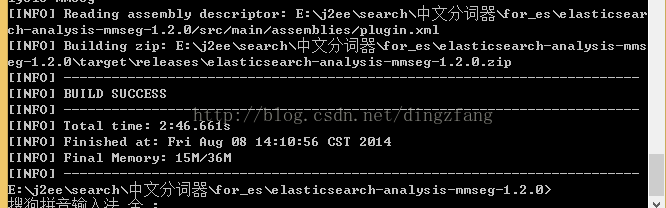
解压下载的elasticsearch-analysis-mmseg-1.2.0.zip
编译
在cmd下编译
Windows开始菜单---》运行-----》cmd-----》回车
e:
cd E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-mmseg-1.2.0
E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-mmseg-1.2.0>E:\j2ee\maven\apache-maven-3.1.1-bin\apache-maven-3.1.1\bin\mvn package

2.3配置
2.3.1在%ES_HOME%目录下新建目录/plugins/
analysis-mmseg
mkdir -p /usr/local/search/elasticsearch-1.3.1/plugins/
analysis-mmseg
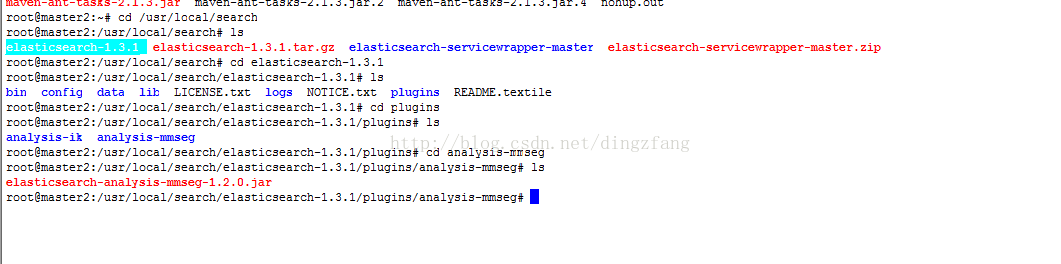
2.3.2将elasticsearch-analysis-mmseg-1.2.0.jar拷贝到目录/usr/local/search/elasticsearch-1.3.1/plugins/
analysis-mmseg下
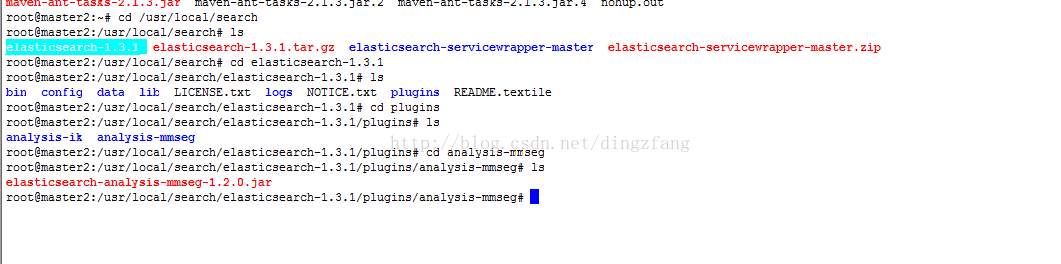
2.3.3将解压elasticsearch-analysis-mmseg-1.2.0.zip后的config\mmseg目录拷贝到/usr/local/search/elasticsearch-1.3.1/config/目录下
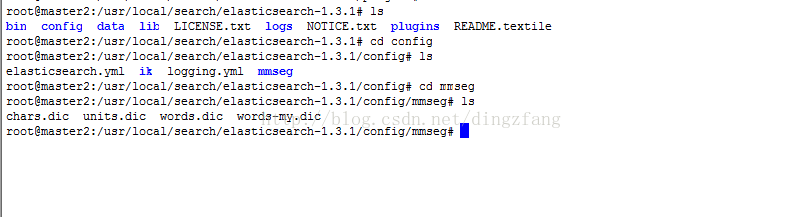
2.3.4修改elasticsearch.yml
vi /usr/local/search/elasticsearch-1.3.1 /config/elasticsearch.yml
index:
analysis:
analyzer:
ik:
alias: [news_analyzer_ik,ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
mmseg:
alias: [news_analyzer, mmseg_analyzer]
type: org.elasticsearch.index.analysis.MMsegAnalyzerProvider
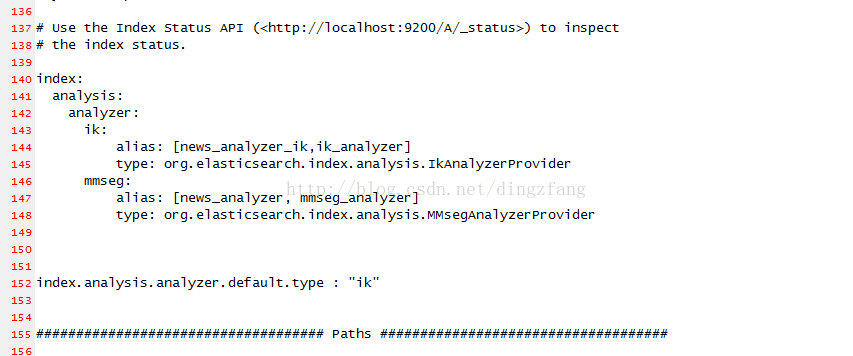
2.3.5重启es
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch stop
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch start
2.4测试
2.4.1创建mapping,指定使用中文分词器
/**
* 创建类型映射关系,使用中文分词器mmseg
* 注意:在定义mapping之前,需要先创建一个index库
* @param client
* @throws IOException
*/
public static void mapping4CN_MMSEG(Client client) throws IOException{
XContentBuilder mapping=XContentFactory.jsonBuilder().startObject().startObject("fulltext_mmseg")
.startObject("_all").field("indexAnalyzer","mmseg").field("searchAnalyzer","mmseg").field("term_vector","no").field("store","true").endObject()
.startObject("properties")
.startObject("content").field("type","string").field("store","yes").field("term_vector","with_positions_offsets").field("indexAnalyzer","mmseg").field("searchAnalyzer","mmseg").field("include_in_all","true").field("boost",8).endObject()
.endObject()
.endObject().endObject();
System.out.println(mapping.string());
//注意:在定义mapping之前,需要先创建一个index库
//创建索引库
if(!indexExist(client,"cnindex_mmseg")){
CreateIndexResponse ciresponse=client.admin().indices().prepareCreate("cnindex_mmseg").execute().actionGet();
System.out.println("CreateIndexResponse---->"+ciresponse.isAcknowledged());
}
//创建Mapping(需要指定索引库名称)
PutMappingRequestBuilder pmrbuilder=client.admin().indices().preparePutMapping("cnindex_mmseg").setType("fulltext_mmseg").setSource(mapping);
PutMappingResponse pmResponse=pmrbuilder.execute().actionGet();
System.out.println("PutMappingResponse---->"+pmResponse.isAcknowledged());
}
2.4.2创建中文索引
/**
* 为中文内容创建索引
* @param client
* @throws IOException
*/
public static void createIndex4CN_MMSEG(Client client) throws IOException{
XContentBuilder doc1=XContentFactory.jsonBuilder().startObject()
.field("content", "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船")
.endObject();
XContentBuilder doc2=XContentFactory.jsonBuilder().startObject()
.field("content", "美国留给伊拉克的是个烂摊子吗")
.endObject();
XContentBuilder doc3=XContentFactory.jsonBuilder().startObject()
.field("content", "公安部:各地校车将享最高路权")
.endObject();
XContentBuilder doc4=XContentFactory.jsonBuilder().startObject()
.field("content", "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首")
.endObject();
/**
* 其中第一个参数productIndex为索引库名,一个es集群中可以有多个索引库。
* 第二个参数productIndexType为索引类型,是用来区分同索引库下不同类型的数据的,一个索引库下可以有多个索引类型。
* 第三个参数productIndexId为document的id
*/
IndexRequestBuilder irbuilder1= client.prepareIndex("cnindex_mmseg", "cnindextype_mmseg","cnindexid_mmseg1").setRefresh(true).setSource(doc1);
IndexRequestBuilder irbuilder2= client.prepareIndex("cnindex_mmseg", "cnindextype_mmseg","cnindexid_mmseg2").setRefresh(true).setSource(doc2);
IndexRequestBuilder irbuilder3= client.prepareIndex("cnindex_mmseg", "cnindextype_mmseg","cnindexid_mmseg3").setRefresh(true).setSource(doc3);
IndexRequestBuilder irbuilder4= client.prepareIndex("cnindex_mmseg", "cnindextype_mmseg","cnindexid_mmseg4").setRefresh(true).setSource(doc4);
BulkRequestBuilder brbuilder=client.prepareBulk();
brbuilder.add(irbuilder1);
brbuilder.add(irbuilder2);
brbuilder.add(irbuilder3);
brbuilder.add(irbuilder4);
BulkResponse response=brbuilder.execute().actionGet();
System.out.println(response);
}
2.4.3执行中文搜索
/**
* 执行中文搜索
* @param client
*/
public static void search4CN_MMSEG(Client client){
//构造查询条件
//TermQuery
QueryBuilder qb1=QueryBuilders.termQuery("content", "校车");
/**
QueryBuilder qb2=QueryBuilders.boolQuery().must(QueryBuilders.termQuery("content", "中国"))
.must(QueryBuilders.termQuery("content", "中国"))
.mustNot(QueryBuilders.termQuery("onSale", false))
.should(QueryBuilders.termQuery("type", 1));
QueryBuilder db3=QueryBuilders.filteredQuery(QueryBuilders.termQuery("content", "中国"),
FilterBuilders.rangeFilter("price").from(30.0).to(500.0).includeLower(true).includeUpper(false));
*/
SearchResponse response= client.prepareSearch("cnindex_mmseg").setTypes("cnindextype_mmseg").setQuery(qb1).setFrom(0).setSize(15).addHighlightedField("content").setHighlighterPreTags("").setHighlighterPostTags("").setExplain(true).execute().actionGet();
SearchHits shits=response.getHits();
SearchHit[] shs= shits.hits();
for(SearchHit sh: shs ){
String content=(String) sh.getSource().get("content");
System.out.println("content="+content);
}
}
3.pinyin4j与es的集成
3.1下载
https://github.com/medcl/elasticsearch-analysis-pinyin
3.2编译
解压下载的
编译
在cmd下编译
Windows开始菜单---》运行-----》cmd-----》回车
e:
cd E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-pinyin-1.2.2
E:\j2ee\search\中文分词器\for_es\elasticsearch-analysis-pinyin-1.2.2>E:\j2ee\maven\apache-maven-3.1.1-bin\apache-maven-3.1.1\bin\mvn package

3.3配置
3.3.1在%ES_HOME%目录下新建目录/plugins/
analysis-pinyin
mkdir -p /usr/local/search/elasticsearch-1.3.1/plugins/
analysis-pinyin

3.3.2将lib/pinyin4j-2.5.0.jar和target/elasticsearch-analysis-pinyin-1.2.2.jar拷贝到目录/usr/local/search/elasticsearch-1.3.1/plugins/analysis-pinyin下

2.3.4修改elasticsearch.yml
vi /usr/local/search/elasticsearch-1.3.1/config/elasticsearch.yml
index:
analysis:
analyzer:
ik:
alias: [news_analyzer_ik,ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
mmseg:
alias: [news_analyzer_mmseg, mmseg_analyzer]
type: org.elasticsearch.index.analysis.MMsegAnalyzerProvider
pinyin:
alias: [news_analyzer_pinyin, pinyin_analyzer]
type: org.elasticsearch.index.analysis.PinyinAnalyzerProvider
index.analysis.analyzer.default.type : "ik"
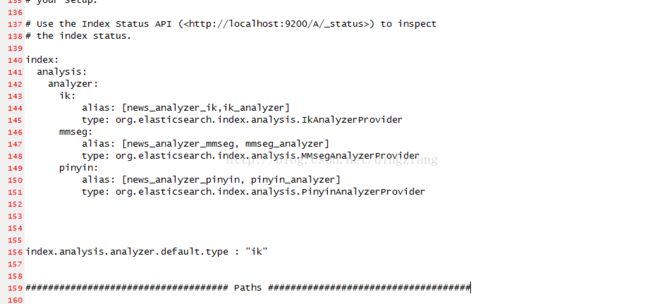
3.3.5重启es
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch stop
/usr/local/search/elasticsearch-1.3.1/bin/service/elasticsearch start
3.4测试
2.4.1创建mapping,指定使用中文分词器
3.4.2创建中文索引
3.4.3执行中文搜索