目录
redis源码分析系列文章
前言
API使用
embstr和raw的区别
SDSHdr的定义
SDS具体逻辑图
SDS的优势
更快速的获取字符串长度
数据安全,不会截断
SDS关键代码分析
获取常见值(抽象出常见方法)
创建对象
删除
添加字符(扩容)重点!!!
总结
参考资料
redis源码分析系列文章
[Redis源码系列]在Liunx安装和常见API
为什么要从Redis源码分析
前言
上篇我们已经了解了Redis是什么,在Linux上如何安装,常见的数据类型和API使用,如果有不明白的,可以移步到主页。
Redis是使用C写的,而C中根本不存在string,list,hash,set和zset这些数据类型,那么C是如何将这些数据类型实现出来的呢?我们从该篇开始,就要开始分析源码啦。
API使用
我们这篇来学习string的底层实现,首先看下API的简单应用,设置str1变量为helloworld,然后我们使用debug object +变量名的方式看下,注意标红的编码为embstr。

![]()
如果我们将str2设置为helloworldhelloworldhelloworldhelloworldhell,字符长度为44,再使用下debug object+变量名的方式看下,注意标红的编码为embstr。

![]()
但是当我们设置为helloworldhelloworldhelloworldhelloworldhello,字符长度为45,再使用debug object+变量名的方式看下,注意标红的编码为raw。

![]()
最后我们将str3设置为整数100,再使用debug object+变量名的方式看下,注意标红的编码为int。

![]()
所以Redis的string类型一共有三种存储方式,当字符串长度小于等于44,底层采用embstr;当字符串长度大于44,底层采用raw;当设置是整数,底层则采用int。
embstr和raw的区别
所有类型的数据结构最外层都是RedisObject,这部分会说,先这样大致了解下,因为这篇的重点不在这。如果字符串小于等于44,实际的数据和RedisObject在内存中地址相邻,如下图。
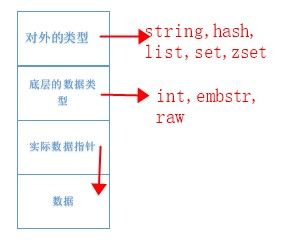
![]()
如果字符串大于44,实际的数据和RedisObject在内存中地址不相邻,如下图。
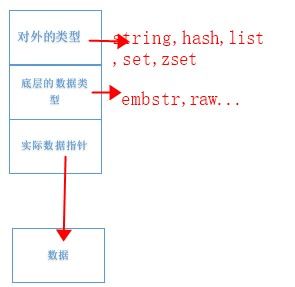
![]()
再次强调,这些不重要,以后会讲,现在提下,只是为了能让Redis的String类型有个大致了解,先从整体把握。我们今天要说的其实是实际的数据,即上图指针指向的位置。
SDSHdr的定义
其实的数据并不是直接存储,也有封装,看下面的代码就知道分为五种,分别是sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64。sdshdr5和另外四种的区别比较明显,sdshrd5其实对内存空间的更加节约。其他四种乍一看都差不多,包括已用长度len,总长度alloc,标记flags(感觉没啥用,要是有知道的小伙伴,欢迎指教),实际数据buf。
//定义五种不同的结构体,sdshdr5,sdshdr8, sdshdr16,sdshdr32,sdshdr64 struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; // 8位的标记 char buf[];//实际数据的指针 }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* 已使用长度 */ uint8_t alloc; /* 总长度*/ unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; uint64_t alloc; unsigned char flags; char buf[]; };
SDS具体逻辑图
假设我们设置某个字符串为hello,那么他SDS的可用长度len为8,已用长度len为6,如下图。注意:Redis会根据具体的字符长度,选择相应的sdshdr,但是各个类型都差不多,所以下图加简单画了。

![]()
SDS的优势
我们可以看到是对字符数组的再封装,但是为什么呢,直接使用字符数组不是更简单吗?这要从C和Java语言的根本区别说起。
更快速的获取字符串长度
我们都知道Java的字符串有提供length方法,列表有提供size方法,我们可以直接获取大小。但是C却不一样,更偏向底层实现,所以没有直接的方法使用。这样就带来一个问题,如果我们想要获取某个数组的长度,就只能从头开始遍历,当遇到第一个'\0'则表示该数组结束。这样的速度太慢了,不能每次因为要获取长度就变量数组。所以设计了SDS数据结构,在原来的字符数组外面增加总长度,和已用长度,这样每次直接获取已用长度即可。复杂度为O(1)。
数据安全,不会截断
如果传统字符串保存图片,视频等二进制文件,中间可能出现'\0',如果按照原来的逻辑,会造成数据丢失。所以可以用已用长度来表示是否字符数组已结束。
SDS关键代码分析
获取常见值(抽象出常见方法)
在sds.h中写了一些常见方法,比如计算sds的长度(即sdshdr的len),计算sds的空闲长度(即sdshdr的可用长度alloc-已用长度len),计算sds的可用长度(即sdshdr的alloc)等等。但是大家有没有疑问,这不是一行代码搞定的事吗,为啥要抽象出方法呢?那么问题在于在上面,我们有将sdshdr分为五种类型,分别是sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64。那么我们在实际使用的时候,想要区分当前是哪个类型,并取其相应字段或设置相应字段。
//计算sds对应的字符串长度,其实上取得是字符串所对应的哪种sdshdr的len值 static inline size_t sdslen(const sds s) { // 柔性数组不占空间,所以倒数第二位的是flags unsigned char flags = s[-1]; //flags与上面定义的宏变量7做位运算 switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5://0 return SDS_TYPE_5_LEN(flags); case SDS_TYPE_8://1 return SDS_HDR(8,s)->len;//取上面结构体sdshdr8的len case SDS_TYPE_16://2 return SDS_HDR(16,s)->len; case SDS_TYPE_32://3 return SDS_HDR(32,s)->len; case SDS_TYPE_64://5 return SDS_HDR(64,s)->len; } return 0; } //计算sds对应的空余长度,其实上是alloc-len static inline size_t sdsavail(const sds s) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { return 0; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); return sh->alloc - sh->len; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); return sh->alloc - sh->len; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); return sh->alloc - sh->len; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); return sh->alloc - sh->len; } } return 0; } //设置sdshdr的len static inline void sdssetlen(sds s, size_t newlen) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { unsigned char *fp = ((unsigned char*)s)-1; *fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS); } break; case SDS_TYPE_8: SDS_HDR(8,s)->len = newlen; break; case SDS_TYPE_16: SDS_HDR(16,s)->len = newlen; break; case SDS_TYPE_32: SDS_HDR(32,s)->len = newlen; break; case SDS_TYPE_64: SDS_HDR(64,s)->len = newlen; break; } } //给sdshdr的len添加多少大小 static inline void sdsinclen(sds s, size_t inc) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { unsigned char *fp = ((unsigned char*)s)-1; unsigned char newlen = SDS_TYPE_5_LEN(flags)+inc; *fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS); } break; case SDS_TYPE_8: SDS_HDR(8,s)->len += inc; break; case SDS_TYPE_16: SDS_HDR(16,s)->len += inc; break; case SDS_TYPE_32: SDS_HDR(32,s)->len += inc; break; case SDS_TYPE_64: SDS_HDR(64,s)->len += inc; break; } } //获取sdshdr的总长度 static inline size_t sdsalloc(const sds s) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: return SDS_TYPE_5_LEN(flags); case SDS_TYPE_8: return SDS_HDR(8,s)->alloc; case SDS_TYPE_16: return SDS_HDR(16,s)->alloc; case SDS_TYPE_32: return SDS_HDR(32,s)->alloc; case SDS_TYPE_64: return SDS_HDR(64,s)->alloc; } return 0; } //设置sdshdr的总长度 static inline void sdssetalloc(sds s, size_t newlen) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: /* Nothing to do, this type has no total allocation info. */ break; case SDS_TYPE_8: SDS_HDR(8,s)->alloc = newlen; break; case SDS_TYPE_16: SDS_HDR(16,s)->alloc = newlen; break; case SDS_TYPE_32: SDS_HDR(32,s)->alloc = newlen; break; case SDS_TYPE_64: SDS_HDR(64,s)->alloc = newlen; break; } }
创建对象
我们通过sdsnew方法来创建对象,显示通过判断init是否为空来确定初始大小,接着调用方法sdsnew(这边方法名一样,但是参数不一样,其为方法的重载),先根据长度确定类型(上面有提过五种类型,不记得的可以往上翻),然后根据类型分配相应的内存资源,最后追加C语言的结尾符'\0'。
sds sdsnew(const char *init) { size_t initlen = (init == NULL) ? 0 : strlen(init); return sdsnewlen(init, initlen); } sds sdsnewlen(const void *init, size_t initlen) { void *sh; sds s; char type = sdsReqType(initlen);//根据长度确定类型 /*空字符串,用sdshdr8,这边是经验写法,当想构造空串是为了放入超过32长度的字符串 */ if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; int hdrlen = sdsHdrSize(type);//到下一个方法,已经把他们放在一起了 unsigned char *fp; /* flags pointer. */ //分配内存 sh = s_malloc(hdrlen+initlen+1); if (!init) memset(sh, 0, hdrlen+initlen+1); if (sh == NULL) return NULL; s = (char*)sh+hdrlen; fp = ((unsigned char*)s)-1; //根据不同的类型,创建不同结构体,调用SDS_HDR_VAR函数 //为不同的结构体赋值,如已用长度len,总长度alloc switch(type) { case SDS_TYPE_5: { *fp = type | (initlen << SDS_TYPE_BITS); break; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); sh->len = initlen; sh->alloc = initlen; *fp = type; break; } } if (initlen && init) memcpy(s, init, initlen); //最后追加'\0' s[initlen] = '\0'; return s; } //根据实际字符长度确定类型 static inline char sdsReqType(size_t string_size) { if (string_size < 1<<5) return SDS_TYPE_5; if (string_size < 1<<8) return SDS_TYPE_8; if (string_size < 1<<16) return SDS_TYPE_16; #if (LONG_MAX == LLONG_MAX) if (string_size < 1ll<<32) return SDS_TYPE_32; #endif return SDS_TYPE_64; }
删除 String类型的删除并不是直接回收内存,而是修改字符,让其为空字符,这其实是惰性释放,等待将来使用。在调用sdsempty方法时,再次调用上面的sdsnewlen方法。/*修改sds字符串使其为空(零长度)。 *但是,所有现有缓冲区不会被丢弃,而是设置为可用空间 *这样,下一个append操作将不需要分配到 *当要缩短SDS保存的字符串时,程序并不立即使用内存充分配来回收缩短后多出来的字节,并等待将来使用。 void sdsclear(sds s) { sdssetlen(s, 0); s[0] = '\0'; } sds sdsempty(void) { return sdsnewlen("",0); }
添加字符(扩容)重点!!!
添加字符串,sdscat输入参数为sds和字符串t,首先调用sdsMakeRoomFor扩容方法,再追加新的字符串,最后添加上结尾符'\0'。我们来看下扩容方法里面是如何实现的?第一步先调用常见方法中的sdsavail方法,获取还剩多少空闲空间。如果空闲空间大于要添加的字符串t的长度,则直接返回,不想要扩容。如果空闲空间不够,则想要扩容。第二步判断想要扩容多大,这边有分情况,如果目前的字符串小于1M,则直接扩容双倍,如果目前的字符串大于1M,则直接添加1M。第三个判断添加字符串之后的数据类型还是否和原来的一致,如果一致,则没啥事。如果不一致,则想要新建一个sdshdr,把现有的数据都挪过去。
这样是不是有点抽象,举个例子,现在str的字符串为hello,目前是sdshdr8,总长度50,已用6,空闲44。现在想要添加长度为50的字符t,第一步想要看下是否要扩容,50明显大于44,需要扩容。第二步扩容多少,str的长度小于1M,所以扩容双倍,新的长度为50*2=100。第三步50+50所对应sdshdr类型还是sdshdr8吗?明显还是sdshdr8,所以不要数据迁移,还在原来的基础上添加t即可。
总结
该篇主要讲了Redis的底层实现SDS,包括SDS是什么,与传统的C语言相比的优势,具体的逻辑图,常见的方法(包括创建,删除,扩容等)。同时也知道了Redis的embstr和raw的区别。如果觉得写得还行,麻烦给个赞,您的认可才是我写作的动力!
如果觉得有说的不对的地方,欢迎评论指出。
好了,拜拜咯。
参考资料
【Redis源码分析】一个对SDSHDR5是否使用的疑问
如何阅读 Redis 源码?