代码详解:如何用Python快速制作美观、炫酷且有深度的图表

全文共12231字,预计学习时长35分钟
 生活阶梯(幸福指数)与人均GDP(金钱)正相关的正则图
生活阶梯(幸福指数)与人均GDP(金钱)正相关的正则图
本文将探讨三种用Python可视化数据的不同方法。 以可视化 《2019年世界幸福报告》 的数据为例,本文用Gapminder和Wikipedia的信息丰富了《世界幸福报告》数据,以探索新的数据关系和可视化方法。 《世界幸福报告》试图回答世界范围内影响幸福的因素。 报告根据对“坎特里尔阶梯问题”的回答来确定幸福指数,被调查者需对自己的生活状况进行打分,10分为最佳状态,0分为最差。 本文将使用Life Ladder作为目标变量。 Life Ladder就是指幸福指数。 文章结构
 图片来源:Nik MacMillan/Unsplash
本文旨在提供代码指南和参考点,以便在查找特定类型的图表时进行参考。
为了节省空间,有时会将多个图表合并到一张图上。
但是请放心,你可以在这个
Repo
或相应的
Jupyter
Notebook中找到所有基本代码。
目录
· 我使用
Python
进行绘图的经历
·
分布的重要性
·
加载数据和包导入
·
迅速:
使用Pandas
进行基本绘图
·
美观:
使用Seaborn
进行高级绘图
·
精彩:
用plotly创造精彩的互动情节
图片来源:Nik MacMillan/Unsplash
本文旨在提供代码指南和参考点,以便在查找特定类型的图表时进行参考。
为了节省空间,有时会将多个图表合并到一张图上。
但是请放心,你可以在这个
Repo
或相应的
Jupyter
Notebook中找到所有基本代码。
目录
· 我使用
Python
进行绘图的经历
·
分布的重要性
·
加载数据和包导入
·
迅速:
使用Pandas
进行基本绘图
·
美观:
使用Seaborn
进行高级绘图
·
精彩:
用plotly创造精彩的互动情节

1. 我使用Python进行绘图的经历
 图片来源:Krys Amon/Unsplash
大约两年前,我开始更认真地学习Python。
从那时起,Python几乎每周都会给我一些惊喜,它不仅自身简单易用,而且其生态系统中还有很多令人惊叹的开源库。
我对命令、模式和概念越熟悉,就越能充分利用其功能。
Matplotlib
与用Python绘图正好相反。
最初,我用matplotlib创建的几乎每个图表看起来都很过时。
更糟糕的是,为了创建这些讨厌的东西,我不得不在Stackoverflow上花费数小时。
例如,研究改变x斜度的基本命令或者类似这些的蠢事。
我一点也不想做多图表。
以编程的方式创建这些图表是非常奇妙的,例如,一次生成50个不同变量的图表,结果令人印象深刻。
然而,其中涉及大量的工作,需要记住一大堆无用的指令。
Seaborn
学习
Seaborn
能够节省很多精力。
Seaborn可以抽象出大量的微调。
毫无疑问,这使得图表在美观上得到巨大的改善。
然而,它也是构建在matplotlib之上的。
通常,对于非标准的调整,仍然有必要使用机器级的matplotlib代码。
Bokeh
一时间,我以为
Bokeh
会成为一个后援解决方案。
我在做地理空间可视化的时候发现了Bokeh。
然而,我很快就意识到,虽然Bokeh有所不同,但还是和matplotlib一样复杂。
Plotly
不久前我确实尝试过
plot.ly
(后面就直接用plotly来表示)同样用于地理空间可视化。
那个时候,plotly比前面提到的库还要麻烦。
它必须通过笔记本账户登录,然后plotly可以在线呈现,接着下载最终图表。
我很快就放弃了。
但是,我最近看到了一个关于plotlyexpress和plotly4.0的
Youtube视
频,重点是,他们把那些在线的废话都删掉了。
我尝试了一下,本篇文章就是尝试的成果。
我想,知道得晚总比不知道的好。
Kepler.gl (地理空间数据优秀奖)
Kepler.gl
不是一个Python库,而是一款强大的基于web的地理空间数据可视化工具。
只需要CSV文件,就可以使用Python轻松地创建文件。
试试吧!
当前工作流程
最后,我决定使用Pandas本地绘图进行快速检查,并使用Seaborn绘制要在报告和演示中使用的图表(视觉效果很重要)。
图片来源:Krys Amon/Unsplash
大约两年前,我开始更认真地学习Python。
从那时起,Python几乎每周都会给我一些惊喜,它不仅自身简单易用,而且其生态系统中还有很多令人惊叹的开源库。
我对命令、模式和概念越熟悉,就越能充分利用其功能。
Matplotlib
与用Python绘图正好相反。
最初,我用matplotlib创建的几乎每个图表看起来都很过时。
更糟糕的是,为了创建这些讨厌的东西,我不得不在Stackoverflow上花费数小时。
例如,研究改变x斜度的基本命令或者类似这些的蠢事。
我一点也不想做多图表。
以编程的方式创建这些图表是非常奇妙的,例如,一次生成50个不同变量的图表,结果令人印象深刻。
然而,其中涉及大量的工作,需要记住一大堆无用的指令。
Seaborn
学习
Seaborn
能够节省很多精力。
Seaborn可以抽象出大量的微调。
毫无疑问,这使得图表在美观上得到巨大的改善。
然而,它也是构建在matplotlib之上的。
通常,对于非标准的调整,仍然有必要使用机器级的matplotlib代码。
Bokeh
一时间,我以为
Bokeh
会成为一个后援解决方案。
我在做地理空间可视化的时候发现了Bokeh。
然而,我很快就意识到,虽然Bokeh有所不同,但还是和matplotlib一样复杂。
Plotly
不久前我确实尝试过
plot.ly
(后面就直接用plotly来表示)同样用于地理空间可视化。
那个时候,plotly比前面提到的库还要麻烦。
它必须通过笔记本账户登录,然后plotly可以在线呈现,接着下载最终图表。
我很快就放弃了。
但是,我最近看到了一个关于plotlyexpress和plotly4.0的
Youtube视
频,重点是,他们把那些在线的废话都删掉了。
我尝试了一下,本篇文章就是尝试的成果。
我想,知道得晚总比不知道的好。
Kepler.gl (地理空间数据优秀奖)
Kepler.gl
不是一个Python库,而是一款强大的基于web的地理空间数据可视化工具。
只需要CSV文件,就可以使用Python轻松地创建文件。
试试吧!
当前工作流程
最后,我决定使用Pandas本地绘图进行快速检查,并使用Seaborn绘制要在报告和演示中使用的图表(视觉效果很重要)。
2. 分布的重要性
 图片来源:Jonny Caspari/Unsplash
我在圣地亚哥从事研究期间,负责教授统计学(Stats119)。
Stats119是统计学的入门课程,包括统计的基础知识,如数据聚合(可视化和定量)、概率的概念、回归、抽样、以及最重要的分布。
这一次,我对数量和现象的理解几乎完全转变为基于分布的理解(大多数时候是高斯分布)。
直到今天,我仍然惊讶于这两个量的作用,标准差能帮助人理解现象。
只要知道这两个量,就可以直接得出具体结果的概率,用户马上就知道大部分的结果的分布情况。
它提供了一个参考框架,无需进行过于复杂的计算,就可以快速找出有统计意义的事件。
一般来说,面对新数据时,我的第一步是尝试可视化其分布,以便更好地理解数据。
图片来源:Jonny Caspari/Unsplash
我在圣地亚哥从事研究期间,负责教授统计学(Stats119)。
Stats119是统计学的入门课程,包括统计的基础知识,如数据聚合(可视化和定量)、概率的概念、回归、抽样、以及最重要的分布。
这一次,我对数量和现象的理解几乎完全转变为基于分布的理解(大多数时候是高斯分布)。
直到今天,我仍然惊讶于这两个量的作用,标准差能帮助人理解现象。
只要知道这两个量,就可以直接得出具体结果的概率,用户马上就知道大部分的结果的分布情况。
它提供了一个参考框架,无需进行过于复杂的计算,就可以快速找出有统计意义的事件。
一般来说,面对新数据时,我的第一步是尝试可视化其分布,以便更好地理解数据。
3. 加载数据和包导入
 图片来源:Kelli Tungay/Unsplash
图片来源:Kelli Tungay/Unsplash
先加载本文使用的数据。 我已经对数据进行了预处理。 并对它的意义进行了探究和推断。
# Loadthe data
data = pd.read_csv('https://raw.githubusercontent.com/FBosler/AdvancedPlotting/master/combined_set.csv')#this assigns labels per year
data['Mean Log GDP per capita'] =data.groupby('Year')['Log GDP per capita'].transform(
pd.qcut,
q=5,
labels=(['Lowest','Low','Medium','High','Highest'])
)
import plotly
import pandas as pd
import numpy as np
import seaborn as sns
import plotly.express as pximport matplotlib%matplotlib inlineassertmatplotlib.__version__ == "3.1.0","""
Please install matplotlib version 3.1.0 by running:
1) !pip uninstall matplotlib
2) !pip install matplotlib==3.1.0
"""
4. 迅速:使用Pandas进行基本绘图
 图片来源:Marvin Meyer/Unsplash
Pandas有内置的绘图功能,可以在Series或DataFrame上调用。
之所以喜欢这些绘图函数,是因为它们简洁、使用合理的智能默认值、很快就能给出进展程度。
创建图表,在数据中调用.plot(kind=
图片来源:Marvin Meyer/Unsplash
Pandas有内置的绘图功能,可以在Series或DataFrame上调用。
之所以喜欢这些绘图函数,是因为它们简洁、使用合理的智能默认值、很快就能给出进展程度。
创建图表,在数据中调用.plot(kind=
np.exp(data[data['Year']==2018]['LogGDP per capita']).plot(
kind='hist'
)
 2018年:人均GDP直方图。大多数国家都很穷,这一点也不奇怪!
用Pandas绘图时,有五个主要参数:
· kind:
Pandas必须知道需要创建什么样的图,可选的有以下几种:
直方图(hist),条形图(bar),水平条图(barh),散点图(scatter),面积(area),核密度估计(kde),折线图(line),方框(box),六边形(hexbin),饼状图(pie)。
· figsize:
允许6英寸宽和4英寸高的默认输出尺寸。
需要一个元组(例如,我就经常使用figsize=(12,8))
· title:
为图表添加一个标题。
大多数情况下,可以用这个标题来标明图表中所显示的内容,这样回过头来看的时候,就能很快识别出表的内容。
title需要一个字符串。
· bins:直方图的bin宽度。
bin需要一个值的列表或类似列表序列(例如, bins=np.arange(2,8,0.25))
· xlim/ylim: 轴的最大和最小默认值。
xlim和ylim都最好有一个元组(例如, xlim=(0,5))
下面来快速浏览一下不同类型的图。
垂直条形图
2018年:人均GDP直方图。大多数国家都很穷,这一点也不奇怪!
用Pandas绘图时,有五个主要参数:
· kind:
Pandas必须知道需要创建什么样的图,可选的有以下几种:
直方图(hist),条形图(bar),水平条图(barh),散点图(scatter),面积(area),核密度估计(kde),折线图(line),方框(box),六边形(hexbin),饼状图(pie)。
· figsize:
允许6英寸宽和4英寸高的默认输出尺寸。
需要一个元组(例如,我就经常使用figsize=(12,8))
· title:
为图表添加一个标题。
大多数情况下,可以用这个标题来标明图表中所显示的内容,这样回过头来看的时候,就能很快识别出表的内容。
title需要一个字符串。
· bins:直方图的bin宽度。
bin需要一个值的列表或类似列表序列(例如, bins=np.arange(2,8,0.25))
· xlim/ylim: 轴的最大和最小默认值。
xlim和ylim都最好有一个元组(例如, xlim=(0,5))
下面来快速浏览一下不同类型的图。
垂直条形图
data[
data['Year'] == 2018
].set_index('Country name')['Life Ladder'].nlargest(15).plot(
kind='bar',
figsize=(12,8)
)
 2018年:芬兰位居15个最幸福国家之首
2018年:芬兰位居15个最幸福国家之首
水平条形图
np.exp(data[
data['Year'] == 2018
].groupby('Continent')['Log GDP per capita']\
.mean()).sort_values().plot(
kind='barh',
figsize=(12,8)
)
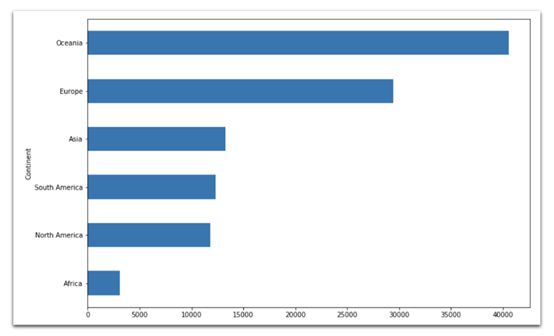 澳大利亚和新西兰2011年人均GDP(美元)明显领先
盒型图
澳大利亚和新西兰2011年人均GDP(美元)明显领先
盒型图
data['Life Ladder'].plot(
kind='box',
figsize=(12,8)
)
 人生阶梯分布的方框图显示平均值在5.5左右,范围为3~8。
散点图
人生阶梯分布的方框图显示平均值在5.5左右,范围为3~8。
散点图
data[['Healthy life expectancyat birth','Gapminder Life Expectancy']].plot(
kind='scatter',
x='Healthy life expectancy at birth',
y='Gapminder Life Expectancy',
figsize=(12,8)
)
 该散点图显示了《世界幸福报告》的预期寿命与Gapminder的预期寿命两者之间的高度相关性
该散点图显示了《世界幸福报告》的预期寿命与Gapminder的预期寿命两者之间的高度相关性
Hexbin图
data[data['Year'] == 2018].plot( kind='hexbin', x='Healthy life expectancy at birth', y='Generosity', C='Life Ladder', gridsize=20, figsize=(12,8), cmap="Blues", # defaults togreenish sharex=False # required to get rid ofa bug) 2018年:Hexbin图,表示人的平均寿命与慷慨程度之间的关系。格子的颜色表示每个格子的平均寿命。
饼状图
2018年:Hexbin图,表示人的平均寿命与慷慨程度之间的关系。格子的颜色表示每个格子的平均寿命。
饼状图
data[data['Year'] == 2018].groupby(
['Continent']
)['Gapminder Population'].sum().plot(
kind='pie',
figsize=(12,8),
cmap="Blues_r", # defaultsto orangish
)
 2018年:按大洲划分的总人口数饼状图
堆积面积图
2018年:按大洲划分的总人口数饼状图
堆积面积图
data.groupby(
['Year','Continent']
)['Gapminder Population'].sum().unstack().plot(
kind='area',
figsize=(12,8),
cmap="Blues", # defaults toorangish
)
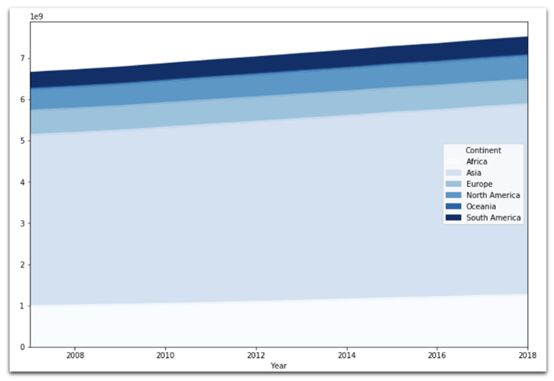 全球人口数量正在增长。
折线图
全球人口数量正在增长。
折线图
data[ data['Country name'] == 'Germany'].set_index('Year')['Life Ladder'].plot( kind='line', figsize=(12,8)) 表示德国幸福指数发展的折线图
关于Pandas绘图的总结
用pandas绘图很方便。
易于访问,速度也快。
只是图表外观相当丑,几乎不可能偏离默认值。
不过这没关系,因为有其他工具来制作更美观的图表。
表示德国幸福指数发展的折线图
关于Pandas绘图的总结
用pandas绘图很方便。
易于访问,速度也快。
只是图表外观相当丑,几乎不可能偏离默认值。
不过这没关系,因为有其他工具来制作更美观的图表。
5. 美观:使用Seaborn进行高级绘图
 图片来源:Pavel Nekoranec / Unsplash
Seaborn使用的是默认绘图。
要确保运行结果与本文一致,请运行以下命令。
图片来源:Pavel Nekoranec / Unsplash
Seaborn使用的是默认绘图。
要确保运行结果与本文一致,请运行以下命令。
sns.reset_defaults()
sns.set(
rc={'figure.figsize':(7,5)},
style="white" # nicerlayout
)
 左图:2018年亚洲国家人生阶梯直方图和核密度估算;右图:五组人均GDP人生阶梯的核心密度估算——体现了金钱与幸福指数的关系
绘制二元分布
每当我想要直观地探索两个或多个变量之间的关系,总是用到某种形式的散点图和分布评估。
在概念上相似的图表有三种变体。
在每个图中,中心图(散点图,二元KDE,hexbin)有助于理解两个变量之间的联合频率分布。
此外,在中心图的右边界和上边界,描述了各自变量的边际单变量分布(用KDE或直方图表示)。
左图:2018年亚洲国家人生阶梯直方图和核密度估算;右图:五组人均GDP人生阶梯的核心密度估算——体现了金钱与幸福指数的关系
绘制二元分布
每当我想要直观地探索两个或多个变量之间的关系,总是用到某种形式的散点图和分布评估。
在概念上相似的图表有三种变体。
在每个图中,中心图(散点图,二元KDE,hexbin)有助于理解两个变量之间的联合频率分布。
此外,在中心图的右边界和上边界,描述了各自变量的边际单变量分布(用KDE或直方图表示)。
sns.jointplot(
x='Log GDP per capita',
y='Life Ladder',
data=data,
kind='scatter' # or 'kde' or 'hex'
)
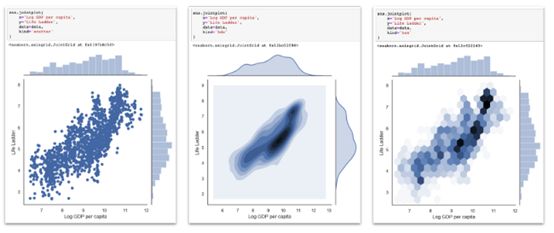 Seaborn双标图,散点图、二元KDE和Hexbin图都在中心图中,边缘分布在中心图的左侧和顶部。
散点图
散点图是一种可视化两个变量联合密度分布的方法。
可以通过添加色度来添加第三个变量,通过添加尺寸参数来添加第四个变量。
Seaborn双标图,散点图、二元KDE和Hexbin图都在中心图中,边缘分布在中心图的左侧和顶部。
散点图
散点图是一种可视化两个变量联合密度分布的方法。
可以通过添加色度来添加第三个变量,通过添加尺寸参数来添加第四个变量。
sns.scatterplot(
x='Log GDP per capita',
y='Life Ladder',
data=data[data['Year'] == 2018],
hue='Continent',
size='Gapminder Population'
)# both, hue and size are optional
sns.despine() # prettier layout
 人均GDP与生活阶梯的关系,不同颜色表示不同大洲和人口规模
小提琴图
小提琴图结合了盒状图和核密度估计值。
它的作用类似于盒状图,显示了定量数据在分类变量之间的分布,以便对这些分布进行比较。
人均GDP与生活阶梯的关系,不同颜色表示不同大洲和人口规模
小提琴图
小提琴图结合了盒状图和核密度估计值。
它的作用类似于盒状图,显示了定量数据在分类变量之间的分布,以便对这些分布进行比较。
sns.set( rc={'figure.figsize':(18,6)}, style="white")sns.violinplot( x='Continent', y='Life Ladder', hue='Mean Log GDP per capita', data=data)sns.despine()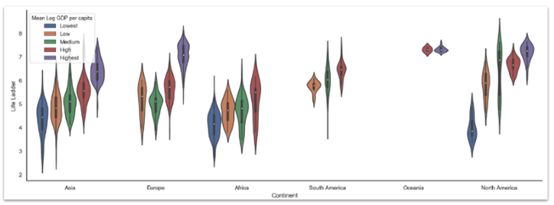 小提琴图在绘制大洲与生活阶梯的关系图时,用人均GDP的平均值对数据进行分组。人均GDP越高,幸福指数就越高
配对图
Seaborn配对图是在一个大网格中绘制双变量散点图的所有组合。
我通常觉得这有点信息过载,但它有助于发现规律。
小提琴图在绘制大洲与生活阶梯的关系图时,用人均GDP的平均值对数据进行分组。人均GDP越高,幸福指数就越高
配对图
Seaborn配对图是在一个大网格中绘制双变量散点图的所有组合。
我通常觉得这有点信息过载,但它有助于发现规律。
sns.set(
style="white",
palette="muted",
color_codes=True
)sns.pairplot(
data[data.Year == 2018][[
'Life Ladder','Log GDP percapita',
'Social support','Healthy lifeexpectancy at birth',
'Freedom to make lifechoices','Generosity',
'Perceptions of corruption','Positive affect',
'Negative affect','Confidence innational government',
'Mean Log GDP per capita'
]].dropna(),
hue='Mean Log GDP per capita'
)
 Seaborn散点图网格中,所有选定的变量都分散在网格的下半部分和上半部分,对角线包含Kde图。
FacetGrids
对我来说,Seaborn的FacetGrid是证明它好用最有说服力的证据之一,因为它能轻而易举地创建多图表。
通过配对图,我们已经看到了FacetGrid的一个示例。
它可以创建多个按变量分组的图表。
例如,行可以是一个变量(人均GDP的类别),列是另一个变量(大洲)。
它确实还需要适应客户需求(即使用matplotlib),但是它仍然是令人信服。
FacetGrid— 折线图
Seaborn散点图网格中,所有选定的变量都分散在网格的下半部分和上半部分,对角线包含Kde图。
FacetGrids
对我来说,Seaborn的FacetGrid是证明它好用最有说服力的证据之一,因为它能轻而易举地创建多图表。
通过配对图,我们已经看到了FacetGrid的一个示例。
它可以创建多个按变量分组的图表。
例如,行可以是一个变量(人均GDP的类别),列是另一个变量(大洲)。
它确实还需要适应客户需求(即使用matplotlib),但是它仍然是令人信服。
FacetGrid— 折线图
g = sns.FacetGrid(
data.groupby(['Mean Log GDP percapita','Year','Continent'])['Life Ladder'].mean().reset_index(),
row='Mean Log GDP per capita',
col='Continent',
margin_titles=True
)
g = (g.map(plt.plot, 'Year','Life Ladder'))
 y轴代表生活阶梯,x轴代表年份。网格的列代表大洲,网格的行代表不同水平的人均GDP。总体而言,北美人均GDP平均值较低的国家和欧洲人均GDP平均值中等或较高的国家,情况似乎有所好转
FacetGrid— 直方图
y轴代表生活阶梯,x轴代表年份。网格的列代表大洲,网格的行代表不同水平的人均GDP。总体而言,北美人均GDP平均值较低的国家和欧洲人均GDP平均值中等或较高的国家,情况似乎有所好转
FacetGrid— 直方图
g = sns.FacetGrid(data,col="Continent", col_wrap=3,height=4)
g = (g.map(plt.hist, "Life Ladder",bins=np.arange(2,9,0.5)))
 按大洲划分的生活阶梯直方图
FacetGrid— 带注释的KDE图
还可以向网格中的每个图表添加特定的注释。
以下示例将平均值和标准偏差以及在平均值处绘制的垂直线相加(代码如下)。
按大洲划分的生活阶梯直方图
FacetGrid— 带注释的KDE图
还可以向网格中的每个图表添加特定的注释。
以下示例将平均值和标准偏差以及在平均值处绘制的垂直线相加(代码如下)。
 基于大洲的生命阶梯核密度估计值,注释为均值和标准差
基于大洲的生命阶梯核密度估计值,注释为均值和标准差
defvertical_mean_line(x, **kwargs):
plt.axvline(x.mean(), linestyle="--",
color= kwargs.get("color", "r"))
txkw =dict(size=15, color= kwargs.get("color", "r"))
label_x_pos_adjustment =0.08# this needs customization based on your data
label_y_pos_adjustment =5# this needs customization based on your data
if x.mean() <6: # this needs customization based on your data
tx ="mean: {:.2f}\n(std: {:.2f})".format(x.mean(),x.std())
plt.text(x.mean() + label_x_pos_adjustment, label_y_pos_adjustment, tx, **txkw)
else:
tx ="mean: {:.2f}\n (std: {:.2f})".format(x.mean(),x.std())
plt.text(x.mean() -1.4, label_y_pos_adjustment, tx, **txkw)
_ = data.groupby(['Continent','Year'])['Life Ladder'].mean().reset_index()
g = sns.FacetGrid(_, col="Continent", height=4, aspect=0.9, col_wrap=3, margin_titles=True)
g.map(sns.kdeplot, "Life Ladder", shade=True, color='royalblue')
g.map(vertical_mean_line, "Life Ladder")
画一条垂直的平均值线并添加注释 FacetGrid— 热图 我最喜欢的一种绘图类型就是FacetGrid的热图,即每一个网格都有热图。 这种类型的绘图有助于在一个图中可视化四维和度量。 代码有点麻烦,但是可以根据使用者的需要快速调整。 需要注意的是,这种图表不能很好地处理缺失的值,所以需要大量的数据或适当的分段。
 Facet热图,外层的行显示在一年内,外层的列显示人均GDP,内层的行显示政治清廉,内层的列显示大洲。我们看到幸福指数朝着右上方向增加(即,高人均GDP和高政治清廉)。时间的影响还不确定,一些大洲(欧洲和北美)似乎比其他大洲(非洲)更幸福。
Facet热图,外层的行显示在一年内,外层的列显示人均GDP,内层的行显示政治清廉,内层的列显示大洲。我们看到幸福指数朝着右上方向增加(即,高人均GDP和高政治清廉)。时间的影响还不确定,一些大洲(欧洲和北美)似乎比其他大洲(非洲)更幸福。
heatmap_facetgrid.py
defdraw_heatmap(data,inner_row, inner_col, outer_row, outer_col, values, vmin,vmax):
sns.set(font_scale=1)
fg = sns.FacetGrid(
data,
row=outer_row,
col=outer_col,
margin_titles=True
)
position = left, bottom, width, height =1.4, .2, .1, .6
cbar_ax = fg.fig.add_axes(position)
fg.map_dataframe(
draw_heatmap_facet,
x_col=inner_col,
y_col=inner_row,
values=values,
cbar_ax=cbar_ax,
vmin=vmin,
vmax=vmax
)
fg.fig.subplots_adjust(right=1.3)
plt.show()
defdraw_heatmap_facet(*args, **kwargs):
data = kwargs.pop('data')
x_col = kwargs.pop('x_col')
y_col = kwargs.pop('y_col')
values = kwargs.pop('values')
d = data.pivot(index=y_col, columns=x_col, values=values)
annot =round(d,4).values
cmap = sns.color_palette("Blues",30) + sns.color_palette("Blues",30)[0::2]
#cmap = sns.color_palette("Blues",30)
sns.heatmap(
d,
**kwargs,
annot=annot,
center=0,
cmap=cmap,
linewidth=.5
)
# Data preparation
_ = data.copy()
_['Year'] = pd.cut(_['Year'],bins=[2006,2008,2012,2018])
_['GDP per Capita'] = _.groupby(['Continent','Year'])['Log GDP per capita'].transform(
pd.qcut,
q=3,
labels=(['Low','Medium','High'])
).fillna('Low')
_['Corruption'] = _.groupby(['Continent','GDP per Capita'])['Perceptions of corruption'].transform(
pd.qcut,
q=3,
labels=(['Low','Medium','High'])
)
_ = _[_['Continent'] !='Oceania'].groupby(['Year','Continent','GDP per Capita','Corruption'])['Life Ladder'].mean().reset_index()
_['Life Ladder'] = _['Life Ladder'].fillna(-10)
draw_heatmap(
data=_,
outer_row='Corruption',
outer_col='GDP per Capita',
inner_row='Year',
inner_col='Continent',
values='Life Ladder',
vmin=3,
vmax=8,
)
6. 精彩:用plotly创造精彩的互动情节
 图片来源:Chris Leipelt / Unsplash
最后, 无需使用matplotlib!
Plotly有三个重要特征:
· 悬停:
当鼠标悬停在图表上时,会弹出注释
· 交互性:
不需要任何额外设置,图表就可以进行交互(例如,一次穿越时间的旅程)
· 漂亮的地理空间图:
Plotly已经内置了一些基本的映射功能,另外,还可以使用mapbox集成来制作令人惊叹的图表。
散点图
通过下列代码来运行plotly图表:
图片来源:Chris Leipelt / Unsplash
最后, 无需使用matplotlib!
Plotly有三个重要特征:
· 悬停:
当鼠标悬停在图表上时,会弹出注释
· 交互性:
不需要任何额外设置,图表就可以进行交互(例如,一次穿越时间的旅程)
· 漂亮的地理空间图:
Plotly已经内置了一些基本的映射功能,另外,还可以使用mapbox集成来制作令人惊叹的图表。
散点图
通过下列代码来运行plotly图表:
fig = x.(PARAMS)然后是 fig.show() ,像这样:
fig = px.scatter(
data_frame=data[data['Year'] ==2018],
x="Log GDP per capita",
y="Life Ladder",
size="GapminderPopulation",
color="Continent",
hover_name="Country name",
size_max=60
)
fig.show()
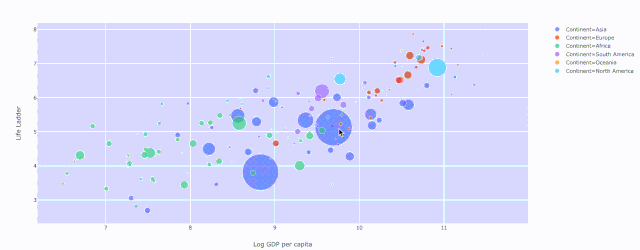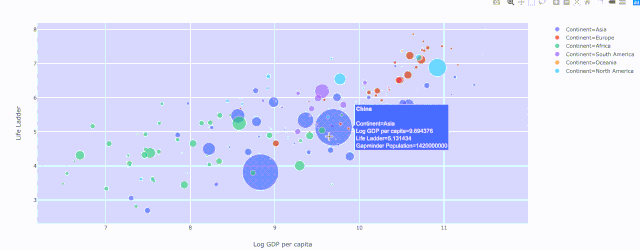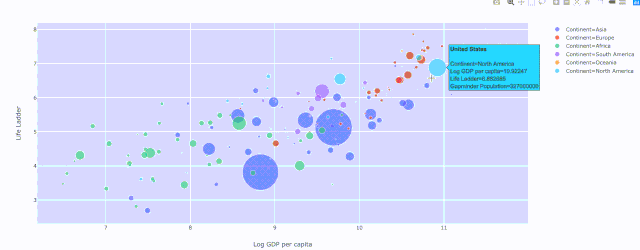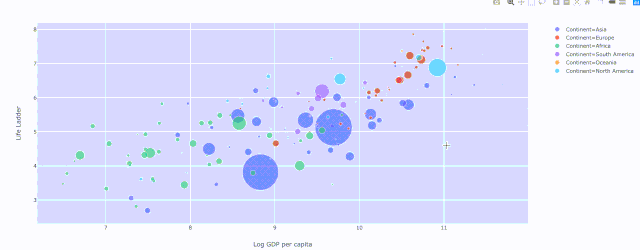 Plotly散点图,绘制人均 GDP与生活阶梯的关系,其中颜色表示大洲和人口的大小
Plotly散点图,绘制人均 GDP与生活阶梯的关系,其中颜色表示大洲和人口的大小散点图 — 穿越时间的漫步
fig = px.scatter(
data=data,
x="Log GDP per capita",
y="Life Ladder",
animation_frame="Year",
animation_group="Countryname",
size="GapminderPopulation",
color="Continent",
hover_name="Country name",
facet_col="Continent",
size_max=45,
category_orders={'Year':list(range(2007,2019))}
)fig.show()
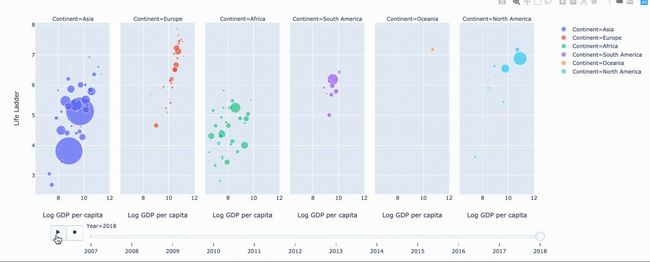 可视化数年来绘图数据的变化
可视化数年来绘图数据的变化
平行类别——一个能可视化类别的有趣方式
def q_bin_in_3(col):
return pd.qcut(
col,
q=3,
labels=['Low','Medium','High']
)_ = data.copy()
_['Social support'] = _.groupby('Year')['Socialsupport'].transform(q_bin_in_3)_['Life Expectancy'] =_.groupby('Year')['Healthy life expectancy atbirth'].transform(q_bin_in_3)_['Generosity'] =_.groupby('Year')['Generosity'].transform(q_bin_in_3)_['Perceptions ofcorruption'] = _.groupby('Year')['Perceptions ofcorruption'].transform(q_bin_in_3)_ = _.groupby(['Social support','LifeExpectancy','Generosity','Perceptions of corruption'])['LifeLadder'].mean().reset_index()fig = px.parallel_categories(_, color="LifeLadder", color_continuous_scale=px.colors.sequential.Inferno)
fig.show()
 并不是所有预期寿命高的国家的人民都很幸福!
并不是所有预期寿命高的国家的人民都很幸福!
条形图—一个交互式滤波器的示例
fig = px.bar(
data,
x="Continent",
y="Gapminder Population",
color="Mean Log GDP percapita",
barmode="stack",
facet_col="Year",
category_orders={"Year":range(2007,2019)},
hover_name='Country name',
hover_data=[
"Mean Log GDP percapita",
"Gapminder Population",
"Life Ladder"
]
)
fig.show()
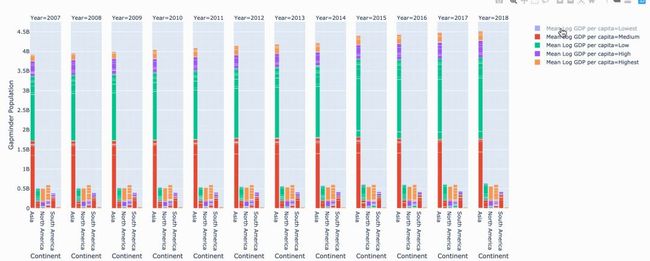 过滤条形图很容易。毫无疑问,韩国是亚洲富裕国家之一。
过滤条形图很容易。毫无疑问,韩国是亚洲富裕国家之一。等值线图— —幸福指数与时间的关系
fig = px.choropleth( data, locations="ISO3", color="Life Ladder", hover_name="Country name", animation_frame="Year")fig.show() 可视化不同地域的幸福指数是如何随时间变化的。叙利亚和阿富汗正处于人生阶梯的末端(这不足为奇)。
可视化不同地域的幸福指数是如何随时间变化的。叙利亚和阿富汗正处于人生阶梯的末端(这不足为奇)。
结束语
本文展示了如何成为一名真正的Python可视化专家、如何在快速探索时更有效率、以及如何在董事会会议前创建更漂亮的图表、还有如何创建交互式绘图图表,尤其是在绘制地理空间数据时,十分有用。
 推荐阅读专题
推荐阅读专题



 留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
编译组:
殷睿宣、杨月
相关链接:
https://towardsdatascience.com/plotting-with-python-c2561b8c0f1f
如转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你
留言点赞发个朋友圈
我们一起分享AI学习与发展的干货
编译组:
殷睿宣、杨月
相关链接:
https://towardsdatascience.com/plotting-with-python-c2561b8c0f1f
如转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你