python:爬取百度中国艺人公众人物人脸图像制作数据集
python:爬取百度中国艺人公众人物人脸图像制作数据集
分析
百度搜索中国艺人,打开检查页面找到api:发现图片和api的url

将url复制到postman分析

经过简单分析,发现GET请求分页的机制:rn指示一页的数量,pn指示起始标号。ps:经过简单测试,rn最大只能设置100。不过足够了。RESPONSE中人物名称是ename,图片地址是pic_4n_78
编程
废话不多说,直接代码
#!/usr/bin/env python
# coding=utf-8
import requests
import json
import os
Download_dir='chinese_celeb_imgs'
if os.path.exists(Download_dir)==False:
os.mkdir(Download_dir)
pn_i=0
while(True):
pn=str(pn_i)
pn_i+=100
url="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=500&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+pn+"&rn=100&_=1580457480665"
res = requests.get(url)
json_str=json.loads(res.text)
figs=json_str['data'][0]['result']
for i in figs:
name=i['ename']
img_url=i['pic_4n_78']
img_res=requests.get(img_url)
if img_res.status_code==200:
ext_str_splits=img_res.headers['Content-Type'].split('/')
ext=ext_str_splits[len(ext_str_splits)-1]
fname=name+"."+ext
open(os.path.join(Download_dir,fname), 'wb').write(img_res.content)
print(name,img_url,"saved")
简单粗暴,但是好用
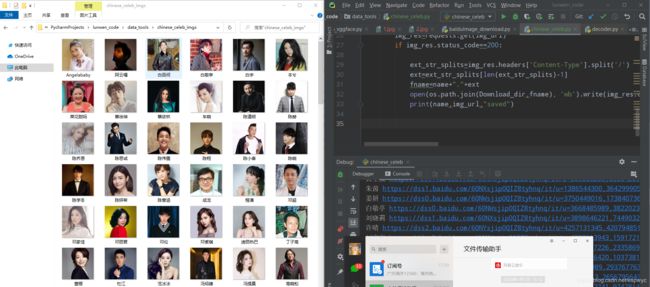
数据集制作
因为深度学习论文实验,打算制作3000个左右公众人物的人脸数据集,用上面的脚本下载了4000左右的原始图像,用dlib进行人脸对齐。
代码如下
import dlib
import cv2
import numpy as np
import time
import os
print("当前时间: ", time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())))
predictor_model = '../face_detect/dlib/landmark_detect/landmark/shape_predictor_68_face_landmarks.dat'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_model)
Source_dir="chinese_celeb_imgs_o"
Target_dir='aligned_faces'
def cut_faceimg(path='images/1.jpg',target_path=Target_dir):
# img = cv2.imread(path, cv2.IMREAD_COLOR)
try:
img = cv2.imdecode(np.fromfile(path,dtype=np.uint8),-1)
im_shape = img.shape
im_h = im_shape[0]
im_w = im_shape[1]
# 取灰度
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
except :
return
expand = 6
# cv2.imshow('img',img)
# cv2.waitKey()
# 人脸数rects
faces = detector(img_gray, 0)
for i in range(len(faces)):
sf = faces[i]
left = sf.left()
right = sf.right()
top = sf.top()
bottom = sf.bottom()
h = bottom - top
w = right - left
left = max(0, left - int(w / expand))
right = min(im_w, right + int(w / expand))
top = max(0, top - int(h / expand))
bottom = min(im_h, bottom + int(h / expand))
# print(left,right,top,bottom)
# cv2.rectangle(single_face, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 2)
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 1)
dst = img[top:bottom, left:right]
dst = cv2.resize(dst, (224, 224), interpolation=cv2.INTER_CUBIC)
# cv2.imshow('dst',dst)
# cv2.waitKey()
ct = time.time()
local_time = time.localtime(ct)
data_head = time.strftime("%Y-%m-%d %H:%M:%S", local_time)
data_secs = (ct - int(ct)) * 1000
time_stamp = "%s.%03d" % (data_head, data_secs)
stamp = ("".join(time_stamp.split()[0].split("-")) + "".join(time_stamp.split()[1].split(":"))).replace('.', '')
name = stamp + ".jpg"
cv2.imwrite(os.path.join(target_path,name), dst)
def main():
if os.path.exists(Source_dir) == False:
return
if os.path.exists(Target_dir) == False:
os.mkdir(Target_dir)
for name in os.listdir(Source_dir):
path = os.path.join(Source_dir, name)
if os.path.isfile(path):
cut_faceimg(path,Target_dir)
if __name__=='__main__':
main()
部分对其人脸如下



附录
对齐人脸https://download.csdn.net/download/espwyc/12127496
原始数据https://download.csdn.net/download/espwyc/12127497