OpenAI Gym构建自定义强化学习环境
OpenAI Gym是开发和比较强化学习算法的工具包。
OpenAI Gym由两部分组成:
- gym开源库:测试问题的集合。当你测试强化学习的时候,测试问题就是环境,比如机器人玩游戏,环境的集合就是游戏的画面。这些环境有一个公共的接口,允许用户设计通用的算法。
- OpenAI Gym服务。提供一个站点(比如对于游戏cartpole-v0:https://gym.openai.com/envs/CartPole-v0)和api,允许用户对他们的测试结果进行比较。
gym的核心接口是Env,作为统一的环境接口。Env包含下面几个核心方法:
- reset(self):重置环境的状态,返回观察。
- step(self, action):推进一个时间步长,返回observation,reward,done,info
- render(self, mode=’human’, close=False):重绘环境的一帧。默认模式一般比较友好,如弹出一个窗口。
自定义环境
背景

机器人在一个二维迷宫中走动,迷宫中有火坑、石柱、钻石。如果机器人掉到火坑中,游戏结束,如果找到钻石,可以得到奖励,游戏也结束!设计最佳的策略,让机器人尽快地找到钻石,获得奖励。
操作环境
Python环境:anaconda5.2
pip安装gym
步骤
在 anaconda3/lib/python3.6/site-packages/gym/envs 下新建目录 user ,用于存放自定义的强化学习环境。
在 user 目录下新建环境 grid_mdp_v1.py
import logging
import random
import gym
logger = logging.getLogger(__name__)
class GridEnv1(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 2
}
def __init__(self):
self.states = range(1,17) #状态空间
self.x=[150,250,350,450] * 4
self.y=[450] * 4 + [350] * 4 + [250] * 40 + [150] * 4
self.terminate_states = dict() #终止状态为字典格式
self.terminate_states[11] = 1
self.terminate_states[12] = 1
self.terminate_states[15] = 1
self.actions = ['n','e','s','w']
self.rewards = dict(); #回报的数据结构为字典
self.rewards['8_s'] = -1.0
self.rewards['13_w'] = -1.0
self.rewards['7_s'] = -1.0
self.rewards['10_e'] = -1.0
self.rewards['14_4'] = 1.0
self.t = dict(); #状态转移的数据格式为字典
self.t['1_s'] = 5
self.t['1_e'] = 2
self.t['2_w'] = 1
self.t['2_e'] = 3
self.t['3_s'] = 6
self.t['3_w'] = 2
self.t['3_e'] = 4
self.t['4_w'] = 3
self.t['4_s'] = 7
self.t['5_s'] = 8
self.t['6_n'] = 3
self.t['6_s'] = 10
self.t['6_e'] = 7
self.t['7_w'] = 6
self.t['7_n'] = 4
self.t['7_s'] = 11
self.t['8_n'] = 5
self.t['8_e'] = 9
self.t['8_s'] = 12
self.t['9_w'] = 8
self.t['9_e'] = 10
self.t['9_s'] = 13
self.t['10_w'] = 9
self.t['10_n'] = 6
self.t['10_e'] = 11
self.t['10_s'] = 14
self.t['10_w'] = 9
self.t['13_n'] = 9
self.t['13_e'] = 14
self.t['13_w'] = 12
self.t['14_n'] = 10
self.t['14_e'] = 15
self.t['14_w'] = 13
self.gamma = 0.8 #折扣因子
self.viewer = None
self.state = None
def _seed(self, seed=None):
self.np_random, seed = random.seeding.np_random(seed)
return [seed]
def getTerminal(self):
return self.terminate_states
def getGamma(self):
return self.gamma
def getStates(self):
return self.states
def getAction(self):
return self.actions
def getTerminate_states(self):
return self.terminate_states
def setAction(self,s):
self.state=s
def step(self, action):
#系统当前状态
state = self.state
if state in self.terminate_states:
return state, 0, True, {}
key = "%d_%s"%(state, action) #将状态和动作组成字典的键值
#状态转移
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if next_state in self.terminate_states:
is_terminal = True
if key not in self.rewards:
r = 0.0
else:
r = self.rewards[key]
return next_state, r, is_terminal,{}
def reset(self):
self.state = self.states[int(random.random() * len(self.states))]
return self.state
def render(self, mode='human'):
from gym.envs.classic_control import rendering
screen_width = 600
screen_height = 600
if self.viewer is None:
self.viewer = rendering.Viewer(screen_width, screen_height)
#创建网格世界
self.line1 = rendering.Line((100,100),(500,100))
self.line2 = rendering.Line((100, 200), (500, 200))
self.line3 = rendering.Line((100, 300), (500, 300))
self.line4 = rendering.Line((100, 400), (500, 400))
self.line5 = rendering.Line((100, 500), (500, 500))
self.line6 = rendering.Line((100, 100), (100, 500))
self.line7 = rendering.Line((200, 100), (200, 500))
self.line8 = rendering.Line((300, 100), (300, 500))
self.line9 = rendering.Line((400, 100), (400, 500))
self.line10 = rendering.Line((500, 100), (500, 500))
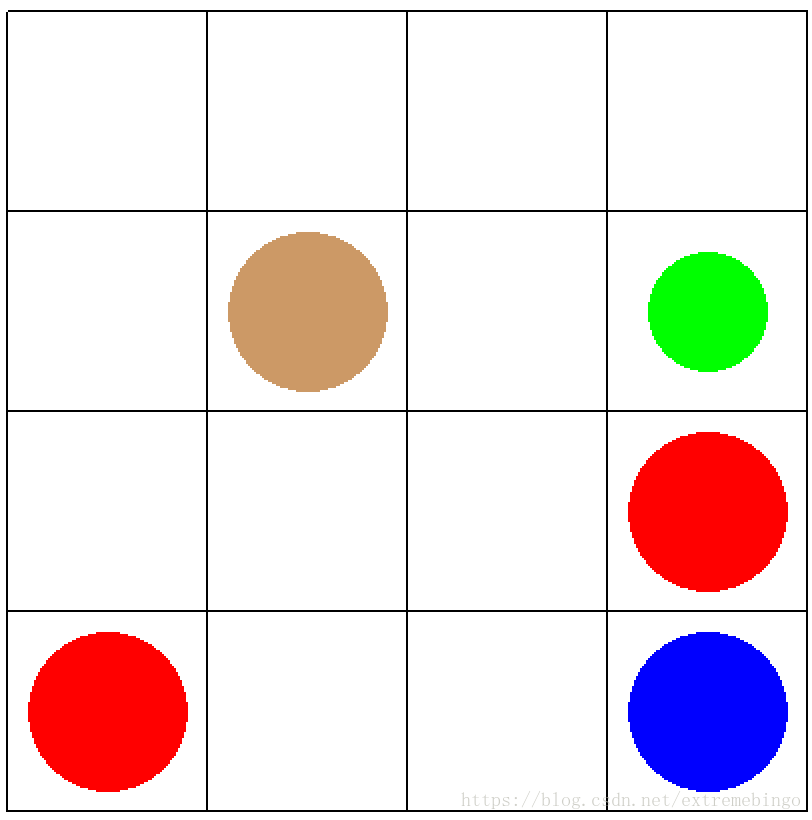
#创建石柱
self.shizhu = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(250,350))
self.shizhu.add_attr(self.circletrans)
self.shizhu.set_color(0.8,0.6,0.4)
#创建第一个火坑
self.fire1 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(450, 250))
self.fire1.add_attr(self.circletrans)
self.fire1.set_color(1, 0, 0)
#创建第二个火坑
self.fire2 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(150, 150))
self.fire2.add_attr(self.circletrans)
self.fire2.set_color(1, 0, 0)
#创建宝石
self.diamond = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(450, 150))
self.diamond.add_attr(self.circletrans)
self.diamond.set_color(0, 0, 1)
#创建机器人
self.robot= rendering.make_circle(30)
self.robotrans = rendering.Transform()
self.robot.add_attr(self.robotrans)
self.robot.set_color(0, 1, 0)
self.line1.set_color(0, 0, 0)
self.line2.set_color(0, 0, 0)
self.line3.set_color(0, 0, 0)
self.line4.set_color(0, 0, 0)
self.line5.set_color(0, 0, 0)
self.line6.set_color(0, 0, 0)
self.line7.set_color(0, 0, 0)
self.line8.set_color(0, 0, 0)
self.line9.set_color(0, 0, 0)
self.line10.set_color(0, 0, 0)
self.viewer.add_geom(self.line1)
self.viewer.add_geom(self.line2)
self.viewer.add_geom(self.line3)
self.viewer.add_geom(self.line4)
self.viewer.add_geom(self.line5)
self.viewer.add_geom(self.line6)
self.viewer.add_geom(self.line7)
self.viewer.add_geom(self.line8)
self.viewer.add_geom(self.line9)
self.viewer.add_geom(self.line10)
self.viewer.add_geom(self.shizhu)
self.viewer.add_geom(self.fire1)
self.viewer.add_geom(self.fire2)
self.viewer.add_geom(self.diamond)
self.viewer.add_geom(self.robot)
if self.state is None:
return None
self.robotrans.set_translation(self.x[self.state-1], self.y[self.state- 1])
return self.viewer.render(return_rgb_array=mode == 'rgb_array')
def close(self):
if self.viewer:
self.viewer.close()在 user 目录下新建 __init__.py
from gym.envs.user.grid_mdp_v1 import GridEnv1在 anaconda3/lib/python3.6/site-packages/gym/envs/__init__.py 中进行注册,在最后加入
register(
id='GridWorld-v1',
entry_point='gym.envs.user:GridEnv1',
max_episode_steps=200,
reward_threshold=100.0,
)测试
import gym
env = gym.make('GridWorld-v1')
env.reset()
env.render()
env.close()