Kerberos环境下的hadoop fs 代码走读
1. 前言
比较Kerberos与非Kerberos的hadoop环境配置,在配置文件上面来说,它们差别不是太大,主要是在core-site.xml中,但是hadoop到底是如何读取这些配置文件以及如何进行kerberos校验,这一块比较模糊,这两天仔细将这一块代码走读一遍,记录下来。
2. 代码分析
对于kerberos代码的分析,主要是客户端,查看一下它的执行堆栈信息(不执行kinit的情况下,执行 hadoop fs -ls / 后的异常信息), 其调用栈如下,我只列出其中比较关键的调用栈:
[root@ysbdh04 conf]# hadoop fs -ls /
17/12/29 11:22:43 WARN ipc.Client: Exception encountered while connecting to the server :
javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211)
at org.apache.hadoop.security.SaslRpcClient.saslConnect(SaslRpcClient.java:413)
at org.apache.hadoop.ipc.Client$Connection.setupSaslConnection(Client.java:595) <-- Client代码
... ....
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2158) <---- DFSClient的代
... 41 more
[root@ysbdh04 conf]# 其中DFSClient.java与Client.java的代码涉及到Kerberos与SIMPLE
2.1 客户端代码
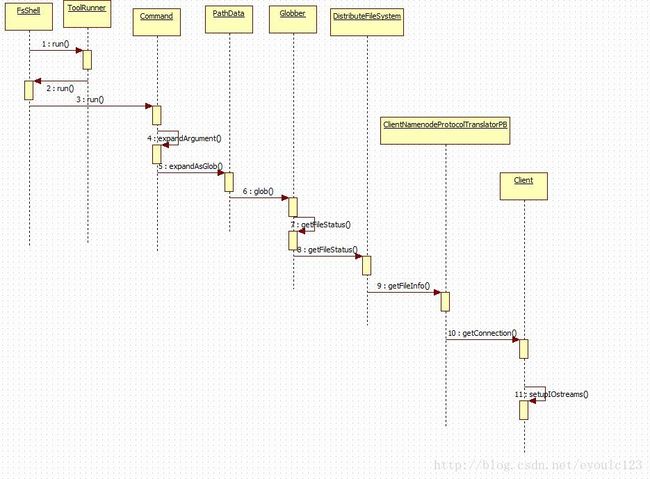
1.所有命令的入口函数都是FsShell::main(),通过它调用FsShell::run()函数,最终会回调用ToolRunner::run()
2.在ToolRunner::run()函数中, 其代码如下:
public static int run(Configuration conf, Tool tool, String[] args)
throws Exception{
... ...
return tool.run(toolArgs); <-----最终调用到实际的run()
}
3.再次回调用FsShell的run()函数,此时通过获取实际的命令参数,再次调用Command::run()函数
下面Command::run()函数的两个主要函数,分为是:
processOptions()与 processRawArguments()
其中processOptions()处于处理参数信息
protected void processRawArguments(LinkedList args)
throws IOException {
processArguments(expandArguments(args));
} 其中expandArguments()处理着之后的连接的创建。
4.Command::expandArguments()函数就开始处理各个参数,也就开始处理路径信息
protected List expandArgument(String arg) throws IOException {
PathData[] items = PathData.expandAsGlob(arg, getConf());
if (items.length == 0) {
// it's a glob that failed to match
throw new PathNotFoundException(arg);
}
return Arrays.asList(items);
} 此时经过前面的解析之后,此时传入的arg已经是路径了
5 之后开始调用PathData::expandAsGlob()函数,在这个函数中
public static PathData[] expandAsGlob(String pattern, Configuration conf)
throws IOException {
Path globPath = new Path(pattern);
FileSystem fs = globPath.getFileSystem(conf);
FileStatus[] stats = fs.globStatus(globPath);
PathData[] items = null;
... ...
}此时传入的pattern已经是纯粹的path路径
6~8 这几步纯粹的就是一个调用关系
9.开始调用ClientNamenodeProtocolTranslatorPB的函数,也是开始调用proto生成的代码,即远程调用
10.调用Client::getConnection(),这一步开始创建连接。注意SASL、GSSAPI都可以看成是基于TCP/IP的协议,且在它之上,因此它也是在创建连接之后,再决定是SASL还是普通的TCP连接。
private Connection getConnection(ConnectionId remoteId,
Call call, int serviceClass, AtomicBoolean fallbackToSimpleAuth)
throws IOException {
... ...
do {
synchronized (connections) {
connection = connections.get(remoteId);
if (connection == null) {
//如果在connections的连接池中没有,就会在这里创建一个
connection = new Connection(remoteId, serviceClass);
connections.put(remoteId, connection);
}
}
} while (!connection.addCall(call));
... ...
//再设置是不是kerberos连接的
connection.setupIOstreams(fallbackToSimpleAuth);
return connection;
}
11.回调Client::setupIOstreams(),这个函数会设定当前连接sasl还是simple,其代码如下:
private synchronized void setupIOstreams(AtomicBoolean fallbackToSimpleAuth) {
... ...
while (true) {
... ...
// 判断一下此时是不是SASL, 而authProtocol的值是通过SecurityUtil::getAuthenticationMethod()
//这个函数会读取core_site.xml中的配置,默认为SIMPLE
if (authProtocol == AuthProtocol.SASL) {
final InputStream in2 = inStream;
final OutputStream out2 = outStream;
//当系统为Kerberos环境的时候,就获取ticket
UserGroupInformation ticket = remoteId.getTicket();
if (ticket.getRealUser() != null) {
ticket = ticket.getRealUser();
}
try {
authMethod = ticket
.doAs(new PrivilegedExceptionAction() {
@Override
public AuthMethod run()
throws IOException, InterruptedException {
return setupSaslConnection(in2, out2);
}
});
} catch (Exception ex) {
... ...
}
//此处开始设置是SIMPLE还是非SIMPLE,从这里可以看到HADOOP只支持SASL这一种情况
if (authMethod != AuthMethod.SIMPLE) {
// Sasl connect is successful. Let's set up Sasl i/o streams.
... ...
}
}
... ...
}
从上面的代码中,我们就可以看到,系统根据core-site.xml中的配置信息,来判断是否为Kerberos环境,如果是kerberos环境,则执行SASL相应的代码,而不为Kerberos环境,则执行对应的代码。在这其中有两个地方,可能需要注意:authProtocol与ticket的值 。
其中authProtocol是通过静态函数SecurityUtil::getAuthenticationMethod()获取出来,读取core_site.xml中的配置信息。 而ticket的值,则是通过DFClient这个函数在初始化的时候,传入的。 查看一下DFSClient的构造函数
public DFSClient(URI nameNodeUri, ClientProtocol rpcNamenode,
Configuration conf, FileSystem.Statistics stats)
throws IOException {
... ...
//此处就开始获取ugi的值,
this.ugi = UserGroupInformation.getCurrentUser();
... ....
//在createProxy()实现中也会调用 UserGroupInformation.getCurrentUser();
proxyInfo = NameNodeProxies.createProxy(conf, nameNodeUri,
ClientProtocol.class, nnFallbackToSimpleAuth);
this.dtService = proxyInfo.getDelegationTokenService();
this.namenode = proxyInfo.getProxy();
}
... ...
}因此很清楚了,ticket信息都是通过 UserGroupInformation.getCurrentUser();这个函数来获取。对此,可以使用一个简单的测试程序在不同的环境下面打印UserGroupInformation.getCurrentUser().toString()的值。
在非Kerberos环境下面,其值为 : root (auth:SIMPLE)
在Kerberos环境下面,但是没有执行Kinit的环境下面,其值为:root (auth:KERBEROS)
在执行完kinit的kerberos环境下面, 其值为: [email protected] (auth:KERBEROS)
3 . 总结
当hadoop 的客户端进程启动后,会读取core-site.xml文件, 并初始化DFSClient这个类。 在初始化DFSClient类的时候,会创建相应namenode 的proxy,在这个proxy中保存着通过调用UserGroupInformation.getCurrentUser() 得到的UserGroupInformation信息,这个信息比较重要。 它会根据不同的情况来获取到不同的信息,这个信息就对应了我们所需的用户、票据等信息。