android学习之路(二)----java8
Java8新特性
一、lambda语法
1.概述
lambda(闭包)以及虚拟扩展方法(default method)
2.函数式接口
函数式接口(functional interface 也叫功能性接口,其实是同一个东西)。简单来说,函数式接口是只包含一个方法的接口。比如Java标准库中的java.lang.Runnable和java.util.Comparator都是典型的函数式接口。
java 8提供 @FunctionalInterface作为注解,这个注解是非必须的,只要接口符合函数式接口的标准(即只包含一个方法的接口),虚拟机会自动判断,但最好在接口上使用注解@FunctionalInterface进行声明,以免团队的其他人员错误地往接口中添加新的方法。
Java中的lambda无法单独出现,它需要一个函数式接口来盛放,lambda表达式方法体其实就是函数接口的实现,下面讲到语法会讲到
3.Lambda语法
包含三个部分
3.1 一个括号内用逗号分隔的形式参数,参数是函数式接口里面方法的参数
3.2 一个箭头符号:->
3.3 方法体,可以是表达式和代码块,方法体函数式接口里面方法的实现,如果是代码块,则必须用{}来包裹起来,且需要一个return 返回值,但有个例外,若函数式接口里面方法返回值是void,则无需{}
总体看起来像这样
(parameters) -> expression 或者 (parameters) -> { statements; }
public class TestLambda {
public static void runThreadUseLambda() {
//Runnable是一个函数接口,只包含了有个无参数的,返回void的run方法;
//所以lambda表达式左边没有参数,右边也没有return,只是单纯的打印一句话
new Thread(() ->System.out.println("lambda实现的线程")).start();
}
public static void runThreadUseInnerClass() {
//这种方式就不多讲了,以前旧版本比较常见的做法
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("内部类实现的线程");
}
}).start();
}
public static void main(String[] args) {
TestLambda.runThreadUseLambda();
TestLambda.runThreadUseInnerClass();
}
}3.4 方法引用
其实是lambda表达式的一个简化写法,所引用的方法其实是lambda表达式的方法体实现,语法也很简单,左边是容器(可以是类名,实例名),中间是”::”,右边是相应的方法名。如下所示:
ObjectReference::methodName一般方法的引用格式是
1. 如果是静态方法,则是ClassName::methodName。如 Object ::equals
2. 如果是实例方法,则是Instance::methodName。
如Object obj=new Object();obj::equals;
3. 构造函数.则是ClassName::new
再来看一个完整的例子,方便理解
public class TestMethodReference {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setLayout(new FlowLayout());
frame.setVisible(true);
JButton button1 = new JButton("点我!");
JButton button2 = new JButton("也点我!");
frame.getContentPane().add(button1);
frame.getContentPane().add(button2);
// 这里addActionListener方法的参数是ActionListener,是一个函数式接口
// 使用lambda表达式方式
button1.addActionListener(e -> {
System.out.println("这里是Lambda实现方式");
});
// 使用方法引用方式
button2.addActionListener(Test::doSomething);
frame.show();
}
/**
* 这里是函数式接口ActionListener的实现方法
* @param e
*/
public static void doSomething(ActionEvent e) {
System.out.println("这里是方法引用实现方式");
}
} 可以看出,doSomething方法就是lambda表达式的实现,这样的好处就是,如果你觉得lambda的方法体会很长,影响代码可读性,方法引用就是个解决办法
4.总结
以上就是lambda表达式语法的全部内容了,相信大家对lambda表达式都有一定的理解了,但只是代码简洁了这个好处的话,并不能打动很多观众,java 8也不会这么令人期待,其实java 8引入lambda迫切需求是因为lambda 表达式能简化集合上数据的多线程或者多核的处理,提供更快的集合处理速度 ,这个后续会讲到,关于JEP126的这一特性,将分3部分,之所以分开,是因为这一特性可写的东西太多了,这部分让读者熟悉lambda表达式以及方法引用的语法和概念,第二部分则是虚拟扩展方法(default method)的内容,最后一部分则是大数据集合的处理,解开lambda表达式的最强作用的神秘面纱。敬请期待。。。。
二、深入解析默认方法(也称为虚拟扩展方法或防护方法)
1. 什么是默认方法,为什么要有默认方法
简单说,就是接口可以有实现方法,而且不需要实现类去实现其方法。只需在方法名前面加个default关键字即可。
为什么要有这个特性?首先,之前的接口是个双刃剑,好处是面向抽象而不是面向具体编程,缺陷是,当需要修改接口时候,需要修改全部实现该接口的类,目前的java 8之前的集合框架没有foreach方法,通常能想到的解决办法是在JDK里给相关的接口添加新的方法及实现。然而,对于已经发布的版本,是没法在给接口添加新方法的同时不影响已有的实现。所以引进的默认方法。他们的目的是为了解决接口的修改与现有的实现不兼容的问题。
简单的例子
一个接口A,Clazz类实现了接口A。
public interface A {
default void foo(){
System.out.println("Calling A.foo()");
}
}
public class Clazz implements A {
public static void main(String[] args){
Clazz clazz = new Clazz();
clazz.foo();//调用A.foo()
}
} 代码是可以编译的,即使Clazz类并没有实现foo()方法。在接口A中提供了foo()方法的默认实现。
2.java 8抽象类与接口对比
这一个功能特性出来后,很多同学都反应了,java 8的接口都有实现方法了,跟抽象类还有什么区别?其实还是有的,请看下表对比。。

3.多重继承的冲突说明
由于同一个方法可以从不同接口引入,自然而然的会有冲突的现象,默认方法判断冲突的规则如下:
3.1.一个声明在类里面的方法优先于任何默认方法(classes always win)
3.2.否则,则会优先选取最具体的实现,比如下面的例子 B重写了A的hello方法。
输出结果是:Hello World from B
如果想调用A的默认函数,则用到新语法X.super.m(…),下面修改C类,实现A接口,重写一个hello方法,如下所示:
public class C implements A{
@Override
public void hello(){
A.super.hello();
}
public static void main(String[] args){
new C().hello();
}
}输出结果是:Hello World from A
4. 总结
默认方法给予我们修改接口而不破坏原来的实现类的结构提供了便利,目前java 8的集合框架已经大量使用了默认方法来改进了,当我们最终开始使用Java 8的lambdas表达式时,提供给我们一个平滑的过渡体验。也许将来我们会在API设计中看到更多的默认方法的应用。
三、lambda进阶
1.概述
lambda为java带来闭包的概念,但是如果我们不在集合中使用它的话,就损失了很大价值。现有接口迁移成为lambda风格的问题已经通过default methods解决了,在这篇文章将深入解析Java集合里面的批量数据操作(bulk operation),解开lambda最强作用的神秘面纱。
2.关于JSR335
JSR是Java Specification Requests的缩写,意思是Java 规范请求,Java 8 版本的主要改进是 Lambda 项目(JSR 335),其目的是使 Java 更易于为多核处理器编写代码。JSR 335=lambda表达式+接口改进(默认方法)+批量数据操作。加上前面两篇,我们已是完整的学习了JSR335的相关内容了。
3.外部VS内部迭代
以前Java集合是不能够表达内部迭代的,而只提供了一种外部迭代的方式,也就是for或者while循环。
List persons = asList(new Person("Joe"), new Person("Jim"), new Person("John"));
for (Person p : persons) {
p.setLastName("Doe");
} 上面的例子是我们以前的做法,也就是所谓的外部迭代,循环是固定的顺序循环。在现在多核的时代,如果我们想并行循环,不得不修改以上代码。效率能有多大提升还说定,且会带来一定的风险(线程安全问题等等)。
要描述内部迭代,我们需要用到Lambda这样的类库,下面利用lambda和Collection.forEach重写上面的循环
persons.forEach(p->p.setLastName("Doe")); 现在是由jdk 库来控制循环了,我们不需要关心last name是怎么被设置到每一个person对象里面去的,库可以根据运行环境来决定怎么做,并行,乱序或者懒加载方式。这就是内部迭代,客户端将行为p.setLastName当做数据传入api里面。
内部迭代其实和集合的批量操作并没有密切的联系,借助它我们感受到语法表达上的变化。真正有意思的和批量操作相关的是新的流(stream)API。新的java.util.stream包已经添加进JDK 8了。
4.Stream API
流(Stream)仅仅代表着数据流,并没有数据结构,所以他遍历完一次之后便再也无法遍历(这点在编程时候需要注意,不像Collection,遍历多少次里面都还有数据),它的来源可以是Collection、array、io等等。
4.1中间与终点方法
流作用是提供了一种操作大数据接口,让数据操作更容易和更快。它具有过滤、映射以及减少遍历数等方法,这些方法分两种:中间方法和终端方法,“流”抽象天生就该是持续的,中间方法永远返回的是Stream,因此如果我们要获取最终结果的话,必须使用终点操作才能收集流产生的最终结果。区分这两个方法是看他的返回值,如果是Stream则是中间方法,否则是终点方法。具体请参照Stream的api。
简单介绍下几个中间方法(filter、map)以及终点方法(collect、sum)
4.1.1 Filter
在数据流中实现过滤功能是首先我们可以想到的最自然的操作了。Stream接口暴露了一个filter方法,它可以接受表示操作的Predicate实现来使用定义了过滤条件的lambda表达式。
List persons = …
Stream personsOver18 = persons.stream().filter(p -> p.getAge() > 18);//过滤18岁以上的人4.1.2 Map
假使我们现在过滤了一些数据,比如转换对象的时候。Map操作允许我们执行一个Function的实现(Function的泛型T,R分别表示执行输入和执行结果),它接受入参并返回。首先,让我们来看看怎样以匿名内部类的方式来描述它:
Stream adult= persons
.stream()
.filter(p -> p.getAge() > 18)
.map(new Function() {
@Override
public Adult apply(Person person) {
return new Adult(person);//将大于18岁的人转为成年人
}
});现在,把上述例子转换成使用lambda表达式的写法:
Stream map = persons.stream()
.filter(p -> p.getAge() > 18)
.map(person -> new Adult(person));4.1.3Count
count方法是一个流的终点方法,可使流的结果最终统计,返回int,比如我们计算一下满足18岁的总人数
int countOfAdult=persons.stream()
.filter(p -> p.getAge() > 18)
.map(person -> new Adult(person))
.count();4.1.4Collect
collect方法也是一个流的终点方法,可收集最终的结果
List adultList= persons.stream()
.filter(p -> p.getAge() > 18)
.map(person -> new Adult(person))
.collect(Collectors.toList());或者,如果我们想使用特定的实现类来收集结果:
List adultList = persons
.stream()
.filter(p -> p.getAge() > 18)
.map(person -> new Adult(person))
.collect(Collectors.toCollection(ArrayList::new));4.2顺序流与并行流
每个Stream都有两种模式:顺序执行和并行执行。
顺序流:
List people = list.getStream.collect(Collectors.toList()); 并行流:
List people = list.getStream.parallel().collect(Collectors.toList()); 顾名思义,当使用顺序方式去遍历时,每个item读完后再读下一个item。而使用并行去遍历时,数组会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。
4.2.1并行流原理:
List originalList = someData;
split1 = originalList(0, mid);//将数据分小部分
split2 = originalList(mid,end);
new Runnable(split1.process());//小部分执行操作
new Runnable(split2.process());
List revisedList = split1 + split2;//将结果合并 大家对hadoop有稍微了解就知道,里面的 MapReduce 本身就是用于并行处理大数据集的软件框架,其处理大数据的核心思想就是大而化小,分配到不同机器去运行map,最终通过reduce将所有机器的结果结合起来得到一个最终结果,与MapReduce不同,Stream则是利用多核技术可将大数据通过多核并行处理,而MapReduce则可以分布式的。
4.2.2顺序与并行性能测试对比
如果是多核机器,理论上并行流则会比顺序流快上一倍,下面是测试代码
public static void main(String[] args) {
long startTime = System.nanoTime();
int[] array = IntStream.range(0, 1_000_000).filter(p -> p % 2 == 0)
.toArray();
System.out.println("串行时间是:" + (System.nanoTime() - startTime));
startTime = System.nanoTime();
array = IntStream.range(0, 1_000_000).parallel()
.filter(p -> p % 2 == 0).toArray();
System.out.println("并行时间是:" + (System.nanoTime() - startTime));
}打印结果:
串行时间是:60908736
并行时间是:184404994.3关于Folk/Join框架
应用硬件的并行性在java 7就有了,那就是 java.util.concurrent 包的新增功能之一是一个 fork-join 风格的并行分解框架,同样也很强大高效,有兴趣的同学去研究,这里不详谈了,相比Stream.parallel()这种方式,我更倾向于后者。
5.总结
如果没有lambda,Stream用起来相当别扭,他会产生大量的匿名内部类,比如上面的4.1.2map例子,如果没有default method,集合框架更改势必会引起大量的改动,所以lambda+default method使得jdk库更加强大,以及灵活,Stream以及集合框架的改进便是最好的证明。
四、类型注解
1.概述
本文将介绍java 8的第二个特性:类型注解。
注解大家都知道,从java5开始加入这一特性,发展到现在已然是遍地开花,在很多框架中得到了广泛的使用,用来简化程序中的配置。那充满争议的类型注解究竟是什么?复杂还是便捷?
2. 什么是类型注解
在java 8之前,注解只能是在声明的地方所使用,比如类,方法,属性;java 8里面,注解可以应用在任何地方,比如:
• 创建类实例
new @Interned MyObject();
• 类型映射
myString = (@NonNull String) str;
• implements 语句中
class UnmodifiableList<T> implements @Readonly List<@Readonly T> { ... }
• throw exception声明
void monitorTemperature() throws @Critical TemperatureException { ... } 需要注意的是,类型注解只是语法而不是语义,并不会影响java的编译时间,加载时间,以及运行时间,也就是说,编译成class文件的时候并不包含类型注解。
3. 类型注解的作用
Collections.emptyList().add("One");
int i=Integer.parseInt("hello");
System.console().readLine(); 上面的代码编译是通过的,但运行是会分别报UnsupportedOperationException;NumberFormatException;NullPointerException异常,这些都是runtime error;
类型注解被用来支持在Java的程序中做强类型检查。配合插件式的check framework,可以在编译的时候检测出runtime error,以提高代码质量。这就是类型注解的作用了。
4. check framework
check framework是第三方工具,配合Java的类型注解效果就是1+1>2。它可以嵌入到javac编译器里面,可以配合ant和maven使用,也可以作为eclipse插件。地址是http://types.cs.washington.edu/checker-framework/。
check framework可以找到类型注解出现的地方并检查,举个简单的例子:
import checkers.nullness.quals.*;
public class GetStarted {
void sample() {
@NonNull Object ref = new Object();
}
}使用javac编译上面的类
javac -processor checkers.nullness.NullnessChecker GetStarted.java编译是通过,但如果修改成
@NonNull Object ref = null;再次编译,则出现
GetStarted.java:5: incompatible types.
found : @Nullable
required: @NonNull Object
@NonNull Object ref = null;
^ 1 error
如果你不想使用类型注解检测出来错误,则不需要processor,直接javac GetStarted.java是可以编译通过的,这是在java 8 with Type Annotation Support版本里面可以,但java 5,6,7版本都不行,因为javac编译器不知道@NonNull是什么东西,但check framework 有个向下兼容的解决方案,就是将类型注解nonnull用/**/注释起来
,比如上面例子修改为
import checkers.nullness.quals.*;
public class GetStarted {
void sample() {
/*@NonNull*/ Object ref = null;
}
}5.关于JSR 308
JSR 308想要解决在Java 1.5注解中出现的两个问题:
• 在句法上对注解的限制:只能把注解写在声明的地方
• 类型系统在语义上的限制:类型系统还做不到预防所有的bug
JSR 308 通过如下方法解决上述两个问题:
• 对Java语言的句法进行扩充,允许注解出现在更多的位置上。包括:方法接收器(method receivers,译注:例public int size() @Readonly { ... }),泛型参数,数组,类型转换,类型测试,对象创建,类型参数绑定,类继承和throws子句。其实就是类型注解,现在是java 8的一个特性
• 通过引入可插拔的类型系统(pluggable type systems)能够创建功能更强大的注解处理器。类型检查器对带有类型限定注解的源码进行分析,一旦发现不匹配等错误之处就会产生警告信息。其实就是check framework
对JSR308,有人反对,觉得更复杂更静态了,比如
@NotEmpty List<@NonNull String> strings = new ArrayList<@NonNull String>()> 换成动态语言为
var strings = ["one", "two"]; 有人赞成,说到底,代码才是“最根本”的文档。代码中包含的注解清楚表明了代码编写者的意图。当没有及时更新或者有遗漏的时候,恰恰是注解中包含的意图信息,最容易在其他文档中被丢失。而且将运行时的错误转到编译阶段,不但可以加速开发进程,还可以节省测试时检查bug的时间。
五、重复注解
1.总结
前面介绍了:
lambda表达式和默认方法 (JEP 126)
批量数据操作(JEP 107)
类型注解(JEP 104)
注:JEP=JDK Enhancement-Proposal (JDK 增强建议 ),每个JEP即一个新特性。
在java 8里面,注解一共有2个改进,一个是类型注解,在上篇已经介绍了,本篇将介绍另外一个注解的改进:重复注解(JEP 120)。
2.什么是重复注解
允许在同一申明类型(类,属性,或方法)的多次使用同一个注解
3.一个简单的例子
java 8之前也有重复使用注解的解决方案,但可读性不是很好,比如下面的代码:
public @interface Authority {
String role();
}
public @interface Authorities {
Authority[] value();
}
public class RepeatAnnotationUseOldVersion {
@Authorities({@Authority(role="Admin"),@Authority(role="Manager")})
public void doSomeThing(){
}
}由另一个注解来存储重复注解,在使用时候,用存储注解Authorities来扩展重复注解,我们再来看看java 8里面的做法:
@Repeatable(Authorities.class)
public @interface Authority {
String role();
}
public @interface Authorities {
Authority[] value();
}
public class RepeatAnnotationUseNewVersion {
@Authority(role="Admin")
@Authority(role="Manager")
public void doSomeThing(){ }
}不同的地方是,创建重复注解Authority时,加上@Repeatable,指向存储注解Authorities,在使用时候,直接可以重复使用Authority注解。从上面例子看出,java 8里面做法更适合常规的思维,可读性强一点
六、泛型的目标类型推断
1.简单理解泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。通俗点将就是“类型的变量”。这种类型变量可以用在类、接口和方法的创建中。
理解Java泛型最简单的方法是把它看成一种便捷语法,能节省你某些Java类型转换(casting)上的操作:
List box = new ArrayList();
box.add(new Apple());
Apple apple =box.get(0); 上面的代码自身已表达的很清楚:box是一个装有Apple对象的List。get方法返回一个Apple对象实例,这个过程不需要进行类型转换。没有泛型,上面的代码需要写成这样:
Apple apple = (Apple)box.get(0);2. 泛型的尴尬
泛型的最大优点是提供了程序的类型安全同时可以向后兼容,但也有尴尬的地方,就是每次定义时都要写明泛型的类型,这样显示指定不仅感觉有些冗长,最主要是很多程序员不熟悉泛型,因此很多时候不能够给出正确的类型参数,现在通过编译器自动推断泛型的参数类型,能够减少这样的情况,并提高代码可读性。
3.java7的泛型类型推断改进
在以前的版本中使用泛型类型,需要在声明并赋值的时候,两侧都加上泛型类型。例如:
Map<String, String> myMap = new HashMap<String, String>();你可能觉得:老子在声明变量的的时候已经指明了参数类型,为毛还要在初始化对象时再指定?幸好,在Java SE 7中,这种方式得以改进,现在你可以使用如下语句进行声明并赋值:
Map<String, String> myMap = new HashMap<>(); //注意后面的"<>" 在这条语句中,编译器会根据变量声明时的泛型类型自动推断出实例化HashMap时的泛型类型。再次提醒一定要注意new HashMap后面的“<>”,只有加上这个“<>”才表示是自动类型推断,否则就是非泛型类型的HashMap,并且在使用编译器编译源代码时会给出一个警告提示。
但是:Java SE 7在创建泛型实例时的类型推断是有限制的:只有构造器的参数化类型在上下文中被显著的声明了,才可以使用类型推断,否则不行。例如:下面的例子在java 7无法正确编译(但现在在java8里面可以编译,因为根据方法参数来自动推断泛型的类型):
List<String> list = new ArrayList<>();
list.add("A");
// 由于addAll期望获得Collection类型的参数,因此下面的语句无法通过
list.addAll(new ArrayList<>()); 4 Java8的泛型类型推断改进
java8里面泛型的目标类型推断主要2个:
1.支持通过方法上下文推断泛型目标类型
2.支持在方法调用链路当中,泛型类型推断传递到最一个方法
让我们看看官网的例子
class List {
static List nil() { ... };
static List cons(Z head, List tail) { ... };
E head() { ... }
} 根据JEP101的特性,我们在调用上面方法的时候可以这样写
//通过方法赋值的目标参数来自动推断泛型的类型
List<String> l = List.nil();
//而不是显示的指定类型
//List<String> l = List.<String>nil();
//通过前面方法参数类型推断泛型的类型
List.cons(42, List.nil());
//而不是显示的指定类型
//List.cons(42, List.<Integer>nil());总结
以上是JEP101的特性内容了,Java作为静态语言的代表者,可以说类型系统相当丰富。导致类型间互相转换的问题困扰着每个java程序员,通过编译器自动推断类型的东西可以稍微缓解一下类型转换太复杂的问题。 虽然说是小进步,但对于我们天天写代码的程序员,肯定能带来巨大的作用,至少心情更愉悦了~~说不定在java 9里面,我们会得到一个通用的类型var,像js或者scala的一些动态语言那样^_^
七、深入解析日期和时间-JSR310
日期是商业逻辑计算一个关键的部分,任何企业应用程序都需要处理时间问题。应用程序需要知道当前的时间点和下一个时间点,有时它们还必须计算这两个时间点之间的路径。但java之前的日期做法太令人恶心了,我们先来吐槽一下
1.吐槽java.util.Date跟Calendar
Tiago Fernandez做过一次投票,选举最烂的JAVA API,排第一的EJB2.X,第二的就是日期API。
1.1槽点一
最开始的时候,Date既要承载日期信息,又要做日期之间的转换,还要做不同日期格式的显示,职责较繁杂,后来从JDK 1.1 开始,这三项职责分开了:
• 使用Calendar类实现日期和时间字段之间转换;
• 使用DateFormat类来格式化和分析日期字符串;
• 而Date只用来承载日期和时间信息。
原有Date中的相应方法已废弃。不过,无论是Date,还是Calendar,都用着太不方便了,这是API没有设计好的地方。
1.2槽点二
坑爹的year和month
Date date = new Date(2012,1,1);
System.out.println(date);输出Thu Feb 01 00:00:00 CST 3912
观察输出结果,year是2012+1900,而month,月份参数我不是给了1吗?怎么输出二月(Feb)了?
应该曾有人告诉你,如果你要设置日期,应该使用 java.util.Calendar,像这样…
Calendar calendar = Calendar.getInstance();
calendar.set(2013, 8, 2);这样写又不对了,calendar的month也是从0开始的,表达8月份应该用7这个数字,要么就干脆用枚举
calendar.set(2013, Calendar.AUGUST, 2); 注意上面的代码,Calendar年份的传值不需要减去1900(当然月份的定义和Date还是一样),这种不一致真是让人抓狂!
有些人可能知道,Calendar相关的API是IBM捐出去的,所以才导致不一致。
1.3槽点三
java.util.Date与java.util.Calendar中的所有属性都是可变的
下面的代码,计算两个日期之间的天数….
public static void main(String[] args) {
Calendar birth = Calendar.getInstance();
birth.set(1975, Calendar.MAY, 26);
Calendar now = Calendar.getInstance();
System.out.println(daysBetween(birth, now));
System.out.println(daysBetween(birth, now)); // 显示 0?
}
public static long daysBetween(Calendar begin, Calendar end) {
long daysBetween = 0;
while(begin.before(end)) {
begin.add(Calendar.DAY_OF_MONTH, 1);
daysBetween++;
}
return daysBetween;
} daysBetween有点问题,如果连续计算两个Date实例的话,第二次会取得0,因为Calendar状态是可变的,考虑到重复计算的场合,最好复制一个新的Calendar
public static long daysBetween(Calendar begin, Calendar end) {
Calendar calendar = (Calendar) begin.clone(); // 复制
long daysBetween = 0;
while(calendar.before(end)) {
calendar.add(Calendar.DAY_OF_MONTH, 1);
daysBetween++;
}
return daysBetween;
}2.JSR310
以上种种,导致目前有些第三方的java日期库诞生,比如广泛使用的JODA-TIME,还有Date4j等,虽然第三方库已经足够强大,好用,但还是有兼容问题的,比如标准的JSF日期转换器与joda-time API就不兼容,你需要编写自己的转换器,所以标准的API还是必须的,于是就有了JSR310。
JSR 310实际上有两个日期概念。第一个是Instant,它大致对应于java.util.Date类,因为它代表了一个确定的时间点,即相对于标准Java纪元(1970年1月1日)的偏移量;但与java.util.Date类不同的是其精确到了纳秒级别。
第二个对应于人类自身的观念,比如LocalDate和LocalTime。他们代表了一般的时区概念,要么是日期(不包含时间),要么是时间(不包含日期),类似于java.sql的表示方式。此外,还有一个MonthDay,它可以存储某人的生日(不包含年份)。每个类都在内部存储正确的数据而不是像java.util.Date那样利用午夜12点来区分日期,利用1970-01-01来表示时间。
目前Java8已经实现了JSR310的全部内容。新增了java.time包定义的类表示了日期-时间概念的规则,包括instants, durations, dates, times, time-zones and periods。这些都是基于ISO日历系统,它又是遵循 Gregorian规则的。最重要的一点是值不可变,且线程安全,通过下面一张图,我们快速看下java.time包下的一些主要的类的值的格式,方便理解。
2.1方法概览
该包的API提供了大量相关的方法,这些方法一般有一致的方法前缀:
of:静态工厂方法。
parse:静态工厂方法,关注于解析。
get:获取某些东西的值。
is:检查某些东西的是否是true。
with:不可变的setter等价物。
plus:加一些量到某个对象。
minus:从某个对象减去一些量。
to:转换到另一个类型。
at:把这个对象与另一个对象组合起来,例如: date.atTime(time)。2.2 与旧的API对应关系

3.简单使用java.time的API
public class TimeIntroduction {
public static void testClock() throws InterruptedException {
//时钟提供给我们用于访问某个特定时区的瞬时时间、日期 和 时间的。
//系统默认UTC时钟(当前瞬时时间 System.currentTimeMillis())
Clock c1 = Clock.systemUTC();
// c1.millis()每次调用将返回当前瞬时时间(UTC)
System.out.println(c1.millis()); // 1428040817838
Clock c2 = Clock.systemDefaultZone(); //系统默认时区时钟(当前瞬时时间)
Clock c31 = Clock.system(ZoneId.of("Europe/Paris")); //巴黎时区
System.out.println(c31.millis()); // 1428040817903
Clock c32 = Clock.system(ZoneId.of("Asia/Shanghai"));//上海时区
System.out.println(c32.millis());//1428040817903
Clock c4 = Clock.fixed(Instant.now(), ZoneId.of("Asia/Shanghai"));
//固定上海时区时钟
System.out.println(c4.millis());//1428040817903
Thread.sleep(1000);
//不变即时钟时钟在那一个点不动
System.out.println(c4.millis());//1428040817903
//相对于系统默认时钟两秒的时钟
Clock c5 = Clock.offset(c1, Duration.ofSeconds(2));
System.out.println(c1.millis());//1428041153678
System.out.println(c5.millis());//1428041155678
}
public static void testInstant() {
//瞬时时间相当于以前的System.currentTimeMillis()
Instant instant1 = Instant.now();
//精确到秒 得到相对于1970-01-01 00:00:00 UTC的一个时间
System.out.println(instant1.getEpochSecond());//1428041228
System.out.println(instant1.toEpochMilli()); //精确到毫秒1428041228297
Clock clock1 = Clock.systemUTC(); //获取系统UTC默认时钟
Instant instant2 = Instant.now(clock1);//得到时钟的瞬时时间
System.out.println(instant2.toEpochMilli());//1428041228297
Clock clock2 = Clock.fixed(instant1, ZoneId.systemDefault());
//固定瞬时时间时钟
Instant instant3 = Instant.now(clock2);//得到时钟的瞬时时间
System.out.println(instant3.toEpochMilli());//1428041228297
}
public static void testLocalDateTime() {
//使用默认时区时钟瞬时时间创建 Clock.systemDefaultZone() -->
//即相对于 ZoneId.systemDefault()默认时区
LocalDateTime now = LocalDateTime.now();
System.out.println(now);// 2015-04-03T14:09:07.781
//自定义时区
LocalDateTime now2 = LocalDateTime.now(ZoneId.of("Europe/Paris"));
System.out.println(now2);//会以相应的时区显示日期2015-04-03T08:09:07.781
//自定义时钟
Clock clock = Clock.system(ZoneId.of("Asia/Dhaka"));
LocalDateTime now3 = LocalDateTime.now(clock);
System.out.println(now3);//会以相应的时区显示日期2015-04-03T12:09:07.796
//不需要写什么相对时间 如java.util.Date 年是相对于1900 月是从0开始
//2013-12-31 23:59
LocalDateTime d1 = LocalDateTime.of(2013, 12, 31, 23, 59);
//年月日 时分秒 纳秒
LocalDateTime d2 = LocalDateTime.of(2013, 12, 31, 23, 59, 59, 11);
//使用瞬时时间 + 时区
Instant instant = Instant.now();
LocalDateTime d3 = LocalDateTime.ofInstant(Instant.now(), ZoneId.systemDefault());
System.out.println(d3);// 2015-04-03T14:09:07.796
//解析String--->LocalDateTime
LocalDateTime d4 = LocalDateTime.parse("2013-12-31T23:59");
System.out.println(d4);// 2013-12-31T23:59
LocalDateTime d5 = LocalDateTime.parse("2013-12-31T23:59:59.999");
//999毫秒 等价于999000000纳秒
System.out.println(d5);// 2013-12-31T23:59:59.999
//使用DateTimeFormatter API 解析 和 格式化
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss");
LocalDateTime d6 = LocalDateTime.parse("2013/12/31 23:59:59", formatter);
System.out.println(formatter.format(d6));// 2013/12/31 23:59:59
//时间获取
System.out.println(d6.getYear());//2013
System.out.println(d6.getMonth());//DECEMBER
System.out.println(d6.getDayOfYear());//365
System.out.println(d6.getDayOfMonth());//31
System.out.println(d6.getDayOfWeek());//TUESDAY
System.out.println(d6.getHour());//23
System.out.println(d6.getMinute());//59
System.out.println(d6.getSecond());//59
System.out.println(d6.getNano());//0
//时间增减
LocalDateTime d7=d6.minusDays(1);//minusDays减去的天数,plusDays增加的天数
LocalDateTime d8 = d7.plus(1, IsoFields.QUARTER_YEARS);
//LocalDate 即年月日 无时分秒
//LocalTime即时分秒 无年月日
//API和LocalDateTime类似就不演示了
}
public static void testZonedDateTime() {
//即带有时区的date-time 存储纳秒、时区和时差(避免与本地date-time歧义)。
//API和LocalDateTime类似,只是多了时差(如
//2013-12-20T10:35:50.711+08:00[Asia/Shanghai])
ZonedDateTime now = ZonedDateTime.now();
System.out.println(now);// 2015-04-03T14:18:39.701+08:00[Asia/Shanghai]
ZonedDateTime now2 = ZonedDateTime.now(ZoneId.of("Europe/Paris"));
System.out.println(now2);// 2015-04-03T08:18:39.717+02:00[Europe/Paris]
//其他的用法也是类似的 就不介绍了
ZonedDateTime z1 = ZonedDateTime.parse("2013-12-31T23:59:59Z[Europe/Paris]");
System.out.println(z1);// 2013-12-31T23:59:59+01:00[Europe/Paris]
}
public static void testDuration() {
//表示两个瞬时时间的时间段
Duration d1 = Duration.between(Instant.ofEpochMilli(System.currentTimeMillis() - 12323123), Instant.now());
//得到相应的时差
System.out.println(d1.toDays());//0
System.out.println(d1.toHours());//3
System.out.println(d1.toMinutes());//205
System.out.println(d1.toMillis());//12323123
System.out.println(d1.toNanos());//12323123000000
//1天时差 类似的还有如ofHours()
Duration d2 = Duration.ofDays(1);
System.out.println(d2.toDays());//1
}
public static void testChronology() {
//提供对java.util.Calendar的替换,提供对年历系统的支持
Chronology c = HijrahChronology.INSTANCE;
ChronoLocalDateTime d = c.localDateTime(LocalDateTime.now());
System.out.println(d);// Hijrah-umalqura AH 1436-06-14T14:22:09.300
}
/**
* 新旧日期转换
*/
public static void testNewOldDateConversion(){
Instant instant=new Date().toInstant();
Date date=Date.from(instant);
System.out.println(instant);// 2015-04-03T06:22:55.793Z
System.out.println(date);// Fri Apr 03 14:22:55 CST 2015
}
public static void main(String[] args) throws InterruptedException {
testClock();
testInstant();
testLocalDateTime();
testZonedDateTime();
testDuration();
testChronology();
testNewOldDateConversion();
}
}4.与Joda-Time的区别
其实JSR310的规范领导者Stephen Colebourne,同时也是Joda-Time的创建者,JSR310是在Joda-Time的基础上建立的,参考了绝大部分的API,但并不是说JSR310=JODA-Time,下面几个比较明显的区别是
1. 最明显的变化就是包名(从org.joda.time以及java.time)
2. JSR310不接受NULL值,Joda-Time视NULL值为0
3. JSR310的计算机相关的时间(Instant)和与人类相关的时间(DateTime)之间的差别变得更明显
4. JSR310所有抛出的异常都是DateTimeException的子类。虽然DateTimeException是一个RuntimeException
5.总结
对比旧的日期API

日期与时间处理API,在各种语言中,可能都只是个不起眼的API,如果你没有较复杂的时间处理需求,可能只是利用日期与时间处理API取得系统时间,简单做些显示罢了,然而如果认真看待日期与时间,其复杂程度可能会远超过你的想象,天文、地理、历史、政治、文化等因素,都会影响到你对时间的处理。所以在处理时间上,最好选用JSR310(如果你用java8的话就实现310了),或者Joda-Time。
不止是java面临时间处理的尴尬,其他语言同样也遇到过类似的问题,比如
Arrow:Python 中更好的日期与时间处理库
Moment.js:JavaScript 中的日期库
Noda-Time:.NET 阵营的 Joda-Time 的复制八、StampedLock将是解决同步问题的新宠
Java8就像一个宝藏,一个小的API改进,也足与写一篇文章,比如同步,一直是多线程并发编程的一个老话题,相信没有人喜欢同步的代码,这会降低应用的吞吐量等性能指标,最坏的时候会挂起死机,但是即使这样你也没得选择,因为要保证信息的正确性。所以本文决定将从synchronized、Lock到Java8新增的StampedLock进行对比分析,相信StampedLock不会让大家失望。
1. synchronized
在java5之前,实现同步主要是使用synchronized。它是Java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。
有四种不同的同步块:
1. 实例方法
2. 静态方法
3. 实例方法中的同步块
4. 静态方法中的同步块
大家对此应该不陌生,所以不多讲了,以下是代码示例
synchronized(this)
// do operation
} 小结:在多线程并发编程中Synchronized一直是元老级角色,很多人都会称呼它为重量级锁,但是随着Java SE1.6对Synchronized进行了各种优化之后,性能上也有所提升。
2. Lock
它是Java 5在java.util.concurrent.locks新增的一个API。
Lock是一个接口,核心方法是lock(),unlock(),tryLock(),实现类有
ReentrantLock, ReentrantReadWriteLock.ReadLock, ReentrantReadWriteLock.WriteLock;
ReentrantReadWriteLock, ReentrantLock 和synchronized锁都有相同的内存语义。
与synchronized不同的是,Lock完全用Java写成,在java这个层面是无关JVM实现的。Lock提供更灵活的锁机制,很多synchronized 没有提供的许多特性,比如锁投票,定时锁等候和中断锁等候,但因为lock是通过代码实现的,要保证锁定一定会被释放,就必须将unLock()放到finally{}中
下面是Lock的一个代码示例
rwlock.writeLock().lock();
try {
// do operation
} finally {
rwlock.writeLock().unlock();
} 小结:比synchronized更灵活、更具可伸缩性的锁定机制,但不管怎么说还是synchronized代码要更容易书写些
3.StampedLock
它是java8在java.util.concurrent.locks新增的一个API。
ReentrantReadWriteLock 在沒有任何读写锁时,才可以取得写入锁,这可用于实现了悲观读取(Pessimistic Reading),即如果执行中进行读取时,经常可能有另一执行要写入的需求,为了保持同步,ReentrantReadWriteLock 的读取锁定就可派上用场。
然而,如果读取执行情况很多,写入很少的情况下,使用 ReentrantReadWriteLock 可能会使写入线程遭遇饥饿(Starvation)问题,也就是写入线程迟迟无法竞争到锁定而一直处于等待状态。
StampedLock控制锁有三种模式(写,读,乐观读),一个StampedLock状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据stamp,它用相应的锁状态表示并控制访问,数字0表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。
所谓的乐观读模式,也就是若读的操作很多,写的操作很少的情况下,你可以乐观地认为,写入与读取同时发生几率很少,因此不悲观地使用完全的读取锁定,程序可以查看读取资料之后,是否遭到写入执行的变更,再采取后续的措施(重新读取变更信息,或者抛出异常) ,这一个小小改进,可大幅度提高程序的吞吐量!!
下面是java doc提供的StampedLock一个例子
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
void move(double deltaX, double deltaY) { // an exclusively locked method
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
//下面看看乐观读锁案例
double distanceFromOrigin() { // A read-only method
long stamp = sl.tryOptimisticRead(); //获得一个乐观读锁
double currentX = x, currentY = y; //将两个字段读入本地局部变量
if (!sl.validate(stamp)) { //检查发出乐观读锁后同时是否有其他写锁发生?
stamp = sl.readLock(); //如果没有,我们再次获得一个读悲观锁
try {
currentX = x; // 将两个字段读入本地局部变量
currentY = y; // 将两个字段读入本地局部变量
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
//下面是悲观读锁案例
void moveIfAtOrigin(double newX, double newY) { // upgrade
// Could instead start with optimistic, not read mode
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) { //循环,检查当前状态是否符合
long ws = sl.tryConvertToWriteLock(stamp); //将读锁转为写锁
if (ws != 0L) { //这是确认转为写锁是否成功
stamp = ws; //如果成功 替换票据
x = newX; //进行状态改变
y = newY; //进行状态改变
break;
}else { //如果不能成功转换为写锁
sl.unlockRead(stamp); //我们显式释放读锁
stamp = sl.writeLock(); //显式直接进行写锁 然后再通过循环再试
}
}
} finally {
sl.unlock(stamp); //释放读锁或写锁
}
}
}小结:
StampedLock要比ReentrantReadWriteLock更加廉价,也就是消耗比较小。
4. StampedLock与ReadWriteLock性能对比
下图是和ReadWritLock相比,在一个线程情况下,是读速度其4倍左右,写是1倍。
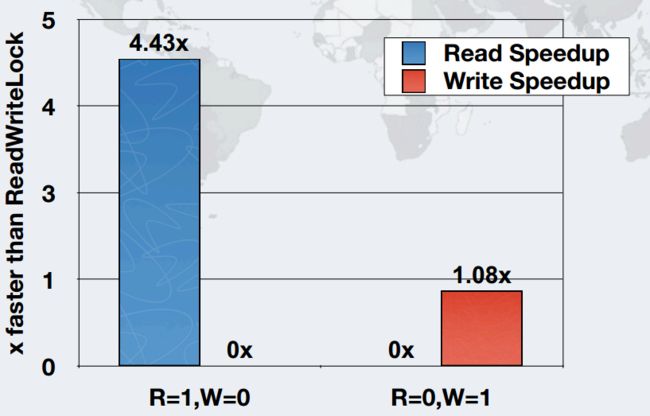
下图是六个线程情况下,读性能是其几十倍,写性能也是近10倍左右:

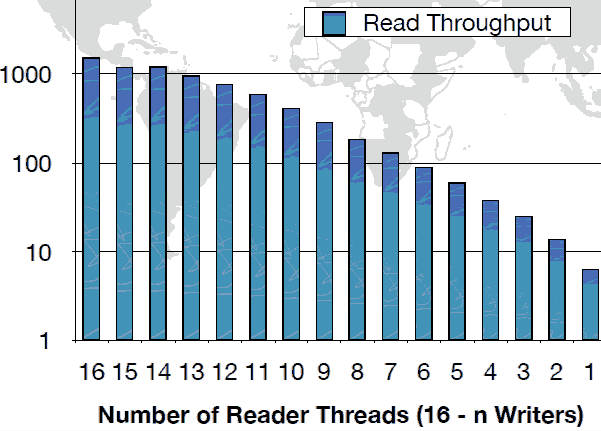
下图是吞吐量提高:
5.总结
5.1、synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定;
5.2、ReentrantLock、ReentrantReadWriteLock,、StampedLock都是对象层面的锁定,要保证锁定一定会被释放,就必须将unLock()放到finally{}中;
5.3、StampedLock 对吞吐量有巨大的改进,特别是在读线程越来越多的场景下;
5.4、StampedLock有一个复杂的API,对于加锁操作,很容易误用其他方法;
5.5、当只有少量竞争者的时候,synchronized是一个很好的通用的锁实现;
5.6、当线程增长能够预估,ReentrantLock是一个很好的通用的锁实现;
StampedLock 可以说是Lock的一个很好的补充,吞吐量以及性能上的提升足以打动很多人了,但并不是说要替代之前Lock的东西,毕竟他还是有些应用场景的,起码API比StampedLock容易入手.
九、Base64详解
BASE64 编码是一种常用的字符编码,在很多地方都会用到。但base64不是安全领域下的加密解密算法。能起到安全作用的效果很差,而且很容易破解,他核心作用应该是传输数据的正确性,有些网关或系统只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成ASCII字符的一种方法,而且base64特别适合在http,mime协议下快速传输数据。
1. JDK里面实现Base64的API
在JDK1.6之前,JDK核心类一直没有Base64的实现类,有人建议用Sun/Oracle JDK里面的sun.misc.BASE64Encoder 和 sun.misc.BASE64Decoder,使用它们的优点就是不需要依赖第三方类库,缺点就是可能在未来版本会被删除(用maven编译会发出警告),而且性能不佳,后面会有性能测试。
JDK1.6中添加了另一个Base64的实现,javax.xml.bind.DatatypeConverter两个静态方法parseBase64Binary 和 printBase64Binary,隐藏在javax.xml.bind包下面,不被很多开发者知道。
在Java 8在java.util包下面实现了BASE64编解码API,而且性能不俗,API也简单易懂,下面展示下这个类的使用例子。
2. java.util.Base64
该类提供了一套静态方法获取下面三种BASE64编解码器:
1)Basic编码:是标准的BASE64编码,用于处理常规的需求
// 编码
String asB64 = Base64.getEncoder()
.encodeToString("some string".getBytes("utf-8"));
System.out.println(asB64); // 输出为: c29tZSBzdHJpbmc=
// 解码
byte[] asBytes = Base64.getDecoder().decode("c29tZSBzdHJpbmc=");
System.out.println(new String(asBytes, "utf-8")); // 输出为: some string2)URL编码:使用下划线替换URL里面的反斜线“/”
String urlEncoded = Base64.getUrlEncoder()
.encodeToString("subjects?abcd".getBytes("utf-8"));
System.out.println("Using URL Alphabet: " + urlEncoded);
// 输出为:
Using URL Alphabet: c3ViamVjdHM_YWJjZA==3)MIME编码:使用基本的字母数字产生BASE64输出,而且对MIME格式友好:每一行输出不超过76个字符,而且每行以“\r\n”符结束。
StringBuilder sb = new StringBuilder();
for (int t = 0; t < 10; ++t) {
sb.append(UUID.randomUUID().toString());
}
byte[] toEncode = sb.toString().getBytes("utf-8");
String mimeEncoded = Base64.getMimeEncoder().encodeToString(toEncode);
System.out.println(mimeEncoded);2.总结
如果你需要一个性能好,可靠的Base64编解码器,不要找JDK外面的了,java8里面的java.util.Base64以及java6中隐藏很深的javax.xml.bind.DatatypeConverter,他们两个都是不错的选择。