flume大数据框架数据采集系统
flume是cloudera开源的数据采集系统,现在是apache基金会下的子项目,他是hadoop生态系统的日志采集系统,用途广泛,可以将日志、网络数据、kafka消息收集并存储在大数据hdfs系统之上。现在的flume其实已经不是最初的flume了,他其实是flume-ng,就是flume二代,我们下载最新的apache-flume解压之后,发现bin目录有flume-ng可执行程序,并没有flume可执行程序。
flume的安装其实很简单,直接下载二进制安装包,解压即可,运行环境需要jdk,设置JAVA_HOME,CLASSPATH
,PATH等环境变量,也是一般hadoop生态系统最基础的环境。
flume是由agent代理组成的,可以有多个代理,每个代理分为三个组件:信源-source,信道-channel,信宿-sink三部分,架构图如下所示:
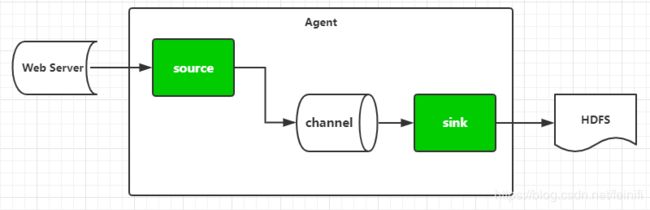
信源可以分为:
- directory:spooling directory source,采集目录中的日志。
- http:采集HTTP中的日志,一般设置type=netcat。
- kafka:作为kafka的一个topic的消费者,将kafka的消息收集到系统中。
信道可以分为:
- memory:信道的作用是缓存收集的数据,这里memory是指缓存在内存中,也是最常用的一种方式。
- jdbc:将收集的数据缓存在关系型数据库中。
- kafka:缓存到kafka中。
信宿可以分为:
- logger:flume采集的数据,最终是需要做存储的,一般是存储到文件系统,这种方式是存储在日志文件中,也是最简单的存储。
- hdfs:最常用的存储方式,就是放在hadoop分布式存储系统中,可以有多重稳定性、完整性的保证。
- hive:保存到hive中
- hbase:保存到hbase中
- kafka:这里是指将flume收集系统作为一个kafka的生产者,将消息写入kafka的一个topic中,等待被消费。
谈谈配置文件的配置:
一般是以agent的名称开头,比如agent为a1,然后指定三个组件的名称,比如:
a1.sources=s1
a1.channels=c1
a1.sinks=k1
s1表示agent的源为s1,c1表示agent的信道为c1,k1表示agent的信宿为k1。接下来具体指定每一个组件的类型和详细信息:
source
a1.sources.s1.type=netcat
a1.sources.s1.bind=0.0.0.0
a1.sources.s1.port=30000
channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=100
sink
a1.sinks.k1.type=logger
最后这两句就是将source和slink通过 channel关联起来:
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1
一般来说我们是按照source,channel,sink这么个顺序来配置,最终,利用channel将source与sink联系起来。但是这个配置里面,需要注意的地方是,我们配置source的channel是使用的channels,而配置sink的channel是使用的channel,这里需要我们格外的注意。
这里给出一个最简单的配置,默认收集来自http的数据,最终以日志的形式存储。
agent.sources = r1
agent.channels = memoryChannel
agent.sinks = loggerSink
agent.sources.r1.type = netcat
agent.sources.r1.bind = localhost
agent.sources.r1.port = 30000
agent.sources.r1.channels = memoryChannel
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memoryChannel
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 100部署测试:
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent -Dflume.root.logger=INFO,console
通过telnet命令连接localhost 30000,连接成功输入hello回车,然后输入flume回车,均显示发送成功。
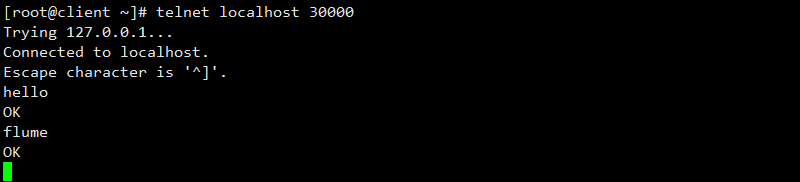
我们再看启动日志,发现日志中出现了hello,flume等信息,说明flume部署成功。

当我们以netcat作为source类型的时候,我们其实是在本机开启了一个socket监听服务,监听发送自本机端口为30000的http请求,我们查看本机端口信息:
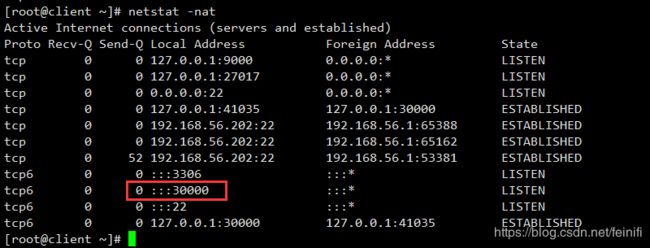
因此,我们才可以通过telnet访问本机的30000端口的http服务,并且模拟发送http请求数据。