android开发(性能篇)
今天想说的重点是Android APP性能优化,也就是在开发应用程序时应该注意的点有哪些,如何更好地提高用户体验。一个好的应用,除了要有吸引人的功能和交互之外,在性能上也应该有高的要求,即时应用非常具有特色,在产品前期可能吸引了部分用户,但是用户体验不好的话,也会给产品带来不好的口碑。那么一个好的应用应该如何定义呢?主要有以下三方面:
-
业务/功能
-
符合逻辑的交互
-
优秀的性能
众所周知,Android系统作为以移动设备为主的操作系统,硬件配置是有一定的限制的,虽然配置现在越来越高级,但仍然无法与PC相比,在CPU和内存上使用不合理或者耗费资源多时,就会碰到内存不足导致的稳定性问题、CPU 消耗太多导致的卡顿问题等。
面对问题时,大家想到的都是联系用户,然后查看日志,但殊不知有关性能类问题的反馈,原因也非常难找,日志大多用处不大,为何呢?因为性能问题大部分是非必现的问题,问题定位很难复现,而又没有关键的日志,当然就无法找到原因了。这些问题非常影响用户体验和功能使用,所以了解一些性能优化的一些解决方案就显得很重要了,并在实际的项目中优化我们的应用,进而提高用户体验。
四个方面
可以把用户体验的性能问题主要总结为4个类别:
-
流畅
-
稳定
-
省电、省流量
-
安装包小
性能问题的主要原因是什么,原因有相同的,也有不同的,但归根到底,不外乎内存使用、代码效率、合适的策略逻辑、代码质量、安装包体积这一类问题,整理归类如下: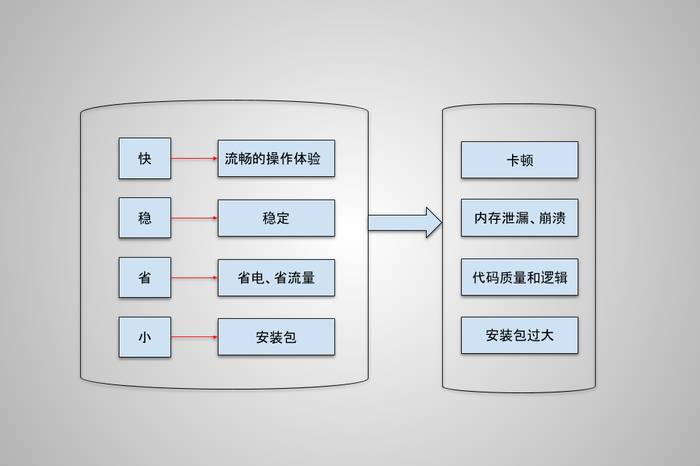
从图中可以看到,打造一个高质量的应用应该以4个方向为目标:快、稳、省、小。
-
快:使用时避免出现卡顿,响应速度快,减少用户等待的时间,满足用户期望。
-
稳:减低 crash 率和 ANR 率,不要在用户使用过程中崩溃和无响应。
-
省:节省流量和耗电,减少用户使用成本,避免使用时导致手机发烫。
-
小:安装包小可以降低用户的安装成本。
要想达到这4个目标,具体实现是在右边框里的问题:卡顿、内存使用不合理、代码质量差、代码逻辑乱、安装包过大,这些问题也是在开发过程中碰到最多的问题,在实现业务需求同时,也需要考虑到这点,多花时间去思考,如何避免功能完成后再来做优化,不然的话等功能实现后带来的维护成本会增加。
卡顿优化
Android 应用启动慢,使用时经常卡顿,是非常影响用户体验的,应该尽量避免出现。卡顿的场景有很多,按场景可以分为4类:UI 绘制、应用启动、页面跳转、事件响应,如图:
这4种卡顿场景的根本原因可以分为两大类:
-
界面绘制。主要原因是绘制的层级深、页面复杂、刷新不合理,由于这些原因导致卡顿的场景更多出现在UI和启动后的初始界面以及跳转到页面的绘制上。
-
数据处理。导致这种卡顿场景的原因是数据处理量太大,一般分为三种情况,一是数据在处理UI线程,二是数据处理占用CPU高,导致主线程拿不到时间片,三是内存增加导致GC频繁,从而引起卡顿。
引起卡顿的原因很多,但不管怎么样的原因和场景,最终都是通过设备屏幕上显示来达到用户,归根到底就是显示有问题,所以,要解决卡顿,就要先了解Android系统的显示原理。
Android系统显示原理
Android显示过程可以简单概括为:Android应用程序把经过测量、布局、绘制后的Surface缓存数据,通过SurfaceFlinger把数据渲染到显示屏幕上, 通过Android的刷新机制来刷新数据。也就是说应用层负责绘制,系统层负责渲染,通过进程间通信把应用层需要绘制的数据传递到系统层服务,系统层服务通过刷新机制把数据更新到屏幕上。
我们都知道在Android的每个View绘制中有三个核心步骤:Measure、Layout、Draw。具体实现是从 ViewRootImp类的performTraversals() 方法开始执行,Measure和Layout都是通过递归来获取View的大小和位置,并且以深度作为优先级,可以看出层级越深、元素越多、耗时也就越长。
真正把需要显示的数据渲染到屏幕上,是通过系统级进程中的SurfaceFlinger服务来实现的,那么这个SurfaceFlinger服务主要做了哪些工作呢?如下:
-
响应客户端事件,创建Layer与客户端的Surface建立连接。
-
接收客户端数据及属性,修改Layer属性,如尺寸、颜色、透明度等。
-
将创建的Layer内容刷新到屏幕上。
-
维持Layer的序列,并对Layer最终输出做出裁剪计算。
既然是两个不同的进程,那么肯定是需要一个跨进程的通信机制来实现数据传递,在Android显示系统中,使用了Android的匿名共享内存:SharedClient,每一个应用和SurfaceFlinger之间都会创建一个SharedClient ,然后在每个SharedClient中,最多可以创建31个 SharedBufferStack,每个Surface都对应一个SharedBufferStack,也就是一个Window。
一个SharedClient对应一个Android应用程序,而一个Android应用程序可能包含多个窗口,即Surface。也就是说SharedClient包含的是SharedBufferStack的集合,其中在显示刷新机制中用到了双缓冲和三重缓冲技术。最后总结起来显示整体流程分为三个模块:应用层绘制到缓存区,SurfaceFlinger把缓存区数据渲染到屏幕,由于是不同的进程,所以使用Android的匿名共享内存SharedClient缓存需要显示的数据来达到目的。
除此之外,我们还需要一个名词:FPS。FPS表示每秒传递的帧数。在理想情况下,60FPS就感觉不到卡,这意味着每个绘制时长应该在16ms以内。但是 Android系统很有可能无法及时完成那些复杂的页面渲染操作。Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染,如果每次渲染都成功,这样就能够达到流畅的画面所需的60FPS。如果某个操作花费的时间是24ms ,系统在得到VSYNC信号时就无法正常进行正常渲染,这样就发生了丢帧现象。那么用户在32ms内看到的会是同一帧画面,这种现象在执行动画或滑动列表比较常见,还有可能是你的Layout太过复杂,层叠太多的绘制单元,无法在16ms完成渲染,最终引起刷新不及时。
卡顿根本原因
根据Android系统显示原理可以看到,影响绘制的根本原因有以下两个方面:
-
绘制任务太重,绘制一帧内容耗时太长。
-
主线程太忙,根据系统传递过来的VSYNC信号来时还没准备好数据导致丢帧。
绘制耗时太长,有一些工具可以帮助我们定位问题。主线程太忙则需要注意了,主线程关键职责是处理用户交互,在屏幕上绘制像素,并进行加载显示相关的数据,所以特别需要避免任何主线程的事情,这样应用程序才能保持对用户操作的即时响应。总结起来,主线程主要做以下几个方面工作:
-
UI生命周期控制
-
系统事件处理
-
消息处理
-
界面布局
-
界面绘制
-
界面刷新
除此之外,应该尽量避免将其他处理放在主线程中,特别复杂的数据计算和网络请求等。
性能分析工具
性能问题并不容易复现,也不好定位,但是真的碰到问题还是需要去解决的,那么分析问题和确认问题是否解决,就需要借助相应的的调试工具,比如查看Layout层次的Hierarchy View、Android系统上带的GPU Profile工具和静态代码检查工具Lint等,这些工具对性能优化起到非常重要的作用,所以要熟悉,知道在什么场景用什么工具来分析。
1,Profile GPU Rendering
在手机开发者模式下,有一个卡顿检测工具叫做:Profile GPU Rendering,如图: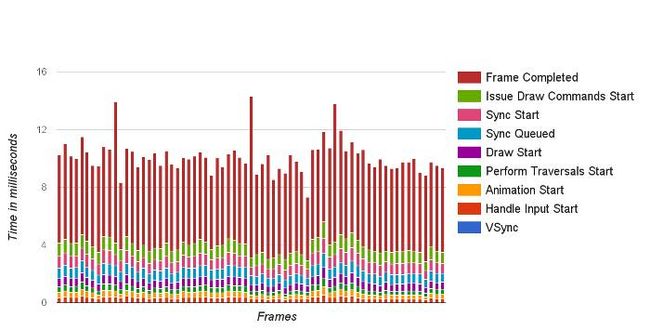
它的功能特点如下:
-
一个图形监测工具,能实时反应当前绘制的耗时
-
横轴表示时间,纵轴表示每一帧的耗时
-
随着时间推移,从左到右的刷新呈现
-
提供一个标准的耗时,如果高于标准耗时,就表示当前这一帧丢失
2,TraceView
TraceView是Android SDK自带的工具,用来分析函数调用过程,可以对Android的应用程序以及Framework层的代码进行性能分析。它是一个图形化的工具,最终会产生一个图表,用于对性能分析进行说明,可以分析到每一个方法的执行时间,其中可以统计出该方法调用次数和递归次数,实际时长等参数维度,使用非常直观,分析性能非常方便。
3,Systrace UI 性能分析
Systrace是Android 4.1及以上版本提供的性能数据采样和分析工具,它是通过系统的角度来返回一些信息。它可以帮助开发者收集Android关键子系统,如Surfaceflinger、WindowManagerService等Framework部分关键模块、服务、View系统等运行信息,从而帮助开发者更直观地分析系统瓶颈,改进性能。Systrace的功能包括跟踪系统的I/O操作、内核工作队列、CPU负载等,在UI显示性能分析上提供很好的数据,特别是在动画播放不流畅、渲染卡等问题上。
优化建议
1,布局优化
布局是否合理主要影响的是页面测量时间的多少,我们知道一个页面的显示测量和绘制过程都是通过递归来完成的,多叉树遍历的时间与树的高度h有关,其时间复杂度O(h),如果层级太深,每增加一层则会增加更多的页面显示时间,所以布局的合理性就显得很重要。
那布局优化有哪些方法呢,主要通过减少层级、减少测量和绘制时间、提高复用性三个方面入手。总结如下:
-
减少层级。合理使用RelativeLayout和LinerLayout,合理使用Merge。
-
提高显示速度。使用ViewStub,它是一个看不见的、不占布局位置、占用资源非常小的视图对象。
-
布局复用。可以通过
标签来提高复用。
-
尽可能少用wrap_content。wrap_content 会增加布局measure时计算成本,在已知宽高为固定值时,不用wrap_content 。
-
删除控件中无用的属性。
2,避免过度绘制
过度绘制是指在屏幕上的某个像素在同一帧的时间内被绘制了多次。在多层次重叠的UI结构中,如果不可见的UI也在做绘制的操作,就会导致某些像素区域被绘制了多次,从而浪费了多余的CPU以及GPU源。
如何避免过度绘制呢,如下:
-
布局上的优化。移除XML中非必须的背景,移除Window默认的背景、按需显示占位背景图片
-
自定义View优化。使用 canvas.clipRect()来帮助系统识别那些可见的区域,只有在这个区域内才会被绘制。
3,启动优化
通过对启动速度的监控,发现影响启动速度的问题所在,优化启动逻辑,提高应用的启动速度。启动主要完成三件事:UI布局、绘制和数据准备。因此启动速度优化就是需要优化这三个过程:
-
UI布局。应用一般都有闪屏页,优化闪屏页的UI布局,可以通过Profile GPU Rendering检测丢帧情况。
-
启动加载逻辑优化。可以采用分布加载、异步加载、延期加载策略来提高应用启动速度。
-
数据准备。数据初始化分析,加载数据可以考虑用线程初始化等策略。
4,合理的刷新机制
在应用开发过程中,因为数据的变化,需要刷新页面来展示新的数据,但频繁刷新会增加资源开销,并且可能导致卡顿发生,因此,需要一个合理的刷新机制来提高整体的UI流畅度。合理的刷新需要注意以下几点:
-
尽量减少刷新次数。
-
尽量避免后台有高的CPU线程运行。
-
缩小刷新区域。
5,其他
在实现动画效果时,需要根据不同场景选择合适的动画框架来实现。有些情况下,可以用硬件加速方式来提供流畅度。
内存优化
在Android系统中有个垃圾内存回收机制,在虚拟机层自动分配和释放内存,因此不需要在代码中分配和释放某一块内存,从应用层面上不容易出现内存泄漏和内存溢出等问题,但是需要内存管理。Android系统在内存管理上有一个Generational Heap Memory模型,内存回收的大部分压力不需要应用层关心,Generational Heap Memory有自己一套管理机制,当内存达到一个阈值时,系统会根据不同的规则自动释放系统认为可以释放的内存,也正是因为Android程序把内存控制的权力交给了Generational Heap Memory,一旦出现内存泄漏和溢出方面的问题,排查错误将会成为一项异常艰难的工作。除此之外,部分Android应用开发人员在开发过程中并没有特别关注内存的合理使用,也没有在内存方面做太多的优化,当应用程序同时运行越来越多的任务,加上越来越复杂的业务需求时,完全依赖Android的内存管理机制就会导致一系列性能问题逐渐呈现,对应用的稳定性和性能带来不可忽视的影响,因此,解决内存问题和合理优化内存是非常有必要的。
Android内存管理机制
Android应用都是在 Android的虚拟机上运行,应用 程序的内存分配与垃圾回收都是由虚拟机完成的。在Android系统,虚拟机有两种运行模式:Dalvik和ART。
1,Java对象生命周期
一般Java对象在虚拟机上有7个运行阶段:
创建阶段->应用阶段->不可见阶段->不可达阶段->收集阶段->终结阶段->对象空间重新分配阶段
2,内存分配
在Android系统中,内存分配实际上是对堆的分配和释放。当一个Android程序启动,应用进程都是从一个叫做Zygote的进程衍生出来,系统启动 Zygote 进程后,为了启动一个新的应用程序进程,系统会衍生Zygote进程生成一个新的进程,然后在新的进程中加载并运行应用程序的代码。其中,大多数的RAM pages被用来分配给Framework代码,同时促使RAM资源能够在应用所有进程之间共享。
但是为了整个系统的内存控制需要,Android系统会为每一个应用程序都设置一个硬性的Dalvik Heap Size最大限制阈值,整个阈值在不同设备上会因为RAM大小不同而有所差异。如果应用占用内存空间已经接近整个阈值时,再尝试分配内存的话,就很容易引起内存溢出的错误。
3,内存回收机制
我们需要知道的是,在Java中内存被分为三个区域:Young Generation(年轻代)、Old Generation(年老代)、Permanent Generation(持久代)。最近分配的对象会存放在Young Generation区域。对象在某个时机触发GC回收垃圾,而没有回收的就根据不同规则,有可能被移动到Old Generation,最后累积一定时间在移动到Permanent Generation 区域。系统会根据内存中不同的内存数据类型分别执行不同的GC操作。GC通过确定对象是否被活动对象引用来确定是否收集对象,进而动态回收无任何引用的对象占据的内存空间。但需要注意的是频繁的GC会增加应用的卡顿情况,影响应用的流畅性,因此需要尽量减少系统GC行为,以便提高应用的流畅度,减小卡顿发生的概率。
内存分析工具
做内存优化前,需要了解当前应用的内存使用现状,通过现状去分析哪些数据类型有问题,各种类型的分布情况如何,以及在发现问题后如何发现是哪些具体对象导致的,这就需要相关工具来帮助我们。
1,Memory Monitor
Memory Monitor是一款使用非常简单的图形化工具,可以很好地监控系统或应用的内存使用情况,主要有以下功能:
-
显示可用和已用内存,并且以时间为维度实时反应内存分配和回收情况。
-
快速判断应用程序的运行缓慢是否由于过度的内存回收导致。
-
快速判断应用是否由于内存不足导致程序崩溃。
2,Heap Viewer
Heap Viewer的主要功能是查看不同数据类型在内存中的使用情况,可以看到当前进程中的Heap Size的情况,分别有哪些类型的数据,以及各种类型数据占比情况。通过分析这些数据来找到大的内存对象,再进一步分析这些大对象,进而通过优化减少内存开销,也可以通过数据的变化发现内存泄漏。
3,Allocation Tracker
Memory Monitor和Heap Viewer都可以很直观且实时地监控内存使用情况,还能发现内存问题,但发现内存问题后不能再进一步找到原因,或者发现一块异常内存,但不能区别是否正常,同时在发现问题后,也不能定位到具体的类和方法。这时就需要使用另一个内存分析工具Allocation Tracker,进行更详细的分析,Allocation Tracker可以分配跟踪记录应用程序的内存分配,并列出了它们的调用堆栈,可以查看所有对象内存分配的周期。
4,Memory Analyzer Tool(MAT)
MAT是一个快速,功能丰富的Java Heap分析工具,通过分析Java进程的内存快照HPROF分析,从众多的对象中分析,快速计算出在内存中对象占用的大小,查看哪些对象不能被垃圾收集器回收,并可以通过视图直观地查看可能造成这种结果的对象。
常见内存泄漏场景
如果在内存泄漏发生后再去找原因并修复会增加开发的成本,最好在编写代码时就能够很好地考虑内存问题,写出更高质量的代码,这里列出一些常见的内存泄漏场景,在以后的开发过程中需要避免这类问题。
-
资源性对象未关闭。比如Cursor、File文件等,往往都用了一些缓冲,在不使用时,应该及时关闭它们。
-
注册对象未注销。比如事件注册后未注销,会导致观察者列表中维持着对象的引用。
-
类的静态变量持有大数据对象。
-
非静态内部类的静态实例。
-
Handler临时性内存泄漏。如果Handler是非静态的,容易导致Activity或Service不会被回收。
-
容器中的对象没清理造成的内存泄漏。
-
WebView。WebView存在着内存泄漏的问题,在应用中只要使用一次WebView,内存就不会被释放掉。
除此之外,内存泄漏可监控,常见的就是用LeakCanary第三方库,这是一个检测内存泄漏的开源库,使用非常简单,可以在发生内存泄漏时告警,并且生成leak tarce分析泄漏位置,同时可以提供Dump文件进行分析。
优化内存空间
没有内存泄漏,并不意味着内存就不需要优化,在移动设备上,由于物理设备的存储空间有限,Android 系统对每个应用进程也都分配了有限的堆内存,因此使用最小内存对象或者资源可以减小内存开销,同时让GC 能更高效地回收不再需要使用的对象,让应用堆内存保持充足的可用内存,使应用更稳定高效地运行。常见做法如下:
-
对象引用。强引用、软引用、弱引用、虚引用四种引用类型,根据业务需求合理使用不同,选择不同的引用类型。
-
减少不必要的内存开销。注意自动装箱,增加内存复用,比如有效利用系统自带的资源、视图复用、对象池、Bitmap对象的复用。
-
使用最优的数据类型。比如针对数据类容器结构,可以使用ArrayMap数据结构,避免使用枚举类型,使用缓存Lrucache等等。
-
图片内存优化。可以设置位图规格,根据采样因子做压缩,用一些图片缓存方式对图片进行管理等等。
稳定性优化
Android应用的稳定性定义很宽泛,影响稳定性的原因很多,比如内存使用不合理、代码异常场景考虑不周全、代码逻辑不合理等,都会对应用的稳定性造成影响。其中最常见的两个场景是:Crash和ANR,这两个错误将会使得程序无法使用,比较常用的解决方式如下:
-
提高代码质量。比如开发期间的代码审核,看些代码设计逻辑,业务合理性等。
-
代码静态扫描工具。常见工具有Android Lint、Findbugs、Checkstyle、PMD等等。
-
Crash监控。把一些崩溃的信息,异常信息及时地记录下来,以便后续分析解决。
-
Crash上传机制。在Crash后,尽量先保存日志到本地,然后等下一次网络正常时再上传日志信息。
耗电优化
在移动设备中,电池的重要性不言而喻,没有电什么都干不成。对于操作系统和设备开发商来说,耗电优化一致没有停止,去追求更长的待机时间,而对于一款应用来说,并不是可以忽略电量使用问题,特别是那些被归为“电池杀手”的应用,最终的结果是被卸载。因此,应用开发者在实现需求的同时,需要尽量减少电量的消耗。
在Android5.0以前,在应用中测试电量消耗比较麻烦,也不准确,5.0之后专门引入了一个获取设备上电量消耗信息的API:Battery Historian。Battery Historian是一款由Google提供的Android系统电量分析工具,和Systrace一样,是一款图形化数据分析工具,直观地展示出手机的电量消耗过程,通过输入电量分析文件,显示消耗情况,最后提供一些可供参考电量优化的方法。
除此之外,还有一些常用方案可提供:
-
计算优化,避开浮点运算等。
-
避免WaleLock使用不当。
-
使用Job Scheduler。
安装包大小优化
应用安装包大小对应用使用没有影响,但应用的安装包越大,用户下载的门槛越高,特别是在移动网络情况下,用户在下载应用时,对安装包大小的要求更高,因此,减小安装包大小可以让更多用户愿意下载和体验产品。
常用应用安装包的构成,如图所示:
从图中我们可以看到:
-
assets文件夹。存放一些配置文件、资源文件,assets不会自动生成对应的 ID,而是通过AssetManager类的接口获取。
-
res。res是resource的缩写,这个目录存放资源文件,会自动生成对应的ID并映射到 .R文件中,访问直接使用资源ID。
-
META-INF。保存应用的签名信息,签名信息可以验证APK文件的完整性。
-
AndroidManifest.xml。这个文件用来描述Android应用的配置信息,一些组件的注册信息、可使用权限等。
-
classes.dex。Dalvik字节码程序,让Dalvik虚拟机可执行,一般情况下,Android应用在打包时通过Android SDK中的dx工具将Java字节码转换为Dalvik字节码。
-
resources.arsc。记录着资源文件和资源ID之间的映射关系,用来根据资源ID寻找资源。
减少安装包大小的常用方案:
-
代码混淆。使用ProGuard代码混淆器工具,它包括压缩、优化、混淆等功能。
-
资源优化。比如使用Android Lint删除冗余资源,资源文件最少化等。
-
图片优化。比如利用AAPT工具对PNG格式的图片做压缩处理,降低图片色彩位数等。
-
避免重复功能的库,使用WebP图片格式等。
-
插件化。比如功能模块放在服务器上,按需下载,可以减少安装包大小。
This document primarily covers micro-optimizations that can improve overall app performance when combined, but it's unlikely that these changes will result in dramatic performance effects. Choosing the right algorithms and data structures should always be your priority, but is outside the scope of this document. You should use the tips in this document as general coding practices that you can incorporate into your habits for general code efficiency.
There are two basic rules for writing efficient code:
Don't do work that you don't need to do.
Don't allocate memory if you can avoid it.
One of the trickiest problems you'll face when micro-optimizing an Android app is that your app is certain to be running on multiple types of hardware. Different versions of the VM running on different processors running at different speeds. It's not even generally the case that you can simply say "device X is a factor F faster/slower than device Y", and scale your results from one device to others. In particular, measurement on the emulator tells you very little about performance on any device. There are also huge differences between devices with and without a JIT: the best code for a device with a JIT is not always the best code for a device without.
To ensure your app performs well across a wide variety of devices, ensure your code is efficient at all levels and agressively optimize your performance.
Avoid Creating Unnecessary Objects
Object creation is never free. A generational garbage collector with per-thread allocation pools for temporary objects can make allocation cheaper, but allocating memory is always more expensive than not allocating memory.
As you allocate more objects in your app, you will force a periodic garbage collection, creating little "hiccups" in the user experience. The concurrent garbage collector introduced in Android 2.3 helps, but unnecessary work should always be avoided.
Thus, you should avoid creating object instances you don't need to. Some examples of things that can help:
If you have a method returning a string, and you know that its result will always be appended to a
StringBuffer
anyway, change your signature and implementation so that the function does the append directly, instead of creating a short-lived temporary object.
When extracting strings from a set of input data, try to return a substring of the original data, instead of creating a copy. You will create a new
String
object, but it will share the
char[]
with the data. (The trade-off being that if you're only using a small part of the original input, you'll be keeping it all around in memory anyway if you go this route.)
A somewhat more radical idea is to slice up multidimensional arrays into parallel single one-dimension arrays:
An array of
int
s is a much better than an array of
Integer
objects, but this also generalizes to the fact that two parallel arrays of ints are also a lot more efficient than an array of
(int,int)
objects. The same goes for any combination of primitive types.
If you need to implement a container that stores tuples of
(Foo,Bar)
objects, try to remember that two parallel
Foo[]
and
Bar[]
arrays are generally much better than a single array of custom
(Foo,Bar)
objects. (The exception to this, of course, is when you're designing an API for other code to access. In those cases, it's usually better to make a small compromise to the speed in order to achieve a good API design. But in your own internal code, you should try and be as efficient as possible.)
Generally speaking, avoid creating short-term temporary objects if you can. Fewer objects created mean less-frequent garbage collection, which has a direct impact on user experience.
Prefer Static Over Virtual
If you don't need to access an object's fields, make your method static. Invocations will be about 15%-20% faster. It's also good practice, because you can tell from the method signature that calling the method can't alter the object's state.
Use Static Final For Constants
Consider the following declaration at the top of a class:
static int intVal = 42;
static String strVal = "Hello, world!";The compiler generates a class initializer method, called
, that is executed when the class is first used. The method stores the value 42 into
intVal
, and extracts a reference from the classfile string constant table for
strVal
. When these values are referenced later on, they are accessed with field lookups.
We can improve matters with the "final" keyword:
static final int intVal = 42;
static final String strVal = "Hello, world!";The class no longer requires a
method, because the constants go into static field initializers in the dex file. Code that refers to
intVal
will use the integer value 42 directly, and accesses to
strVal
will use a relatively inexpensive "string constant" instruction instead of a field lookup.
Note: This optimization applies only to primitive types and
String
constants, not arbitrary reference types. Still, it's good practice to declare constants
static final
whenever possible.
Avoid Internal Getters/Setters
In native languages like C++ it's common practice to use getters (
i = getCount()
) instead of accessing the field directly (
i = mCount
). This is an excellent habit for C++ and is often practiced in other object oriented languages like C# and Java, because the compiler can usually inline the access, and if you need to restrict or debug field access you can add the code at any time.
However, this is a bad idea on Android. Virtual method calls are expensive, much more so than instance field lookups. It's reasonable to follow common object-oriented programming practices and have getters and setters in the public interface, but within a class you should always access fields directly.
Without a JIT, direct field access is about 3x faster than invoking a trivial getter. With the JIT (where direct field access is as cheap as accessing a local), direct field access is about 7x faster than invoking a trivial getter.
Note that if you're using ProGuard, you can have the best of both worlds because ProGuard can inline accessors for you.
Use Enhanced For Loop Syntax
The enhanced
for
loop (also sometimes known as "for-each" loop) can be used for collections that implement the
Iterable
interface and for arrays. With collections, an iterator is allocated to make interface calls to
hasNext()
and
next()
. With an
ArrayList
, a hand-written counted loop is about 3x faster (with or without JIT), but for other collections the enhanced for loop syntax will be exactly equivalent to explicit iterator usage.
There are several alternatives for iterating through an array:
static class Foo {
int mSplat;
}
Foo[] mArray = ...
public void zero() {
int sum = 0;
for (int i = 0; i < mArray.length; ++i) {
sum += mArray[i].mSplat;
}
}
public void one() {
int sum = 0;
Foo[] localArray = mArray;
int len = localArray.length;
for (int i = 0; i < len; ++i) {
sum += localArray[i].mSplat;
}
}
public void two() {
int sum = 0;
for (Foo a : mArray) {
sum += a.mSplat;
}
}
zero()
is slowest, because the JIT can't yet optimize away the cost of getting the array length once for every iteration through the loop.
one()
is faster. It pulls everything out into local variables, avoiding the lookups. Only the array length offers a performance benefit.
two()
is fastest for devices without a JIT, and indistinguishable from one() for devices with a JIT. It uses the enhanced for loop syntax introduced in version 1.5 of the Java programming language.
So, you should use the enhanced
for
loop by default, but consider a hand-written counted loop for performance-critical
ArrayList
iteration.
Tip:Also see Josh Bloch's Effective Java, item 46.
Consider Package Instead of Private Access with Private Inner Classes
Consider the following class definition:
public class Foo {
private class Inner {
void stuff() {
Foo.this.doStuff(Foo.this.mValue);
}
}
private int mValue;
public void run() {
Inner in = new Inner();
mValue = 27;
in.stuff();
}
private void doStuff(int value) {
System.out.println("Value is " + value);
}
}What's important here is that we define a private inner class (
Foo$Inner
) that directly accesses a private method and a private instance field in the outer class. This is legal, and the code prints "Value is 27" as expected.
The problem is that the VM considers direct access to
Foo
's private members from
Foo$Inner
to be illegal because
Foo
and
Foo$Inner
are different classes, even though the Java language allows an inner class to access an outer class' private members. To bridge the gap, the compiler generates a couple of synthetic methods:
/*package*/ static int Foo.access$100(Foo foo) {
return foo.mValue;
}
/*package*/ static void Foo.access$200(Foo foo, int value) {
foo.doStuff(value);
}The inner class code calls these static methods whenever it needs to access the
mValue
field or invoke the
doStuff()
method in the outer class. What this means is that the code above really boils down to a case where you're accessing member fields through accessor methods. Earlier we talked about how accessors are slower than direct field accesses, so this is an example of a certain language idiom resulting in an "invisible" performance hit.
If you're using code like this in a performance hotspot, you can avoid the overhead by declaring fields and methods accessed by inner classes to have package access, rather than private access. Unfortunately this means the fields can be accessed directly by other classes in the same package, so you shouldn't use this in public API.
Avoid Using Floating-Point
As a rule of thumb, floating-point is about 2x slower than integer on Android-powered devices.
In speed terms, there's no difference between
float
and
double
on the more modern hardware. Space-wise,
double
is 2x larger. As with desktop machines, assuming space isn't an issue, you should prefer
double
to
float
.
Also, even for integers, some processors have hardware multiply but lack hardware divide. In such cases, integer division and modulus operations are performed in software—something to think about if you're designing a hash table or doing lots of math.
Know and Use the Libraries
In addition to all the usual reasons to prefer library code over rolling your own, bear in mind that the system is at liberty to replace calls to library methods with hand-coded assembler, which may be better than the best code the JIT can produce for the equivalent Java. The typical example here is
String.indexOf()
and related APIs, which Dalvik replaces with an inlined intrinsic. Similarly, the
System.arraycopy()
method is about 9x faster than a hand-coded loop on a Nexus One with the JIT.
Tip:Also see Josh Bloch's Effective Java, item 47.
Use Native Methods Carefully
Developing your app with native code using theAndroid NDKisn't necessarily more efficient than programming with the Java language. For one thing, there's a cost associated with the Java-native transition, and the JIT can't optimize across these boundaries. If you're allocating native resources (memory on the native heap, file descriptors, or whatever), it can be significantly more difficult to arrange timely collection of these resources. You also need to compile your code for each architecture you wish to run on (rather than rely on it having a JIT). You may even have to compile multiple versions for what you consider the same architecture: native code compiled for the ARM processor in the G1 can't take full advantage of the ARM in the Nexus One, and code compiled for the ARM in the Nexus One won't run on the ARM in the G1.
Native code is primarily useful when you have an existing native codebase that you want to port to Android, not for "speeding up" parts of your Android app written with the Java language.
If you do need to use native code, you should read ourJNI Tips.
Tip:Also see Josh Bloch's Effective Java, item 54.
Performance Myths
On devices without a JIT, it is true that invoking methods via a variable with an exact type rather than an interface is slightly more efficient. (So, for example, it was cheaper to invoke methods on a
HashMap map
than a
Map map
, even though in both cases the map was a
HashMap
.) It was not the case that this was 2x slower; the actual difference was more like 6% slower. Furthermore, the JIT makes the two effectively indistinguishable.
On devices without a JIT, caching field accesses is about 20% faster than repeatedly accesssing the field. With a JIT, field access costs about the same as local access, so this isn't a worthwhile optimization unless you feel it makes your code easier to read. (This is true of final, static, and static final fields too.)
Always Measure
Before you start optimizing, make sure you have a problem that you need to solve. Make sure you can accurately measure your existing performance, or you won't be able to measure the benefit of the alternatives you try.
Every claim made in this document is backed up by a benchmark. The source to these benchmarks can be found in the code.google.com "dalvik" project.
The benchmarks are built with theCaliper microbenchmarking framework for Java. Microbenchmarks are hard to get right, so Caliper goes out of its way to do the hard work for you, and even detect some cases where you're not measuring what you think you're measuring (because, say, the VM has managed to optimize all your code away). We highly recommend you use Caliper to run your own microbenchmarks.
You may also findTraceview useful for profiling, but it's important to realize that it currently disables the JIT, which may cause it to misattribute time to code that the JIT may be able to win back. It's especially important after making changes suggested by Traceview data to ensure that the resulting code actually runs faster when run without Traceview.
For more help profiling and debugging your apps, see the following documents:
Profiling with Traceview and dmtracedump
Analysing Display and Performance with Systrace
最近做一个android 的应用程序 总是出现内存高 和cpu高的问题困扰了好多天。
下面为自己从网上总结的和自己找到的问题。
1. WebView 控件:
使用了 WebView 控件一定要注意清理缓存 destroy() 方法,但之前必须调用 removeAllViews() 要不然有时出错
myWebView.removeAllViews();
myWebView.destroy();
2.线程
在退出活动窗口时一定要注意开启的线程是否已经关闭,可以在debug查看线程的开启情况。
如果只是刷新Ui线程 建议不用线程可以使用 Handler 来刷新 方法如下。这种方法只能做简单的操作,复杂操作建议使用线程。
private Handler _ui_handler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case 0://下面你可以写你需要处理的代码
_ui_handler .sendEmptyMessageDelayed(0,1000)//1000 为延时发送的时间 单位是毫秒
break;
}
}
}
3 sqlite
使用sqlite是一定要注意 关闭当前指针 和数据库连接
下面为注意内存溢出的问题
各位兄弟姐妹,Java开发中的内存泄露的问题经常会给我们带来很多烦恼。特别是对一些新手,如果平时不注意一些细节问题,最后很可能会导致很严重的后果。
在Android中的Java开发也同样会有这样的问题。附件中的pdf整理了一些关于Android中的Java开发,在内存使用方面需要注意的一些问题,希望能够对大家有所帮助。
接下篇: [Android] 内存泄漏调试经验分享 (二)
Android 内存泄漏调试
一、概述 1
二、Android(Java)中常见的容易引起内存泄漏的不良代码 1
(一) 查询数据库没有关闭游标 2
(二) 构造Adapter时,没有使用缓存的 convertView 3
(三) Bitmap对象不在使用时调用recycle()释放内存 4
(四) 释放对象的引用 4
(五) 其他 5
三、内存监测工具 DDMS --> Heap 5
四、内存分析工具 MAT(Memory Analyzer Tool) 7
(一) 生成.hprof文件 7
(二) 使用MAT导入.hprof文件 8
(三) 使用MAT的视图工具分析内存 8
一、概述
Java编程中经常容易被忽视,但本身又十分重要的一个问题就是内存 使用的问题。Android应用主要使用Java语言编写,因此这个问题也同样会在Android开发中出现。本文不对Java编程问题做探讨,而是对于 在Android中,特别是应用开发中的此类问题进行整理。
由于作者接触Android时间并不是很长,因此如有叙述不当之处,欢迎指正。
二、Android(Java)中常见的容易引起内存泄漏的不良代码
Android主要应用在嵌入式设备当中,而嵌入式设备由于一些众所 周知的条件限制,通常都不会有很高的配置,特别是内存是比较有限的。如果我们编写的代码当中有太多的对内存使用不当的地方,难免会使得我们的设备运行缓 慢,甚至是死机。为了能够使得Android应用程序安全且快速的运行,Android的每个应用程序都会使用一个专有的Dalvik虚拟机实例来运行, 它是由Zygote服务进程孵化出来的,也就是说每个应用程序都是在属于自己的进程中运行的。一方面,如果程序在运行过程中出现了内存泄漏的问题,仅仅会 使得自己的进程被kill掉,而不会影响其他进程(如果是system_process等系统进程出问题的话,则会引起系统重启)。另一方面 Android为不同类型的进程分配了不同的内存使用上限,如果应用进程使用的内存超过了这个上限,则会被系统视为内存泄漏,从而被kill掉。 Android为应用进程分配的内存上限如下所示:
位置: /ANDROID_SOURCE/system/core/rootdir/init.rc 部分脚本
# Define the oom_adj values for the classes of processes that can be
# killed by the kernel. These are used in ActivityManagerService.
setprop ro.FOREGROUND_APP_ADJ 0
setprop ro.VISIBLE_APP_ADJ 1
setprop ro.SECONDARY_SERVER_ADJ 2
setprop ro.BACKUP_APP_ADJ 2
setprop ro.HOME_APP_ADJ 4
setprop ro.HIDDEN_APP_MIN_ADJ 7
setprop ro.CONTENT_PROVIDER_ADJ 14
setprop ro.EMPTY_APP_ADJ 15
# Define the memory thresholds at which the above process classes will
# be killed. These numbers are in pages (4k).
setprop ro.FOREGROUND_APP_MEM 1536
setprop ro.VISIBLE_APP_MEM 2048
setprop ro.SECONDARY_SERVER_MEM 4096
setprop ro.BACKUP_APP_MEM 4096
setprop ro.HOME_APP_MEM 4096
setprop ro.HIDDEN_APP_MEM 5120
setprop ro.CONTENT_PROVIDER_MEM 5632
setprop ro.EMPTY_APP_MEM 6144
# Write value must be consistent with the above properties.
# Note that the driver only supports 6 slots, so we have HOME_APP at the
# same memory level as services.
write /sys/module/lowmemorykiller/parameters/adj 0,1,2,7,14,15
write /proc/sys/vm/overcommit_memory 1
write /proc/sys/vm/min_free_order_shift 4
write /sys/module/lowmemorykiller/parameters/minfree 1536,2048,4096,5120,5632,6144
# Set init its forked children's oom_adj.
write /proc/1/oom_adj -16
正因为我们的应用程序能够使用的内存有限,所以在编写代码的时候需要特别注意内存使用问题。如下是一些常见的内存使用不当的情况。
(一) 查询数据库没有关闭游标
描述:
程序中经常会进行查询数据库的操作,但是经常会有使用完毕Cursor后没有关闭的情况。如果我们的查询结果集比较小,对内存的消耗不容易被发现,只有在常时间大量操作的情况下才会复现内存问题,这样就会给以后的测试和问题排查带来困难和风险。
示例代码:
Cursor cursor = getContentResolver().query(uri ...);
if (cursor.moveToNext()) {
... ...
}
修正示例代码:
Cursor cursor = null;
try {
cursor = getContentResolver().query(uri ...);
if (cursor != null && cursor.moveToNext()) {
... ...
}
} finally {
if (cursor != null) {
try {
cursor.close();
} catch (Exception e) {
//ignore this
}
}
}
(二) 构造Adapter时,没有使用缓存的 convertView
描述:
以构造ListView的BaseAdapter为例,在BaseAdapter中提高了方法:
public View getView(int position, View convertView, ViewGroup parent)
来向ListView提供每一个item所需要的view对象。初始时 ListView会从BaseAdapter中根据当前的屏幕布局实例化一定数量的view对象,同时ListView会将这些view对象缓存起来。当 向上滚动ListView时,原先位于最上面的list item的view对象会被回收,然后被用来构造新出现的最下面的list item。这个构造 过程就是由getView()方法完成的,getView()的第二个形参 View convertView就是被缓存起来的list item的 view对象(初始化时缓存中没有view对象则convertView是null)。
由此可以看出,如果我们不去使用convertView,而是每次都在getView()中重新实例化一个View对象的话,即浪费资源也浪费时间,也会使得内存占用越来越大。ListView回收list item的view对象的过程可以查看:
android.widget.AbsListView.java --> void addScrapView(View scrap) 方法。
示例代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = new Xxx(...);
... ...
return view;
}
修正示例代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
if (convertView != null) {
view = convertView;
populate(view, getItem(position));
...
} else {
view = new Xxx(...);
...
}
return view;
}
(三) Bitmap对象不在使用时调用recycle()释放内存
描述:
有时我们会手工的操作Bitmap对象,如果一个Bitmap对象比较占内存,当它不在被使用的时候,可以调用Bitmap.recycle()方法回收此对象的像素所占用的内存,但这不是必须的,视情况而定。可以看一下代码中的注释:
/**
* Free up the memory associated with this bitmap's pixels, and mark the
* bitmap as "dead", meaning it will throw an exception if getPixels() or
* setPixels() is called, and will draw nothing. This operation cannot be
* reversed, so it should only be called if you are sure there are no
* further uses for the bitmap. This is an advanced call, and normally need
* not be called, since the normal GC process will free up this memory when
* there are no more references to this bitmap.
*/
(四) 释放对象的引用
描述:
这种情况描述起来比较麻烦,举两个例子进行说明。
示例A:
假设有如下操作
public class DemoActivity extends Activity {
... ...
private Handler mHandler = ...
private Object obj;
public void operation() {
obj = initObj();
...
[Mark]
mHandler.post(new Runnable() {
public void run() {
useObj(obj);
}
});
}
}
我们有一个成员变量 obj,在operation()中我们希望能 够将处理obj实例的操作post到某个线程的MessageQueue中。在以上的代码中,即便是mHandler所在的线程使用完了obj所引用的对 象,但这个对象仍然不会被垃圾回收掉,因为DemoActivity.obj还保有这个对象的引用。所以如果在DemoActivity中不再使用这个对 象了,可以在[Mark]的位置释放对象的引用,而代码可以修改为:
... ...
public void operation() {
obj = initObj();
...
final Object o = obj;
obj = null;
mHandler.post(new Runnable() {
public void run() {
useObj(o);
}
}
}
... ...
示例B:
假设我们希望在锁屏界面(LockScreen)中,监听系统中的电 话服务以获取一些信息(如信号强度等),则可以在LockScreen中定义一个PhoneStateListener的对象,同时将它注册到 TelephonyManager服务中。对于LockScreen对象,当需要显示锁屏界面的时候就会创建一个LockScreen对象,而当锁屏界面 消失的时候LockScreen对象就会被释放掉。
但是如果在释放LockScreen对象的时候忘记取消我们之前注册 的PhoneStateListener对象,则会导致LockScreen无法被垃圾回收。如果不断的使锁屏界面显示和消失,则最终会由于大量的 LockScreen对象没有办法被回收而引起OutOfMemory,使得system_process进程挂掉。
总之当一个生命周期较短的对象A,被一个生命周期较长的对象B保有其引用的情况下,在A的生命周期结束时,要在B中清除掉对A的引用。
(五) 其他
Android应用程序中最典型的需要注意释放资源的情况是在 Activity的生命周期中,在onPause()、onStop()、onDestroy()方法中需要适当的释放资源的情况。由于此情况很基础,在 此不详细说明,具体可以查看官方文档对Activity生命周期的介绍,以明确何时应该释放哪些资源