(六)Spark——Spark Streaming
目录
- 一、Spark Streaming 概述
- 1. Spark Streaming是什么
- 2. Spark Streaming特点
- 3. Spark Streaming 架构
- 3.1 背压机制
- 二、DStream 入门
- 1. WordCount 案例
- 2. WordCount 案例解析
- 三、DStream 创建
- 1. RDD 队列
- 2. 自定义数据源
- 3. Kafka 数据源
- 3.1 用法及说明
- 3.2 实现(存在问题的方式)
- 3.3 高级API(从上次的位置继续消费)
- 3.4 低级API
- 四、DStream 转换
- 1. 无状态转换操作
- 1.1 transform操作
- 2. 有状态转换操作
- 2.1 updateStateByKey
- 2.2 window 操作
- 2.2.1 reduceByKeyAndWindow(reduceFunc: (V, V) => V, windowDuration: Duration)
- 2.2.2 reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration)
- 2.2.3 window(windowLength, slideInterval)
- 五、DStream 输出
- 六、DStream 编程进阶
- 1. 累加器和广播变量
- 2. DataFrame ans SQL Operations
- 3. Caching / Persistence
一、Spark Streaming 概述
1. Spark Streaming是什么
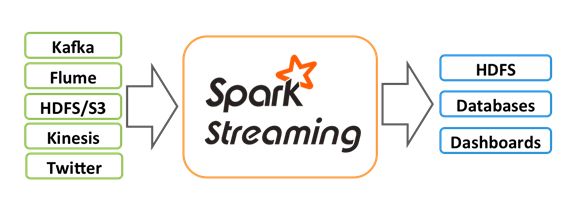
Spark Streaming 是 Spark 核心 API 的扩展, 用于构建弹性, 高吞吐量, 容错的在线数据流的流式处理程序. 总之一句话: Spark Streaming 用于流式数据的处理。
数据可以来源于多种数据源: Kafka, Flume, Kinesis, 或者 TCP 套接字. 接收到的数据可以使用 Spark 的负责元语来处理, 尤其是那些高阶函数像: map, reduce, join, 和window。
最终, 被处理的数据可以发布到 FS, 数据库或者在线dashboards。
另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合.
在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置时间间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
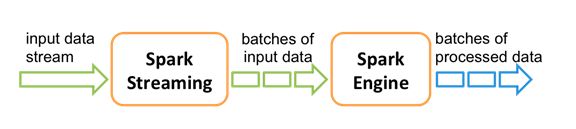
Spark Streaming 提供了一个高级抽象: discretized stream(DStream), DStream 表示一个连续的数据流。
DStream 可以由来自数据源的输入数据流来创建, 也可以通过在其他的 DStream 上应用一些高阶操作来得到。
在内部,一个DSteam 是由一个 RDD 序列来表示的。
2. Spark Streaming特点
-
易用
通过高阶函数来构建应用

-
容错

-
易整合到 Spark 体系中

-
缺点
Spark Streaming 是一种“微量批处理”架构, 和其他基于“一次处理一条记录”架构的系统相比, 它的延迟会相对高一些。
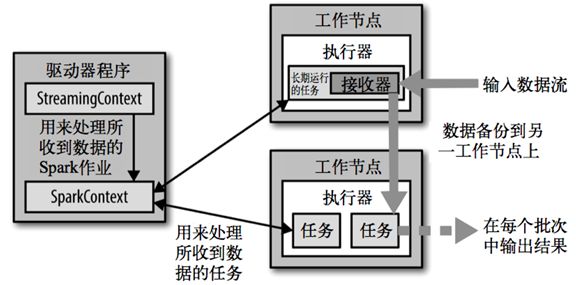
3. Spark Streaming 架构
3.1 背压机制
Spark 1.5以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数 spark.streaming.receiver.maxRate 的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即Spark Streaming Backpressure): 根据 JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
通过属性spark.streaming.backpressure.enabled来控制是否启用backpressure机制,默认值false,即不启用。
二、DStream 入门
1. WordCount 案例
-
需求:
使用 netcat 工具向 9999 端口不断的发送数据,通过 Spark Streaming 读取端口数据并统计不同单词出现的次数。 -
添加依赖:
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.1.1version>
dependency>
- 编写代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount1 {
def main(args: Array[String]): Unit = {
//1. 创建 StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount1")
//第二个参数处理的周期,这里就是设置每3秒处理一次
val ssc = new StreamingContext(conf,Seconds(3))
//2. 核心数据集 :DStreaming ,这里得到的就是一行一行的数据
val socketStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102",9999)
//3. 对DStreaming 做各种操作
val wordCountDStream = socketStream.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
//4. 最终数据的处理:打印,打印100行
wordCountDStream.print(100)
//5. 启动 StreamingContext
ssc.start()
//6. 阻止当前线程退出
ssc.awaitTermination()
}
}
- 测试
(1)在hadoop102 上启动 netcat:
[fseast@hadoop102 ~]$ nc -lk 9999
如果没有安装 netcat 则需安装 ,安装命令为:
[fseast@hadoop102 ~]$ sudo yum install -y nc
(2)运行代码,并在netcat 命令输入窗口输入单词
[fseast@hadoop102 ~]$ nc -lk 9999
hello test test hello dd
test dd
(3)查看输出结果,程序每3秒钟统计一次数据的输入情况。(只统计每3秒之间的数据情况,不包括前面的数据情况,这是无状态转换操作,下面有关于这个的解释)
-------------------------------------------
Time: 1569236436000 ms
-------------------------------------------
(dd,1)
(hello,2)
(test,2)
-------------------------------------------
Time: 1569236439000 ms
-------------------------------------------
-------------------------------------------
Time: 1569236442000 ms
-------------------------------------------
(dd,1)
(test,1)
需要注意的点:
• 一旦StreamingContext已经启动, 则不能再添加添加新的 streaming computations
• 一旦一个StreamingContext已经停止(StreamingContext.stop()), 他也不能再重启
• 在一个 JVM 内, 同一时间只能启动一个StreamingContext
• stop() 的方式停止StreamingContext, 也会把SparkContext停掉. 如果仅仅想停止StreamingContext, 则应该这样: stop(false)
• 一个SparkContext可以重用去创建多个StreamingContext, 前提是以前的StreamingContext已经停掉,并且SparkContext没有被停掉。
2. WordCount 案例解析
Discretized Stream(DStream) 是 Spark Streaming 提供的基本抽象, 表示持续性的数据流, 可以来自输入数据, 也可以是其他的 DStream 转换得到. 在内部, 一个 DSteam 用连续的一系列的 RDD 来表示. 在 DStream 中的每个 RDD 包含一个确定时间段的数据.
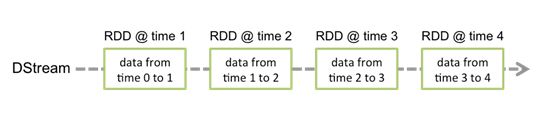
对 DStream 的任何操作都会转换成对他里面的 RDD 的操作. 比如前面的 wordcount 案例, flatMap是应用在 line DStream 的每个 RDD 上, 然后生成了 words SStream 中的 RDD. 如下图所示:
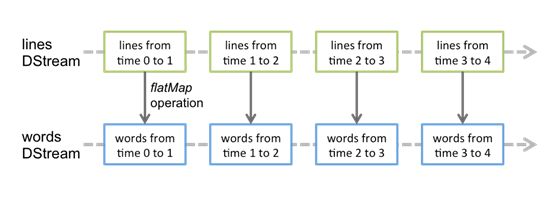
对这些 RDD 的转换是有 Spark 引擎来计算的,DStream 的操作隐藏的大多数的细节, 然后给开发者提供了方便使用的高级 API.
三、DStream 创建
Spark Streaming 原生支持一些不同的数据源。
一些“核心”数据源已经被打包到 Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。
每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。
此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。所以如果在本地模式运行,不要使用 local 或者 local[1]。
1. RDD 队列
上面的WordCount已经使用了一种创建DStream的方式:socketStream: ReceiverInputDStream[String] = ssc.socketTextStream(“hadoop102”,9999)。
用法及说明:
测试过程中,可以通过使用ssc.queueStream(queueOfRDDs)来创建DStream,每一个推送到这个队列中的RDD,都会作为一个DStream处理。
案例实操:
需求:循环创建几个 RDD,将 RDD 放入队列。通过 Spark Streaming创建 Dstream,计算 RDD 内的数据的和。
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object WordCount2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount2").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
//创建一个可变队列
val rddQueue: mutable.Queue[RDD[Int]] = mutable.Queue[RDD[Int]]()
//第二个参数false 的意思是,时间段内也就是这里3秒内处理多个RDD,
val resultDStream = ssc.queueStream(rddQueue,false)
.reduce(_+_)
resultDStream.print()
ssc.start()
//在ssc.start() 和 ssc.awaitTermination() 之间往RDD 放数据
while (true){
rddQueue.enqueue(ssc.sparkContext.parallelize(1 to 100))
Thread.sleep(1000)//睡一秒放一次数据
}
ssc.awaitTermination()
}
}
结果:
-------------------------------------------
Time: 1569238407000 ms
-------------------------------------------
15150
-------------------------------------------
Time: 1569238410000 ms
-------------------------------------------
15150
2. 自定义数据源
使用及说明:
自定义数据源的本质就是自定义接收器。
需要继承Receiver,并实现onStart、onStop方法来自定义数据源采集。
案例实操:
(1)需求:
自定义数据源,实现监控某个端口号,获取该端口号内容。
(2)代码
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object CustomReceiver {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("CustomReceiver")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.receiverStream(new MyReceiver("hadoop102",9999))
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.print(100)
ssc.start()
ssc.awaitTermination()
}
}
/*
自定义数据源的本质就是自定义接收器
*/
class MyReceiver(val host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
/*
* 接受启动的时候调用的方法
* 启动一个子线程,循环不断的去接受数据*/
override def onStart(): Unit = {
new Thread(){
override def run(): Unit = receiveData()
}.start()
}
// 接收器停止的时候回调方法
override def onStop(): Unit = ???
//接受数据的方法
def receiveData(): Unit ={
//从 socket 读数据
try {
val socket = new Socket(host, port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, "utf-8"))
var line = reader.readLine()
while (line != null) {
//
store(line)
line = reader.readLine()
}
reader.close()
socket.close()
} catch {
case e: Exception => e.printStackTrace
} finally {
// 重启任务
restart("重新连接")
}
}
}
开启端口并输入数据:
[fseast@hadoop102 ~]$ nc -lk 9999
aa bb cc aa aa
输出结果:
-------------------------------------------
Time: 1569239592000 ms
-------------------------------------------
(cc,1)
(bb,1)
(aa,3)
3. Kafka 数据源

3.1 用法及说明
在工程中需要引入 Maven 依赖 spark-streaming-kafka_2.11来使用它。
包内提供的 KafkaUtils 对象可以在 StreamingContext和JavaStreamingContext中以你的 Kafka 消息创建出 DStream。
两个核心类:KafkaUtils、KafkaCluster
3.2 实现(存在问题的方式)
导入依赖:
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.1.1version>
dependency>
代码:
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("kafka")
val ssc = new StreamingContext(conf,Seconds(3))
//kafka 参数
//kafka 参数声明
val brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092"
val topic = "first"
val group = "bigdata"
val kafkaParams = Map(
ConsumerConfig.GROUP_ID_CONFIG -> group, //"group.id"
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers
)
//泛型参数1和2:key和value的类型 泛型参数3和4 :key-value的解码器
val sourceDStream:InputDStream[(String,String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc,
kafkaParams,
Set(topic)
)
sourceDStream.print
ssc.start()
ssc.awaitTermination()
}
}
启动Kafka,并生产数据:
要保证Zookeeper是启动状态。
[fseast@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
运行程序后,生产数据:
[fseast@hadoop102 kafka_2.11-0.11.0.2]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>aaa cc aaa kk
>kk cc aaa
结果为:
-------------------------------------------
Time: 1569243786000 ms
-------------------------------------------
(null,aaa cc aaa kk)
-------------------------------------------
Time: 1569243789000 ms
-------------------------------------------
(null,kk cc aaa )
这个程序存在的问题:
如果程序停了或者挂掉了,重新启动程序,在程序挂掉的这段时间,Kafka 所产生的数据,不会被消费到。
3.3 高级API(从上次的位置继续消费)
为了解决上一个代码最后提出所存在的问题。这种方式至少消费一次。
代码:
这种方式读取Kafka数据源最常用:
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount2 {
def main(args: Array[String]): Unit = {
//静态方法getActiveOrCreate可以创建StreamingContext,获取一个曾经记录过的,如果没有则给你创建一个
//第一个参数为存储偏移量的路径,
val ssc:StreamingContext = StreamingContext.getActiveOrCreate("./ck1",createSSc)
ssc.start()
ssc.awaitTermination()
}
def createSSc(): StreamingContext ={
println("aaa")//这行代码只会在第一次执行这个程序的时候打印,即没有产生偏移量文件之前,产生了偏移量文件以后,重新启动这个程序也不会执行这行代码。
val conf = new SparkConf().setMaster("local[*]").setAppName("Kafka")
val ssc = new StreamingContext(conf,Seconds(4))
ssc.checkpoint("./ck1")
//kafka 参数
//kafka 参数声明
val brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092"
val topic = "first"
val group = "bigdata"
val kafkaParams = Map(
ConsumerConfig.GROUP_ID_CONFIG -> group, //"group.id"
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers
)
//泛型参数1和2:key和value的类型 泛型参数3和4 :key-value的解码器
val sourceDStream:InputDStream[(String,String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc, kafkaParams,Set(topic)
)
/* Wordcount,统计单词数量两种方式,可以看无状态转换那一节
//直接使用DStream的函数
val wc = sourceDStream.flatMap(_._2.split(" ")).map((_,1)).reduceByKey(_+_)
//转成rdd的操作方式
val wc2 = sourceDStream.transform(rdd =>rdd.flatMap(_._2.split(" ")).map((_, 1)).reduceByKey(_ + _))
wc.print()//重新添加代码记得把存储偏移量的文件夹./ck1删掉,否则不生效
wc2.print()*/
sourceDStream.print
ssc
}
}
(1)启动程序,然后生产数据:
[fseast@hadoop102 kafka_2.11-0.11.0.2]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>aaa ccc sss
程序显示结果:
可以正常读取。
-------------------------------------------
Time: 1569245128000 ms
-------------------------------------------
(null,aaa ccc sss)
(2)停掉程序,然后生产一批数据:
>ttt kkk ttt kkk
(3)再启动程序,看是否可以读取到程序挂掉期间所产生的数据:
结果:
-------------------------------------------
Time: 1569245392000 ms
-------------------------------------------
(null,ttt kkk ttt kkk)
可以读取到程序挂掉期间所产生的数据。
3.4 低级API
还有一种从读取Kafka数据源的方式,低级API,关于低级API这里就不详细说了。
四、DStream 转换
DStream 上的原语与 RDD 的类似,分为 Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
1. 无状态转换操作
无状态转换操作可以粗浅的理解为:在创建 ssc 时设置的时间段内的进行操作。只在时间间隔内有效,出了时间间隔就没效了。
无状态转化操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。部分无状态转化操作列在了下表中。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。例如,reduceByKey()会化简每个时间区间中的数据,但不会化简不同区间之间的数据。
举个例子,在之前的wordcount程序中,我们只会统计几秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键值对DStream拥有和RDD一样的与连接相关的转化操作,也就是cogroup()、join()、leftOuterJoin() 等。我们可以在DStream上使用这些操作,这样就对每个批次分别执行了对应的RDD操作。
我们还可以像在常规的 Spark 中一样使用 DStream的union() 操作将它和另一个DStream 的内容合并起来,也可以使用StreamingContext.union()来合并多个流。
1.1 transform操作
transform 原语允许 DStream上执行任意的RDD-to-RDD函数。
可以用来执行一些 RDD 操作, 即使这些操作并没有在 SparkStreaming 中暴露出来.
该函数每一批次调度一次。其实也就是对DStream中的RDD应用转换。
实操:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TransformDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TransformDemo").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val socketStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102",9999)
//转成熟悉的rdd进行操作
val resultDSteam = socketStream.transform(rdd=>{
rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
})
resultDSteam.print
ssc.start()
ssc.awaitTermination()
}
}
启动程序,然后启动 netcat 并在窗口输入数据:
[fseast@hadoop102 kafka_2.11-0.11.0.2]$ nc -lk 9999
aa bb cc aa aa cc
程序的结果:
-------------------------------------------
Time: 1569251118000 ms
-------------------------------------------
(aa,3)
(bb,1)
(cc,2)
2. 有状态转换操作
前面的 WordCount 都是计算单个时间间隔内单词的总和,明显这不是我们希望的。我们希望的是计算当前时间间隔加上前面的所有单词的总和。
2.1 updateStateByKey
updateStateByKey 操作允许在使用新信息不断更新状态的同时能够保留他的状态,updateStateByKey 要键值对的才可以使用。
需要做两件事情:
• 定义状态. 状态可以是任意数据类型
• 定义状态更新函数. 指定一个函数, 这个函数负责使用以前的状态和新值来更新状态.
在每个阶段, Spark 都会在所有已经存在的 key 上使用状态更新函数, 而不管是否有新的数据在,源码:
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
拿WordCount作例子进行分析:
如果当前时间范围内的数据的key在之前已经有了,就把之前聚合好的值传过来,如果现在某个数据之前没出现过,则传一个None过来。比如在前面已经算出来(a,5),也就是a这个词已经出现了5次,当前的时间间隔内有(a,1),则把5传过来,然后当前时间间隔还有(b,1),但是b在前面没有出现过,所以传了一个None过来。
WordCount案例:
代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WithStateDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("WithStateDemo")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.checkpoint("./ck2")
// ssc.sparkContext.setCheckpointDir("./ck3")//与上一行代码含义一样
val socketStream = ssc.socketTextStream("hadoop102",9999)
val resultDStream = socketStream.flatMap(_.split(" "))
.map((_,1))
.updateStateByKey[Int]((seq:Seq[Int],opt:Option[Int]) => Some(seq.sum + opt.getOrElse(0)))
resultDStream.print
ssc.start()
ssc.awaitTermination()
}
}
在netcat输入数据:
[fseast@hadoop102 kafka_2.11-0.11.0.2]$ nc -lk 9999
aa cc
aa dd
cc aa bb
程序输出结果为:
-------------------------------------------
Time: 1569256791000 ms
-------------------------------------------
(cc,1)
(aa,1)
-------------------------------------------
Time: 1569256794000 ms
-------------------------------------------
(cc,1)
(aa,2)
(dd,1)
-------------------------------------------
Time: 1569256800000 ms
-------------------------------------------
(cc,2)
(bb,1)
(aa,3)
(dd,1)
2.2 window 操作
Spark Streaming 也提供了窗口计算, 允许执行转换操作作用在一个窗口内的数据.
默认情况下, 计算只对一个时间段内的RDD进行, 有了窗口之后, 可以把计算应用到一个指定的窗口内的所有 RDD 上.
一个窗口可以包含多个时间段. 基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
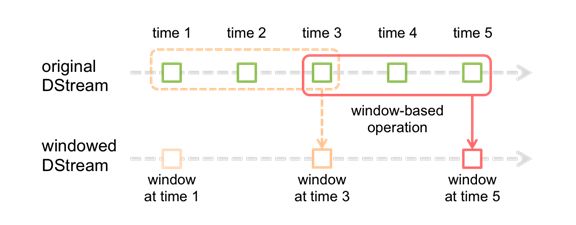
观察上图, 窗口在 DStream 上每滑动一次, 落在窗口内的那些 RDD会结合在一起, 然后在上面操作产生新的 RDD, 组成了 window DStream。
在上面图的情况下, 操作会至少应用在 3 个数据单元上, 每次滑动 2 个时间单位. 所以, 窗口操作需要 2 个参数:
• 窗口长度 – 窗口的持久时间(执行一次持续多少个时间单位)(图中是 3)
• 滑动步长 – 窗口操作被执行的间隔(每多少个时间单位执行一次).(图中是 2 )
注意: 这两个参数必须是源 DStream 的 interval 的倍数.
2.2.1 reduceByKeyAndWindow(reduceFunc: (V, V) => V, windowDuration: Duration)
参数1: reduce 计算规则
参数2: 窗口长度
参数3: 窗口滑动步长. 每隔这么长时间计算一次.(如果不传的话默认使用设置的时间间隔做滑动步长)
实操:
(1)需求:
统计9秒内(窗口长度)的WordCount,每3秒滑动一次(滑动步长)
代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
//测试reduceByKeyAndWindow函数的使用
/*统计9秒内(窗口长度)的WordCount,每3秒滑动一次(滑动步长)*/
object Window1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Window1").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(3))
val sourcDStream = ssc.socketTextStream("hadoop102",9999)
sourcDStream.flatMap(_.split(" "))
.map((_,1))
.reduceByKeyAndWindow(_+_,Seconds(9))//窗口长度设置为9,使用默认的滑动步长是上面的Seconds(3)
.print(10)
ssc.start()
ssc.awaitTermination()
}
}
结果:
启动程序,然后在nc窗口输入数据:
[fseast@hadoop102 ~]$ nc -lk 9999
aa bb aa
程序的结果为:
-------------------------------------------
Time: 1569287346000 ms
-------------------------------------------
(bb,1)
(aa,2)
-------------------------------------------
Time: 1569287349000 ms
-------------------------------------------
(bb,1)
(aa,2)
-------------------------------------------
Time: 1569287352000 ms
-------------------------------------------
(bb,1)
(aa,2)
-------------------------------------------
Time: 1569287355000 ms
-------------------------------------------
如果不想使用默认时间间隔作为窗口滑动步长,可再加如一个参数:
把代码:
sourcDStream.flatMap(_.split(" "))
.map((_,1))
.reduceByKeyAndWindow(_+_,Seconds(9))//窗口长度设置为9,使用默认的滑动步长是上面的Seconds(3)
.print(10)
改成:
sourcDStream.flatMap(_.split(" "))
.map((_,1))
.reduceByKeyAndWindow((_:Int)+(_:Int),Seconds(9),Seconds(6))//自定义步长为6
.print(10)
即可。
2.2.2 reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration)
参数 windowDuration 是窗口长度。参数 slideDuration 是窗口滑动步长。
比没有invReduceFunc高效. 会利用旧值来进行计算.
invReduceFunc: (V, V) => V 窗口移动了, 上一个窗口和新的窗口会有重叠部分, 重叠部分的值可以不用重复计算了, 第一个参数就是新的值, 第二个参数是旧的值。所以如果窗口滑动步长大于等于窗口长度的时候,就没必要优化了。
案例实操:
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Window2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount2")
val ssc = new StreamingContext(conf, Seconds(4))
ssc.checkpoint("./ck4")
val spark = SparkSession.builder().getOrCreate()
val sourceDSteram = ssc.socketTextStream("hadoop102", 9999)
sourceDSteram.flatMap(_.split(" "))
.map((_, 1))
//参数2就是invReduceFunc函数
.reduceByKeyAndWindow(_ + _, _ - _, Seconds(12), Seconds(4))
.print
ssc.start()
ssc.awaitTermination()
}
}
在 nc 窗口输入数据:
[fseast@hadoop102 ~]$ nc -lk 9999
cc aa cc
结果显示:
-------------------------------------------
Time: 1569299656000 ms
-------------------------------------------
(cc,2)
(aa,1)
-------------------------------------------
Time: 1569299660000 ms
-------------------------------------------
(cc,2)
(aa,1)
-------------------------------------------
Time: 1569299664000 ms
-------------------------------------------
(cc,2)
(aa,1)
-------------------------------------------
Time: 1569299668000 ms
-------------------------------------------
(cc,0)
(aa,0)
虽然提高了效率,但由结果可以看到,也可以看到过了计算时间间隔后,还会把对应单词的个数为0返回。我们是不希望看到这种情况的。
可以再加一个参数过滤:
把代码:
.reduceByKeyAndWindow(_ + _, _ - _, Seconds(12), Seconds(4))
改成:
.reduceByKeyAndWindow(_ + _, _ - _, Seconds(12), Seconds(4), filterFunc = _._2 > 0)
即可,再次执行发现最后0的值就被过滤掉了。
2.2.3 window(windowLength, slideInterval)
基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream。返回的DStream之后做的操作都是按照你所设置的窗化进行处理。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Window3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Window3")
val ssc = new StreamingContext(conf,Seconds(4))
//window参数一是窗口长度,参数二是窗口滑动步长。
val sourceDStream = ssc.socketTextStream("hadoop102",9999).window(Seconds(12),Seconds(8))
sourceDStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print
ssc.start()
ssc.awaitTermination()
}
}
结果就不说了,和前面没啥变化,使用了window函数使用上就稍微方便了点。
五、DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。
与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
比较常用的算子:
foreachRDD(func):
The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs.
foreachRDD使用案例:
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object ForeachRDDDStream {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("ForeachRDDDStream").setMaster("local[*]")
val ssc: StreamingContext = new StreamingContext(conf,Seconds(4))
val sourceDStream = ssc.socketTextStream("hadoop102",9999).window(Seconds(12),Seconds(8))
sourceDStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
.foreachRDD(rdd => {
rdd.foreachPartition(it => {
//连接
it.foreach(x =>{
})
//关闭连接
})
})
}
}
注意:
(1)连接不能写在driver层面(序列化);
(2)如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
(3)增加foreachPartition,在分区创建(获取)。
六、DStream 编程进阶
1. 累加器和广播变量
和RDD中的累加器和广播变量的用法完全一样. RDD中怎么用, 这里就怎么用.
2. DataFrame ans SQL Operations
可以很容易地在流数据上使用 DataFrames 和SQL。你必须使用SparkContext来创建StreamingContext要用的SQLContext。
此外,这一过程可以在驱动失效后重启。我们通过创建一个实例化的SQLContext单实例来实现这个工作。如下例所示。我们对前例word count进行修改从而使用DataFrames和 SQL 来产生 word counts 。每个 RDD 被转换为 DataFrame,以临时表格配置并用 SQL 进行查询。
val spark = SparkSession.builder.config(conf).getOrCreate()
import spark.implicits._
count.foreachRDD(rdd =>{
val df: DataFrame = rdd.toDF("word", "count")
df.createOrReplaceTempView("words")
spark.sql("select * from words").show
})
3. Caching / Persistence
和 RDDs 类似,DStreams 同样允许开发者将流数据保存在内存中。也就是说,在DStream 上使用 persist()方法将会自动把DStreams中的每个RDD保存在内存中。
当DStream中的数据要被多次计算时,这个非常有用(如在同样数据上的多次操作)。对于像reduceByWindow和reduceByKeyAndWindow以及基于状态的(updateStateByKey)这种操作,保存是隐含默认的。
因此,即使开发者没有调用persist(),由基于窗操作产生的DStreams会自动保存在内存中。