pig数据结构、读写操作、诊断操作、内建函数
1、Pig的数据结构:
Relations、Bags、Tuples、Fields
关系可以定义如下:
一个关系就是一个Bag,Bag是Tuple元组的集合。Tuple是Field的一个有序集。Field是一块Data。
Pig关系类似于关系数据中的表。Tuple相当于关系数据库中的行。与关系数据库的表不同的是Pig关系不需要每个tuple包含相同的属性个数或者相同位置的属性列要有相同的类型。
pig关系是无序的,也就是不能保证tuples处理过程的顺序。此外,Tuples的处理过程不按照任何顺序也可能是并行的。
2、实例分析:
关系和属性
A = load ‘student’ using PigStorage() as(name:chararray,age:int,gpa:int);
dump A;
(ammy,18,4.0F)
(sunny,19,4.7F)下表就是一个关系,这个关系中含有三个属性

3、引用复杂类型的属性
tuple中的field可以是任意的数据类型,包括bags、tuples、maps。如果field中包含bags、tuples、maps就是复杂类型。
在如下例子关系A中field包含tuple
cat data;
(3,8,9) (4,5,6)
(1,4,7) (3,7,5)
(2,5,8) (9,5,8)
A = LOAD 'data' AS (t1:tuple(t1a:int, t1b:int,t1c:int),t2:tuple(t2a:int,t2b:int,t2c:int));
DUMP A;
((3,8,9),(4,5,6))
((1,4,7),(3,7,5))
((2,5,8),(9,5,8))
X = FOREACH A GENERATE t1.t1a,t2.$0;
DUMP X;
(3,4)
(1,3)
(2,9)

4、Tuple元组
tuple是属性(Field)的有序集。
语法:( field [, field …] )
5、Bag
tuple的集合
语法:{ tuple [, tuple …] }
Outer Bag&Inner Bag
Outer Bag例子如下:
A = LOAD 'data' as (f1:int, f2:int, f3;int);
DUMP A;
(1,2,3)
(4,2,1)
(8,3,4)
(4,3,3)Inner Bag例子如下:
The tuples in relation X have two fields. The first field is type int. The second field is type bag; you can think of this bag as an inner bag.
X = GROUP A BY f1;
DUMP X;
(1,{(1,2,3)})
(4,{(4,2,1),(4,3,3)})
(8,{(8,3,4)})Inner Bag和Outer Bag的区别:Inner Bag中含有包。Outer Bag中不含有包。
6、Map
Map是键值对的集合
语法:[ key#value <, key#value …> ]
注意:key值的类型必须是chararray,在关系中key值必须是唯一的。
7、解引用操作符:
tuple、bag、map的解引用。
tuple和bag可以针对名称和地址,例如:tuple.field_name,mytuple.$0,tuple.(name1,name2),tuple.($0,$1)。tbag.field_name,mybag.$0,bag.(name1,name2),bag.($0,$1)。
8、Pig Latin数据读写操作

9、诊断操作

10、内建函数
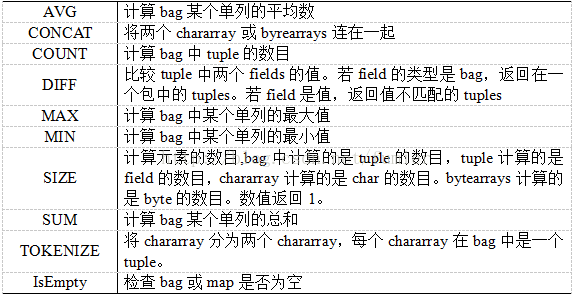
参考资料:1、pig.apache.org/docs/r0.8.1/piglatin_ref2.html
2、http://www.cnblogs.com/xuqiang/archive/2011/06/06/2073601.html