Oozie教程(1)——实现你自己的Hadoop/Spark作业工作流
前言
Oozie是什么呢?按官方说法:Oozie是一个基于工作流引擎的服务器,其中每个工作流的任务可以是Hadoop的Map/Reduce作业或者Pig作业等。Oozie是运行于Java servlet容器上的一个java web应用。Oozie的目的是按照DAG(有向无环图)调度一系列的Map/Reduce或者Pig任务。Oozie 工作流由hPDL(Hadoop Process Definition Language)定义(这是一种XML流程定义语言)。
可以看出,实际上,Oozie的作用类似于:当你有一系列Map/Reduce作业,但是它们之间彼此是相互依赖的关系。(即后一个任务依赖于前面任务的输出)。正常的思路是写shell脚本来完成这些事情,但是,当任务多了,依赖关系复杂的时候,写脚本是费时费力的,而且复用性也差。所以,Oozie出现了!
简介
Oozie workflows 由控制流节点(control flow nodes)和操作节点(action nodes)组成。控制流节点除了定义一个工作流何时开始和何时结束(start,end,fail等),还提供了控制工作流执行路径的机制(decision,fork,join等)。而操作节点是指能够触发一个计算任务(Computation Task)或者处理任务(Processing Task)执行的节点。Oozie提供了包括map-reduce、ssh、file system等在内的很多操作的支持。此外,如有需要,还可以自行扩展操作节点类型。
此外,Oozie工作流中,参数指定也是非常重要的。当有很多输出目录的时候,可以让一定的工作流并发执行。
工作流生命周期
在Oozie中,工作流的状态可能存在如下几种:

上述各种状态存在相应的转移(工作流程因为某些事件,可能从一个状态跳转到另一个状态),其中合法的状态转移有如下几种,如下表所示:
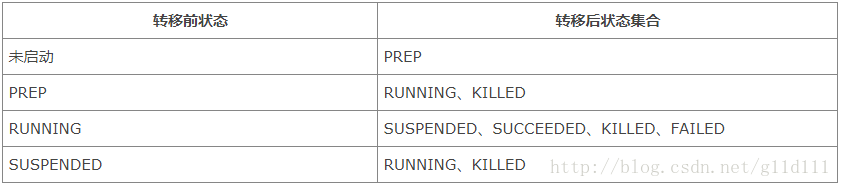
当明确上述给出的状态转移空间以后,可以根据实际需要更加灵活地来控制工作流Job的运行。
控制流节点(Control flow nodes)
下面workflow有时会缩写为wf。特此声明
控制流控制工作流的开始和结束,以及工作流Job的执行路径的节点,它定义了流程的开始(start节点)和结束(end节点或kill节点),同时提供了一种控制流程执行路径的机制(decision决策节点、fork分支节点、join会签节点)。通过上面提到的各种节点,我们大概应该能够知道它们在工作流中起着怎样的作用。下面,我们看一下不同节点的语法格式:
- start节点
"[WF-DEF-NAME]" xlmns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]" />
...
上面start元素中的to指向第一个将要执行的工作流节点。
- end节点
"[WF-DEF-NAME]" xlmns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]" />
...
达到该节点,工作流Job会变成SUCCEEDED状态,表示成功完成。需要注意的是,一个工作流定义必须只能有一个end节点。当一个workflow执行到end node时,即代表这个wf已经成功执行完成,如果有多个actions,其中一个到达了end node,则会kill掉其他actions,此时wf也被认为是成功执行完成。
- kill节点
"[WF-DEF-NAME]" xlmns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]" />
[MESSAGE-TO-LOG]
...
kill元素的name属性,是要杀死的工作流节点的名称,message元素指定了工作流节点被杀死的备注信息。达到该节点,工作流Job会变成状态KILLED。
- decision节点
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]">
<switch>
"[NODE_NAME]">[PREDICATE]
...
"[NODE_NAME]">[PREDICATE]
"[NODE_NAME]"/>
switch>
...
decision节点通过预定义一组条件,当工作流Job执行到该节点时,会根据其中的条件进行判断选择,满足条件的路径将被执行。decision节点通过switch…case语法来进行路径选择,只要有满足条件的判断,就会执行对应的路径,如果没有可以配置default元素指向的节点。
- fork节点和join节点(重要)
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
"[FORK-NODE-NAME]">
"[NODE-NAME_1]" />
...
"[NODE-NAME_N]" />
...
"[JOIN-NODE-NAME]" to="[NODE-NAME]" />
...
fork和join必须一起使用。fork元素下面会有多个path元素,指定了可以并发执行的多个执行路径。fork中多个并发执行路径会在join节点的位置会合:只有所有的路径都到达后,才会继续执行join节点to属性指向的节点。
也就是说,从NODE-NAME_1 直到 NODE-NAME_N ,如果执行成功后,ok元素应该指向一个相同的join作业。以下面为例:
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<fork name="forking">
<path start="firstparalleljob"/>
<path start="secondparalleljob"/>
fork>
<action name="firstparallejob">
<map-reduce>
<job-tracker>foo:8021job-tracker>
<name-node>bar:8020name-node>
<job-xml>job1.xmljob-xml>
map-reduce>
<ok to="joining"/>
<error to="kill"/>
action>
<action name="secondparalleljob">
<map-reduce>
<job-tracker>foo:8021job-tracker>
<name-node>bar:8020name-node>
<job-xml>job2.xmljob-xml>
map-reduce>
<ok to="joining"/>
<error to="kill"/>
action>
<join name="joining" to="nextaction"/>
...
workflow-app>oozie 在提交前会检查fork是否有效或者是否引导一个正确的行为执行,如果校验不通过,则不会提交任务。
但是如果你确定你定义的fork join行为是对的,可以通过设置job.properties文件中的 oozie.wf.validate.ForkJoin 为 false(只影响自己)或者oozie-site.xml文件中的oozie.validate.ForkJoin 为 false(全局的,影响所有wf) 来关闭fork join检查
fork join检查会判断这两个文件的配置,仅当都为true时才会开启检查,其中一个为false,都会关闭检查。
操作节点(Action nodes)
操作节点如简介中介绍,这里展示一下操作节点中的基本特性:
远程执行
对Oozie来说,操作节点的执行都是远程的,因为Oozie可能部署在一个单独的服务器上,而工作流Job是在Hadoop集群的节点上执行的。即使Oozie在Hadoop集群的某个节点上,它也是处于与Hadoop进行独立无关的JVM示例之中(Oozie部署在Servlet容器当中)。异步性
操作节点的执行,对于Oozie来说是异步的。Oozie启动一个工作流Job,这个工作流Job便开始执行。Oozie可以通过两种方式来探测工作流Job的执行情况:一种是基于回调机制(call backs),对每个任务的执行(可以看成是操作节点的执行)都设置一个唯一的URL,如果任务执行结束或者执行失败,会通过回调这个URL通知Oozie已经完成;另一种就是轮询(polling),Oozie不停地去查询任务执行的完成状态。如果由于网络故障回调机制失败,也会使用轮询的方式去获取任务的状态。
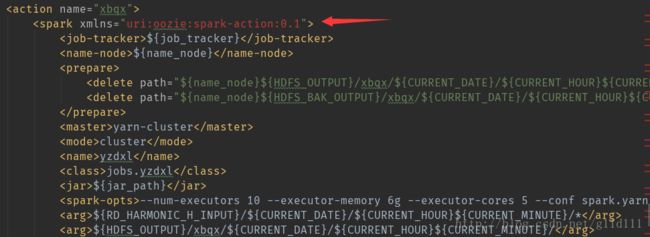
ps:上图红色箭头指向的就是一个操作节点的url执行结果要么成功,要么失败
如果操作节点执行成功,则会转向ok节点;如果失败则会转向error节点。

可恢复性
如果一个动作节点执行失败,Oozie提供了一些恢复执行的策略,这个要根据失败的特点来进行:如果是状态转移过程中失败,Oozie会根据指定的重试时间间隔去重新执行;如果不是转移性质的失败,则只能通过手工干预来进行恢复;如果重试恢复执行都没有解决问题,则最终会跳转到error节点。
当成功执行时会执行ok定义的to name,失败时执行error定义的to name,当为error时,必须提供 error-code and error-message 信息给 Oozie。可以通过使用decision node对error-code进行switch-case从而实现不同错误代码不同的处理逻辑。
下面以几个典型Oozie内置支持的动作节点类型为例,详细介绍:
- Map-Reduce动作
map-reduce动作会在工作流Job中启动一个MapReduce Job任务运行,我们可以详细配置这个MapReduce Job。另外,可以通过map-reduce元素的子元素来配置一些其他的任务,如streaming、pipes、file、archive等等。
下面给出包含这些内容的语法格式说明:
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]">
[JOB-TRACKER]
[NAME-NODE]
"[PATH]"/>
...
"[PATH]"/>
...
[MAPPER-PROCESS]
[REDUCER-PROCESS]
[RECORD-READER-CLASS]
[NAME=VALUE]
...
[NAME=VALUE]
...
[REDUCER]
[INPUTFORMAT]
[PARTITIONER]
[OUTPUTFORMAT]
[EXECUTABLE]
[JOB-XML-FILE]
[PROPERTY-NAME]
[PROPERTY-VALUE]
...
[FILE-PATH]
...
[FILE-PATH]
...
"[NODE-NAME]"/>
"[NODE-NAME]"/>
...
- Hive动作
Hive主要是基于类似SQL的HQL语言的,它能够方便地操作HDFS中数据,实现对海量数据的分析工作。Hive动作的语法格式如下所示:
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.2">
...
"[NODE-NAME]">
"uri:oozie:hive-action:0.2">
[JOB-TRACKER]
[NAME-NODE]
"[PATH]" />
...
"[PATH]" />
...
[PROPERTY-NAME]
[PROPERTY-VALUE]
...
[PARAM-VALUE]
...
"[NODE-NAME]" />
"[NODE-NAME]" />
...
- Fs动作
Fs动作主要是基于HDFS的一些基本操作,如删除路径、创建路径、移动文件、设置文件权限等等。
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
"[NODE-NAME]">
'[PATH]' />
...
'[PATH]' />
...
source='[SOURCE-PATH]' target='[TARGET-PATH]' />
...
'[PATH]' permissions='[PERMISSIONS]' dir-files='false' />
...
'[PATH]' />
"[NODE-NAME]" />
"[NODE-NAME]" />
...
- 支持的hadoop fs命令有
-
move , delete , mkdir , chmod , touchz and chgrp。
FS命令是 串行执行的,即上一个命令执行完之后才会往下执行下一个命令。
FS命令 不会自动回滚的,即 当前命令失败之后,前面对HDFS的成功操作命令并不会撤销。因此一般使用时都会定义一个单独action来检查下面的FS ACTION将做的操作的source或者target文件是否有效等等。然后再进行FS ACTION定义的操作,避免中途失败造成的风险。
delete指定path如果是一个目录的话,会递归的删除子目录然后再删除该目录,类似hadoop fs -rm -r
mkdir会创建所有missing的目录,类似于hadoop fs -mkdir -p
move 的source-path必须存在,The file system URI(e.g. hdfs://{nameNode}) 在target path中可以被跳过,默认和source 的system URI一样,但是也可以指定target自己的 system URI. target path的父目录必须存在,如果target path已经存在的话,source path将作为target path 这个目录的子目录移动过去。
touchz 当path不存在时创建一个空文件(zero length file),如果存在的话,执行的是touch操作,即修改文件的时间戳。
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.5">
...
<action name="hdfscommands">
<fs>
<delete path='hdfs://foo:8020/usr/tucu/temp-data'/>
<mkdir path='archives/${wf:id()}'/>
<move source='${jobInput}' target='archives/${wf:id()}/processed-input'/>
<chmod path='${jobOutput}' permissions='-rwxrw-rw-' dir-files='true'><recursive/>chmod>
<chgrp path='${jobOutput}' group='testgroup' dir-files='true'><recursive/>chgrp>
fs>
<ok to="myotherjob"/>
<error to="errorcleanup"/>
action>
...
workflow-app>- Spark动作
工作流作业直到当前的Spark作业完成后才会继续调度执行下面的内容;用户需要自己定义job-tracker和name-node信息。语法格式:
"[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.3">
...
"[NODE-NAME]">
"uri:oozie:spark-action:0.1">
[JOB-TRACKER]
[NAME-NODE]
"[PATH]"/>
...
"[PATH]"/>
...
[SPARK SETTINGS FILE]
[PROPERTY-NAME]
[PROPERTY-VALUE]
...
[SPARK MASTER URL]
[SPARK MODE]
[SPARK JOB NAME]
[SPARK MAIN CLASS]
[SPARK DEPENDENCIES JAR / PYTHON FILE]
[SPARK-OPTIONS]
[ARG-VALUE]
...
[ARG-VALUE]
...
"[NODE-NAME]"/>
"[NODE-NAME]"/>
...
以一个作业为例,一步步来分析:

prepare:(可选)如果出现,表明在启动作业之前,需要创建/删除一系列路径。特定的路径必须带有: hdfs://HOST:PORT .
job-xml:(可选)如果出现,即为spark作业指定配置文件
:(可选)如果出现,将其中设置的配置属性传递给spark作业。
master:(必须)即为spark作业指定调度器:yarn-master yarn-cluster mesos local等
Ex: spark://host:port, mesos://host:port, yarn-cluster, yarn-master, or local.
mode:(可选)即为spark作业指定driver运行位置。client或者cluster。这个其实没啥卵用,因为在master中,你可以指定: master=yarn-client is equivalent to master=yarn, mode=client从而无需设置mode
此外,一个本地的master总是以client模式运行。
基于不同的master和mode,Spark作业运行情况如下:
● local mode: everything runs here in the Launcher Job.
● yarn-client mode: the driver runs here in the Launcher Job and the executor in Yarn.
● yarn-cluster mode: the driver and executor run in Yarn.
name:(必须)spark作业的名称
class:(可选)入口类(main class)。对python作业不需要指定
jar:(必须)一系列jar包或者python文件。
spark-opts:(可选)提交spark作业的时候,设置executors等参数
arg:(可选)如果提供,则将其传递给spark application
PySpark with Spark Action
为了提交pyspark脚本,pyspark依赖必须设置好,详情请看这个官方文档
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
....
<action name="myfirstpysparkjob">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>foo:8021job-tracker>
<name-node>bar:8020name-node>
<prepare>
<delete path="${jobOutput}"/>
prepare>
<configuration>
<property>
<name>mapred.compress.map.outputname>
<value>truevalue>
property>
configuration>
<master>yarn-clustermaster>
<name>Spark Examplename>
<jar>pi.pyjar>
<spark-opts>--executor-memory 20G --num-executors 50
--conf spark.executor.extraJavaOptions="-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp"spark-opts>
<arg>100arg>
spark>
<ok to="myotherjob"/>
<error to="errorcleanup"/>
action>
...
workflow-app>注意:上面的例子中,pi.py必须是spark的本地文件!这个python文件应该放在靠近workflow.xml的lib/目录下或者将文件前面加上详细的地址。
表达式语言函数(Expression Language Functions)
Oozie除了可以使用Properties文件定义一些属性之外,还提供了一些内置的EL函数,能够方便地实现流程的定义和控制,下面我们分组列表说明:
①基本的EL常量

②基本的EL函数

③工作流EL函数
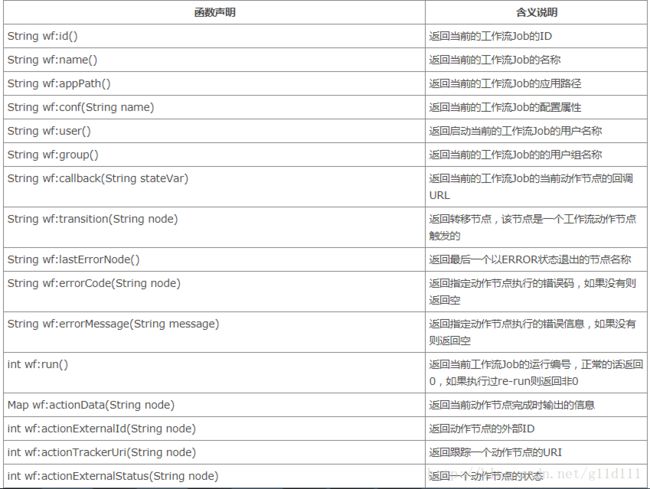
下面是一个在实际工程中使用的例子:

④HDFS EL函数

下面以使用decision node和HDFS EL函数的工作流作为例子:
"foo-wf" xmlns="uri:oozie:workflow:0.1">
...
"mydecision">
<switch>
"reconsolidatejob">
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
"rexpandjob">
${fs:filSize(secondjobOutputDir) lt 100 * MB}
"recomputejob">
${ hadoop:counters('secondjob')[RECORDS][REDUCE_OUT] lt 1000000 }
"end"/>
switch>
...
参考资料
1、官方文档
2、Oozie工作流程定义详解