主要记录在Hadoop集群下搭建TensorFlowOnSpark平台后,在YARN模式下以feed_dic方式运行mnist时遇到的问题。
我的版本如下:
Hadoop 2.7
Spark 2.3.1
Python 3.6.3
Tensorflow 1.5
遇到的问题如下:
(1)将文件转为csv格式时,就出现错误,错误位置为 sc=SparkContext(conf=SparkConf().setAppName("mnisit_parallelize")),截图是:
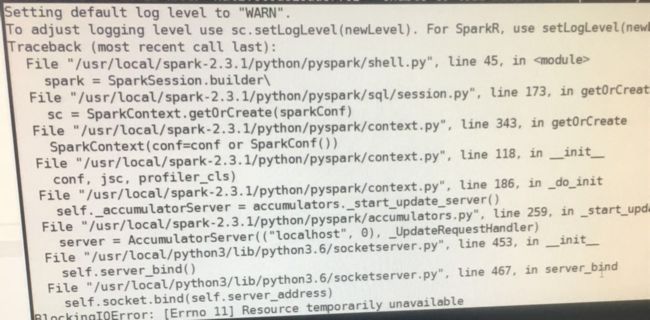
解决方法:这里出现错误的原因是socket通信时地址不可用,后来发现我在配置集群时,把/etc/host 中的localhost改为 master了,在/etc/host中,添上 IP localhost就可以了。
(2)同样是在转csv格式时出现错误,我的提交语句是:
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 4g \
--archives hdfs:///user/${USER}/Python.zip#Python, hdfs:///user/${USER}/mnist.zip#mnist \
TensorFlowOnSpark/examples/mnist/mnist_data_setup.py \
--output mnist/csv \
--formant csv
报的错误如下:
ImportError: Importing the multiarray numpy extension module failed.
解决方法:
这里出现错误原因是 将 Python环境打包传到Yarn集群上后,python代码依赖第三方模块numpy,然后找不到numpy报出的错误。这里解决方法参考了以下两个文章:
[1]https://www.jianshu.com/p/df0a189ff28b
[2]https://www.cloudera.com/documentation/enterprise/5-5-x/topics/cdh_ig_running_spark_on_yarn.html
我在上述提交语句的 --archives后面一行,添加了以下两行语句:
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=Python/bin/python3
--conf spark.yarn.executorEnv.PYSPARK_PYTHON=Python/bin/python3
(Tips:这里的Python就是指 提交语句 --archives中“hdfs:///user/${USER}/Python.zip#Python”指定的工作目录 Python)
如果添加了这两个语句仍旧起不到作用的话,我在查阅资料时,有两种方法:
1.重新安装合适版本的numpy,重新给Python打包上传到hdfs
2.节点不多的话,检查每个节点是否都可以 import numpy
(3)依旧是在转换csv格式时出现的错误,一直报 “mnist/train-images-idx3-ubyte.gz”找不到文件。这个问题纯粹是我自己的原因造成的。
解决方法: “mnist/train-images-idx3-ubyte.gz”中的mnist同样指的是 --archives中“hdfs:///user/${USER}/mnist.zip#mnist”,也就是说 mnist.zip里需直接包含“train-images-idx3-ubyte.gz”。
我当时不是从官网下载的 mnist.zip,我的mnist.zip里是 一个mnist文件夹,在mnist文件夹下才包含“train-images-idx3-ubyte.gz”。
因此,我把 writeMNIST函数里的路径“mnist/train-images-idx3-ubyte.gz”改为“mnist/mnist/train-images-idx3-ubyte.gz”,后面3个路径以此类推,最终解决问题。
小白一枚~以上我遇到的问题皆是配置、路径的问题,虽然错误很简单但也耽误了一段时间。因为集群不能连外网,图片拍的也不是很清楚,非常抱歉。
记一下我的教训:各种语句不能直接照着安装指南敲进去,一定要弄清楚意思再动手!