雕虫小技也重要--数据处理中的电子表格技巧
在数据处理过程中,常遇到一些很棘手的问题。如需要一次性的导入一批非格式化的数据、临时统计、筛选一些参数等工作,如果不写代码,觉得难以实现;写代码,又感到不值得。从多年的职场经验来看,这种鸡肋工作往往还是影响效率的关键点,一个人能力强不强,往往体现在能否灵活、高效地应对这些麻烦。下面,就以几个实例,讲一讲目前公司中盛行的一些“雕虫小技”。
1 向数据库快速导入临时数据
应用场景:新增了一批券信息,但是上游提供的数据格式并不满足既有自动导入程序的规范;BOSS要求下班前要看到结果。
笨人办法:写程序、手工填写录入
讨巧办法:利用wps 表格批量生成insert脚本
1.1 数据样式
数据中包含如下几列:
| 券号 | 公司名称 | 生效日期 |
|---|---|---|
| 10238434 | 志强化工 | 2016.12.22 |
| 10238435 | 金岸抗压罐 | 2016.12.23 |
| 10238436 | 志强化工 | 2016.11.24 |
| 10238437 | 华芳稀有气体 | 2016.11.25 |
| 10238438 | 志强化工 | 2016.09.12 |
| 10238439 | 三环制气 | 2016.12.27 |
我们数据中,券号是一致的,但是公司名称并不作为关联存储,转而为公司的ID。此外,生效日期也不符合数据库的日期格式。
1.2 自动关联公司ID与公司名称
第一步,是把公司名称换为ID。我们从现有数据库中拷贝出公司静态信息表的名称、ID,名称在前、ID在后。
select comp_name, comp_id from tb_comp_2017;| comp_name | comp_id |
|---|---|
| 志强化工 | 302838 |
| 金岸抗压罐 | 384475 |
| 华芳稀有气体 | 100192 |
| 三环制气 | 187364 |
| 安途特运 | 448537 |
在原始表格“公司名称”后面插入一列,并把上述结果粘贴到本电子表格的尾部,如下图所示。

而后,我们利用VLOOKUP函数自动为B列关联公司ID到C列。
VLOOKUP有四个参数:
(1)来源单元格,即被查找的对象(公司名称)
(2)字典范围,即P、Q列
(3)取值列,即查找结果,为P、Q的第二列
(4)匹配开关,FALSE为精确匹配,TRUE为模糊匹配
在C2单元格输入公式:
=VLOOKUP(B2,P:Q,2,FALSE)回车后发现已经匹配完毕:

使用拖拽C2复选框右下角小黑点的方法,可以迅速填满全列:

1.3 纠正日期格式
日期格式数据库可接受以”-“分隔,因此,直接进行替换:
=SUBSTITUTE(D2,".","-")1.4 生成SQL
我们采用字符串拼接函数来组装生成SQL
=CONCATENATE(A2,",",C2,",'",E2,"');")效果如下:
![]()
同样,选中两个单元格G2,H2,下拉选中框右下角的黑点,得到所有语句:
| G2 | H2 |
|---|---|
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238434,302838,’2016-12-22’); |
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238435,384475,’2016-12-23’); |
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238436,302838,’2016-11-24’); |
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238437,100192,’2016-11-25’); |
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238438,302838,’2016-09-12’); |
| insert into bill_table ( bill_id, comp_id, vdate ) values ( | 10238439,187364,’2016-12-27’); |
把该语句复制到SQL管理器直接运行,即可插入所有数据。
2 批量规整文件
来自传感器的原始数据文件被扔在一个单一的文件夹下,文件名的命名如下:
temperature_年月日时分秒_传感器ID.dat,如
temperature_20150413154322_F1B273E0C5.dat
问题是,在同一个文件夹下存放了近20万个零碎小文件,BOSS要求,按照传感器建立一级文件夹,日期建立二级文件夹,重新规整所有文件。
由于该需求不是经常发生,可以说,是“一锤子”买卖,因此,为这样的需求动用编程似乎有点不值得。我们还是请出电子表格来解决。
2.1 枚举文件名
借助windows控制台,可以方便的获取文件名:
D:\Data\2017>dir /b *.dat> all.txt用文本编辑器打开该文件,可以看到文件名:
temperature_20150103011816_57F012FA05BA3B97.dat
temperature_20150103014804_547E7DD139696DE7.dat
temperature_20150103084317_2714341909C94ABF.dat
temperature_20150104065907_0193123B757C1664.dat
temperature_20150106091127_4AE0074A458A6D32.dat
temperature_20150106213531_77E51FD259803C6D.dat
temperature_20150107160039_6A7F22120E576FA1.dat
temperature_20150107181009_49575A1F1FA40F3E.dat
temperature_20150108060447_5F8765A566A94390.dat
temperature_20150108164202_1F196C34657D1A44.dat把所有文件名粘贴到电子表格,在1、2列各粘贴一次。
2.2 分列获取元素
使用分列功能,按照分隔符号或者宽度,将文件名分为5列
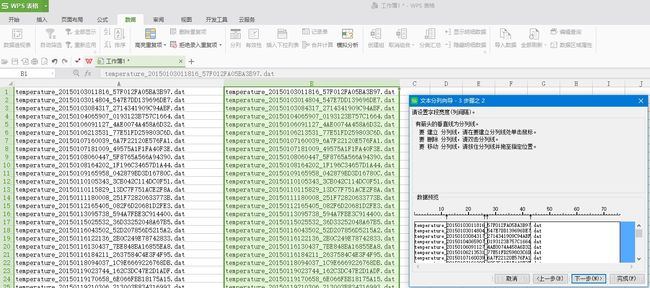
内容类似:
| A | B | C | D | E | F |
|---|---|---|---|---|---|
| temperature_2015….dat | temperature_ | 20150103014804 | _ | 547E7DD139696DE7 | .dat |
| temperature_2015….dat | temperature_ | 20150103084317 | _ | 2714341909C94ABF | .dat |
| temperature_2015….dat | temperature_ | 20150104065907 | _ | 0193123B757C1664 | .dat |
| temperature_2015….dat | temperature_ | 20150106091127 | _ | 4AE0074A458A6D32 | .dat |
| temperature_2015….dat | temperature_ | 20150106213531 | _ | 77E51FD259803C6D | .dat |
| temperature_2015….dat | temperature_ | 20150107160039 | _ | 6A7F22120E576FA1 | .dat |
2.3 产生批处理命令
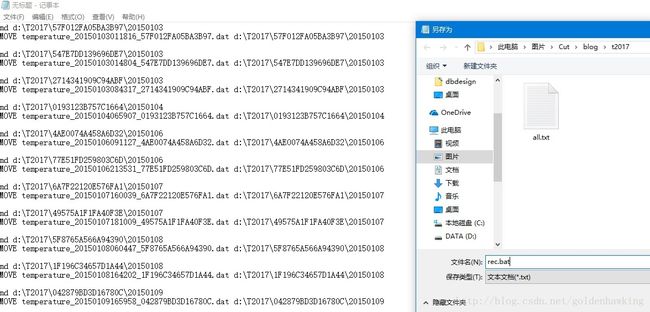
使用字符串操作函数,批量产生批处理命令。
(1)首先,创建文件夹指令
=CONCATENATE("md d:\T2017\",E1,"\",LEFT(C1,8),CHAR(13),CHAR(10))其中,CHAR(13), CHAR(10)表示回车、换行
(2)移动文件指令
=CONCATENATE("MOVE ",A1," d:\T2017\",E1,"\",LEFT(C1,8),CHAR(13),CHAR(10))效果如下:
md d:\T2017\57F012FA05BA3B97\20150103
MOVE temperature_20150103011816_57F012FA05BA3B97.dat d:\T2017\57F012FA05BA3B97\20150103批量复制公式到所有记录,得到20多万条指令:

2.4 执行批处理文件
把生成的指令复制到记事本,另存在原始文件夹下,而后在原始文件夹下执行即可。
结果如下

3 后记
程序猿往往专注于代码,对办公系统的了解程度可能不足。我们公司曾经招聘了一名很厉害的毕业生,写代码的速度和质量很高。但是,为了一个简单的问题,编写一次性的代码、脚本,还是没有搞运维的小伙子用电子表格、Notepad++来的快。
在我们公司,把代码用于上述工作是不受鼓励的。因为编程时,对人的耐心与精力消耗很高,这些精力更应该用在刀刃上。
即便熟练掌握了bash、python等脚本技术,与电子表格、NotePad++等GUI工具相比,实现简单功能耗费的精力完全不同。好的员工除了主干的编程技术,必须要把常用的周边软件掌握好,才能避免纠缠于琐碎的事务无法脱身。