一:实验目的
- 找一个系统调用,系统调用号为学号最后2位相同的系统调用(我的学号最后两位是07)
- 通过汇编指令触发该系统调用
- 通过gdb跟踪该系统调用的内核处理过程
- 重点阅读分析系统调用入口的保存现场、恢复现场和系统调用返回,以及重点关注系统调用过程中内核堆栈状态的变化
二:环境配置
1:安装开发环境
• sudo apt install build-essential
• sudo apt install qemu # install QEMU
• sudo apt install libncurses5-dev bison flex libssl-dev libelf-dev
2:下载内核
• sudo apt install axel • axel -n 20 https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/ linux-5.4.34.tar.xz • xz -d linux-5.4.34.tar.xz • tar -xvf linux-5.4.34.tar • cd linux-5.4.34
3:配置内核编译选项
• make defconfig # Default configuration is based on 'x86_64_defconfig' • make menuconfig • # 打开debug相关选项 • Kernel hacking ---> • Compile-time checks and compiler options ---> • [*] Compile the kernel with debug info • [*] Provide GDB scripts for kernel debugging • [*] Kernel debugging • # 关闭KASLR,否则会导致打断点失败 • Processor type and features ----> • [] Randomize the address of the kernel image (KASLR)

4:制作根文件系统
从https://www.busybox.net下载 busybox源代码解压,解压完成后,跟内核⼀样先配置编译,并安装。
• axel -n 20 https://busybox.net/downloads/busybox-1.31.1.tar.bz2 • tar -jxvf busybox-1.31.1.tar.bz2 • cd busybox-1.31.1 • make menuconfig
• Settings --->
• [*] Build static binary (no shared libs)
• 然后编译安装,默认会安装到源码⽬录下的 _install ⽬录中。
• make -j$(nproc) && make install
• 然后制作内存根⽂件系统镜像,⼤致过程如下:
• mkdir rootfs
• cd rootfs
• cp ../busybox-1.31.1/_install/* ./ -rf
• mkdir dev proc sys home
• sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/
5:创建init脚本文件并打包
• 创建init脚本⽂件放在根⽂件系统跟⽬录下(rootfs/init),添加如下内容到init⽂件。 • #!/bin/sh • mount -t proc none /proc • mount -t sysfs none /sys • echo "Wellcome MengningOS!" • echo "--------------------" • cd home • /bin/sh • 给init脚本添加可执⾏权限 • chmod +x init
• 打包成内存根⽂件系统镜像 • find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../ rootfs.cpio.gz • 测试挂载根⽂件系统,看内核启动完成后是否执⾏init脚本 • qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz
可以看到Wellcome ROS已经显示出来了。

三:系统调用
1:找到对应的系统调用
我的学号最后两位是07,查看syscall_64.tbl文件:
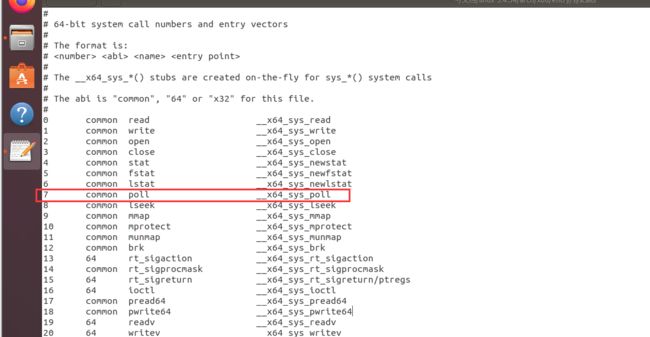
发现7号调用是poll。
2:poll简介
poll的机制与select类似,与select在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。
Linux提供的poll函数接口如下:
#includeint poll(struct pollfd fds[], nfds_t nfds, int timeout); typedef struct pollfd { int fd; // 需要被检测或选择的文件描述符 short events; // 对文件描述符fd上感兴趣的事件 short revents; // 文件描述符fd上当前实际发生的事件*/ } pollfd_t;
poll()函数返回fds集合中就绪的读、写,或出错的描述符数量,返回0表示超时,返回-1表示出错;
fds是一个struct pollfd类型的数组,用于存放需要检测其状态的socket描述符,并且调用poll函数之后fds数组不会被清空;
nfds记录数组fds中描述符的总数量;
timeout是调用poll函数阻塞的超时时间,单位毫秒;
一个pollfd结构体表示一个被监视的文件描述符,通过传递fds[]指示 poll() 监视多个文件描述符。其中,结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域,结构体的revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域。events域中请求的任何事件都可能在revents域中返回。
合法的事件如下:
POLLIN 有数据可读
POLLRDNORM 有普通数据可读
POLLRDBAND 有优先数据可读
POLLPRI 有紧迫数据可读
POLLOUT 写数据不会导致阻塞
POLLWRNORM 写普通数据不会导致阻塞 POLLWRBAND 写优先数据不会导致阻塞 POLLMSGSIGPOLL 消息可用
当需要监听多个事件时,使用POLLIN | POLLRDNORM设置 events 域;当poll调用之后检测某事件是否发生时,fds[i].revents & POLLIN进行判断。
四:编写程序跟踪调试
#includeint main() { asm volatile( "movl $0x07,%eax\n\t" //使⽤EAX传递系统调⽤号07 "syscall\n\t" //触发系统调⽤ );return 0; }
用gcc静态编译,生成可执行文件
gcc -o test test.c -static
将文件放至rootfs/home路径下,重新执行如下两条语句:
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz

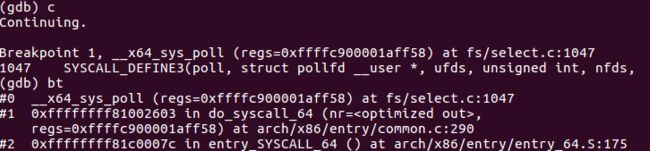
上图中entry_SYSCALL_64()是系统调用的入口,代码如下:
ENTRY(entry_SYSCALL_64_trampoline) ..... movq $entry_SYSCALL_64_stage2, %rdi JMP_NOSPEC %rdi END(entry_SYSCALL_64_trampoline) .popsection ENTRY(entry_SYSCALL_64_stage2) UNWIND_HINT_EMPTY popq %rdi jmp entry_SYSCALL_64_after_hwframe END(entry_SYSCALL_64_stage2) ENTRY(entry_SYSCALL_64) UNWIND_HINT_EMPTY swapgs movq %rsp, PER_CPU_VAR(rsp_scratch) movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp /* Construct struct pt_regs on stack */ pushq $__USER_DS /* pt_regs->ss */ pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */ pushq %r11 /* pt_regs->flags */ pushq $__USER_CS /* pt_regs->cs */ pushq %rcx /* pt_regs->ip */ GLOBAL(entry_SYSCALL_64_after_hwframe) pushq %rax /* pt_regs->orig_ax */ PUSH_AND_CLEAR_REGS rax=$-ENOSYS TRACE_IRQS_OFF /* IRQs are off. */ movq %rax, %rdi movq %rsp, %rsi call do_syscall_64 /* returns with IRQs disabled */ ......... END(entry_SYSCALL_64)
其中删去了很多内容,但是整个思路是:
-
去中断向量表查看中断偏移量(很惭愧,没找到),
-
对应的entry_64.S进行section的调用
-
对于syscall就是调用到了(仅保留了核心)
entry_SYSCALL_64,其中ENTRY(), END(),都是宏用来进符号表中的函数声明
在entry_SYSCALL_64中调用了do_syscall_64(),do_syscall_64()这是一个外部函数,在common.c中的定义
// arch/x86/entry/common.c __visible void do_syscall_64(unsigned long nr, struct pt_regs *regs) { struct thread_info *ti; enter_from_user_mode(); local_irq_enable(); ti = current_thread_info(); if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY) nr = syscall_trace_enter(regs); /* * NB: Native and x32 syscalls are dispatched from the same * table. The only functional difference is the x32 bit in * regs->orig_ax, which changes the behavior of some syscalls. */ nr &= __SYSCALL_MASK; if (likely(nr < NR_syscalls)) { * nr = array_index_nospec(nr, NR_syscalls); * regs->ax = sys_call_table[nr](regs); } syscall_return_slowpath(regs); }
其中标上*的两句就是最重要的,它会去sys_call_table[]全局例程调用表中查找我们想要调用的例程
为什么有这样的机制呢?
因为中断号页只有255,所有的系统调用共享syscall对应的入口,所以我们需要一个数组
在都进入内核态之后,根据每个系统调用的唯一编号来进行唯一标识与识别
这个编号的确定,是有各种各样的宏确定的,同时要保证LinuxKernel与glibc的编号一致,
我们可以来看这两个文件
// /usr/include/asm/unistd_64.h #ifndef _ASM_X86_UNISTD_64_H #define _ASM_X86_UNISTD_64_H 1 #define __NR_read 0 #define __NR_write 1 #define __NR_open 2 #define __NR_close 3 #define __NR_stat 4 #define __NR_fstat 5 #define __NR_lstat 6 #define __NR_poll 7 #define __NR_lseek 8 #define __NR_mmap 9 #define __NR_mprotect 10 #define __NR_munmap 11 #define __NR_brk 12 #define __NR_rt_sigaction 13 #define __NR_rt_sigprocmask 14 #define __NR_rt_sigreturn 15 #define __NR_ioctl 16 #define __NR_pread64 17 ......... // ....
确定好编号后,就可以访问指定函数的地址了